파이썬 기반 크롤러
- 1. 크롤링(Crawling)의 개념과 기술적 특징
- 2. 크롤링 기술의 장단점 및 활용 사례
- 3. 라이선스 및 법적 주의점 (Compliance)
- 4. 최근 업계의 반응 및 기술적 대응 트렌드
- 5. 크롤러의 구조 이해
- 6. 실습 예제
1. 크롤링(Crawling)의 개념과 기술적 특징
1.1 개념 정의
- 웹 크롤링(Web Crawling)
- 조직적, 자동화된 방법으로 웹 페이지를 탐색하며 링크를 수집하고 색인(Indexing)하는 과정
- 예: 구글 봇의 웹 페이지 순회
- 웹 스크래핑(Web Scraping)
- 특정 웹 페이지에서 우리가 원하는 특정 데이터(가격, 제목, 이미지 등)를 추출하여 구조화된 데이터로 저장하는 기법
1.2 주요 기술 스택 분류
- 정적 페이지 데이터 추출 (HTTP 통신)
requests,urllib- 서버에 HTTP Request를 보내고 HTML 소스를 응답받는 라이브러리
BeautifulSoup- 받아온 HTML 문자열을 파싱(Parsing)하여 DOM 트리 구조로 변환, 데이터 추출을 용이하게 해주는 라이브러리
- 동적 페이지 및 SPA(Single Page Application) 대응
Selenium,Playwright- 브라우저를 직접 원격 제어하여 JavaScript 렌더링, 클릭, 스크롤 등의 사용자 상호작용을 시뮬레이션하는 라이브러리
2. 크롤링 기술의 장단점 및 활용 사례
- 장점
- 데이터 확보의 무한성: 공개된 웹의 방대한 데이터를 자산화할 수 있음
- 자동화 및 효율성: 수작업으로 수일이 걸릴 데이터 수집을 수분 내에 완료
- 실시간성: 주기적인 스크래핑을 통해 시장의 실시간 변화를 모니터링할 수 있음
- 단점 및 한계
- 대상 사이트 의존성 : 타겟 웹사이트의 UI/UX나 HTML 구조가 조금만 바뀌어도 크롤러가 작동하지 않음 🡲 유지보수 비용 발생
- 차단 및 제재 위험 : 짧은 시간 내 많은 요청을 보내면 IP가 차단되거나 디도스(DDoS) 공격으로 오인받을 수 있음
- 비정형 데이터 처리의 난해함 : HTML 내 텍스트 뒤섞임, 숨겨진 데이터 등을 정제하는 데 많은 리소스가 소요됨
- 주요 활용 사례
- 이커머스 : 경쟁사 상품 가격 비교 및 최저가 모니터링 시스템 구축
- 금융/주식 : 뉴스 키워드 감성 분석 및 기업 공시 정보 자동 수집을 통한 투자 분석
- 제조/스마트팩토리 : 공급망 부품 가격 변동성 추적 및 원자재 시장 동향 리포트 자동화
- AI/데이터 과학 : 거대 언어 모델(LLM) 학습용 말뭉치 및 파인튜닝 데이터셋 확보
3. 라이선스 및 법적 주의점 (Compliance)
⚠️ 과거와 달리 현재는 무분별한 크롤링에 대한 법적 처벌 사례가 늘고 있음
robots.txt확인 (필수)- 웹사이트 루트 경로(예:
https://example.com/robots.txt)에 위치한 로봇 배제 표준을 반드시 확인하고 준수해야 함
- 웹사이트 루트 경로(예:
- 서비스 이용약관(Terms of Service) 위반 여부
- 로그인이 필요한 서비스(Gated Data)의 경우,
- 로그인 시 동의한 약관에 “자동화된 수단 이용 금지” 조항이 있다면 민사상 손해배상 청구 대상이 될 수 있음
- 로그인이 필요한 서비스(Gated Data)의 경우,
- 저작권법 및 정보통신망법 유의
- 단순한 ‘사실(Facts, 예: 상품 가격, 수치)’은 저작권 보호 대상이 아니지만, 타인이 가공한 ‘창작성 있는 저작물(리뷰 글, 기사, 독창적 이미지 등)’을 무단으로 긁어가서 상업적으로 재배포하면 저작권 침해에 해당함
- 서버에 무리를 주어 서비스를 마비시키면 정보통신망법 위반(컴퓨터장애업무방해)으로 형사 처벌을 받을 수 있음
- 개인정보보호법(개인식별정보 PII)
- 공개된 정보라 할지라도 이름, 전화번호, 이메일 주소 등을 대량으로 긁어 모으는 행위는 국내 개인정보보호법 및 글로벌 standard(GDPR, CCPA)에 전면 위반됨
4. 최근 업계의 반응 및 기술적 대응 트렌드
- 웹사이트 측의 방어 (Anti-Scraping) 고도화
- Cloudflare / Akamai 등 보안 솔루션
- 단순 IP 차단을 넘어 브라우저 핑거프린팅, 행동 패턴 분석을 통해 봇(Bot)을 실시간 차단
- AI 기반 CAPTCHA
- 사람이 아닌 것으로 의심되면 한 차원 높은 캡차(CAPTCHA)를 요구
ai.txt및llms.txt등장- 최근 생성형 AI 붐으로 인해, 기존
robots.txt를 넘어 “AI 모델 학습용 데이터 수집(TDM)을 거부한다”는 목적 기반 제어(Purpose-Based Control) 규격이 업계 표준으로 자리 잡고 있음
- 최근 생성형 AI 붐으로 인해, 기존
- Cloudflare / Akamai 등 보안 솔루션
- 크롤러 측의 진화 (Harness & Agentic Loop)
- 헤드리스 브라우저의 고도화
Playwright등을 활용해 완벽하게 인간의 마우스 움직임과 스크롤 속도를 흉내 내는 방식이 주류를 이루고 있음
- LLM 연동 스크래핑
- 과거에는 정규식이나 CSS Selector를 꼼꼼히 짜야 했지만,
- 최근에는 HTML 통째로 혹은 텍스트 스냅샷을 LLM 지시어(Prompt)에 넣어 원하는 정보만 JSON 구조로 뽑아내는 ‘에이전트형 스크래핑(Agentic Scraping)’으로 패러다임 이동 중
- 헤드리스 브라우저의 고도화
5. 크롤러의 구조 이해
- 🌐 크롤러 아키텍처 흐름도 (숫자 순서 기준)
- SEED URLs와 Frontier Queue
- 시작점 (SEED URLs)
- 크롤러는 인터넷을 무작정 떠도는 것이 아님
- 탐색을 시작할 최소한의 ‘기초 주소 리스트(Seed URLs)’를 입력받는 것부터 시작
- 스케줄러/큐 (Frontier Queue)
- 방문할 예정인 URL들을 차례대로 쌓아두는 대기열(Queue)
- 크롤러는 이 큐에서 주소를 하나씩 꺼내어 탐색을 수행하고,
- 탐색 중에 새로 발견된 링크들을 다시 이 큐에 추가하며 무한히 확장함
- 시작점 (SEED URLs)
- HTTP GET REQUEST (요청)
- 대기열(Frontier Queue)에서 꺼내온 타겟 URL을 기반으로,
- 크롤러(Bot)가 인터넷망을 통해 대상 웹사이트(Target Website) 서버에 접속하여
- 페이지 소스코드를 요청하는 단계
- HTTP RESPONSE (응답)
- 요청을 받은 웹 서버가
- 크롤러에게 웹페이지의 뼈대가 되는 순수한 HTML 소스코드를 반환(응답)하는 단계
- Page Loop 🡲 Page Calculation (페이지 제어 및 파싱 준비)
- 서버로부터 받은 HTML 원본 데이터를
- PAGE PARSER (BeautifulSoup 등) 엔진에 전달하여
- 메모리에 DOM 트리 구조로 변환하는 단계
- 다중 페이지를 크롤링할 경우, 다음 요청을 위한 페이징 파라미터 계산이 이 시점에서 제어됨
- EXTRACT DATA (특정 데이터 추출 - 스크래핑)
- 파서가 해석한 HTML 구조 안에서
- 우리가 진짜 목표로 하는 알맹이 정보(기사 제목, 본문, 가격, 이미지 주소 등)만 골라내어
- 구조화된 데이터(JSON, Dictionary 등)로 추출하는 단계
- Item Loop 🡲 Check for Elements & Error Handling (아이템 검증)
- 추출된 데이터나 HTML 내부에
- 반복할 뉴스 기사 목록(요소)이 실제로 존재하는지 검증하는 단계
- 만약 요소가 없다면(
True → BREAK)- 구조가 개편되었거나 차단된 것으로 판단하여
- 예외 처리(
Error Handling) 루틴을 실행
- LINK QUEUE (새로운 링크 발견 - 크롤링)
- 현재 페이지 내에 존재하는 또 다른 하이퍼링크들(
<a href="...">)을 - 파서가 모두 찾아내어 수집하는 단계
- 이 단계가 크롤러가 스스로 탐색 범위를 넓혀가게 만드는 원동력
- 현재 페이지 내에 존재하는 또 다른 하이퍼링크들(
- FRONTIER QUEUE (스케줄러 대기열 등록)
- 6단계에서 새로 발견된 다음 타겟 URL들을 스케줄러 대기열(
Frontier Queue) 끝에 추가하는 단계 - 이 큐에 쌓인 주소들은 다시 1번(HTTP GET REQUEST)의 출발점으로 순환 피딩됨
- 6단계에서 새로 발견된 다음 타겟 URL들을 스케줄러 대기열(
- STORE RESULTS (데이터 저장)
- 4단계에서 추출되고 5단계 검증을 거친 최종 순수 데이터들을
- 파일(
news_data.json, CSV)이나 데이터베이스(Database/Index)에 최종적으로 영구 저장하며 - 한 주기의 프로세스를 마치는 단계
- Politeness / robots.txt
- 대기열(Frontier Queue)에서 다음 URL을 꺼내 요청을 보낼 때,
- 대상 사이트의 무리를 주지 않기 위해
Delay(time.sleep)를 주고,- 해당 서버의 수집 거부 규약인
robots.txt를 확인하여 스케줄러를 제어해야 함
- 웹 크롤링과 웹 스크래핑의 차이
- 웹 크롤링(Web Crawling)
- 그림의 전체적인 순환 루프(
1번(요청) → 2번(응답) → 3번(파싱) → 6번(링크발견) → 7번(큐등록) → 다시 1번) 자체를 의미함- 끊임없이 링크를 발견하고 탐색 체인을 이어 나가는 ‘무한한 웹 순회 기술’
- 웹 스크래핑(Web Scraping)
3번(파서) → 4번(추출) → 5번(검증) → 8번(저장)으로 이어지는 단방향 흐름을 의미함- 특정 페이지에서 원하는 특정 데이터만 도려내어 저장하는 ‘데이터 추출 기술’(특정 데이터 타겟팅 및 자산화 과정)
6. 실습 예제
사전 준비 (터미널 설치 명령어)
# 가상환경 생성 및 활성화 python -m venv crawler cd crawler source ./bin/activate # 필요 라이브러리 설치 pip install requests beautifulsoup4
5.1 네이버 뉴스 검색 결과 수집
- 실습 코드
- 기존에 잘 작동하고 있었으나 보안정책, 페이지 구성, 구성요소 변경 등으로 실패한 사례
#//file: "naver_news_scraper_1.py" import sys import time import requests from bs4 import BeautifulSoup def scrape_naver_news(search_keyword, max_pages=2): """네이버 뉴스에서 키워드를 검색하여 제목과 링크를 수집하는 함수 :param search_keyword: 검색할 키워드 (str) :param max_pages: 수집할 페이지 수 (int) """ print(f"[{search_keyword}] 관련 뉴스 수집을 시작합니다. (최대 {max_pages}페이지)") print("-" * 60) # 1. 크롤링 시 차단을 방지하기 위한 필수 헤더(User-Agent) 설정 headers = { "User-Agent": ( "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/120.0.0.0 Safari/537.36" ) } results_count = 0 for page in range(max_pages): # 네이버 뉴스 검색 페이징 공식: 1페이지(start=1), 2페이지(start=11), 3페이지(start=21) ... start_val = page * 10 + 1 url = f"https://search.naver.com/search.naver?where=news&query={search_keyword}&start={start_val}" try: # 2. HTTP GET 요청 보냄 response = requests.get(url, headers=headers, timeout=5) # 응답 상태 코드가 200(정상)이 아니면 예외 발생 response.raise_for_status() except requests.exceptions.RequestException as e: print(f"[에러] 페이지 요청 중 문제가 발생했습니다: {e}") break # 3. HTML 파싱 soup = BeautifulSoup(response.text, "html.parser") # 4. 뉴스 기사 블록 요소 선택 (네이버 검색 개편 후 기준 최신 Selector 기재) # 각 뉴스 기사 카드는 'bx' 클래스를 가진 'li' 태그 내에 존재함 news_items = soup.select("ul.list_news > li.bx") if not news_items: print(f"{page+1}페이지에서 검색 결과 요소를 찾을 수 없습니다. 구조 변경을 확인하세요.") break print(f"[진행] {page+1} 페이지 수집 중...") for item in news_items: # 뉴스 제목과 링크가 있는 <a> 태그 선택 (news_tit 클래스) title_element = item.select_one("a.news_tit") if title_element: title = title_element.get_text(strip=True) link = title_element["href"] results_count += 1 print(f"{results_count}. {title}") print(f" 링크: {link}") # 5. 과도한 트래픽 유발 방지를 위한 정중한 매너 (Politeness Delay) # 서버에 부담을 주지 않기 위해 페이지 전환 시 1.5초간 대기 time.sleep(1.5) print("-" * 60) print(f"수집 완료: 총 {results_count}개의 뉴스 데이터를 안전하게 수집했습니다.") if __name__ == "__main__": # 인코딩 문제 방지 (윈도우 환경 대응) if sys.platform == "win32": import io sys.stdout = io.TextIOWrapper(sys.stdout.detach(), encoding="utf-8") # 실습 키워드 설정 (예: AI 기술) keyword = "인공지능 트렌드" scrape_naver_news(keyword, max_pages=2)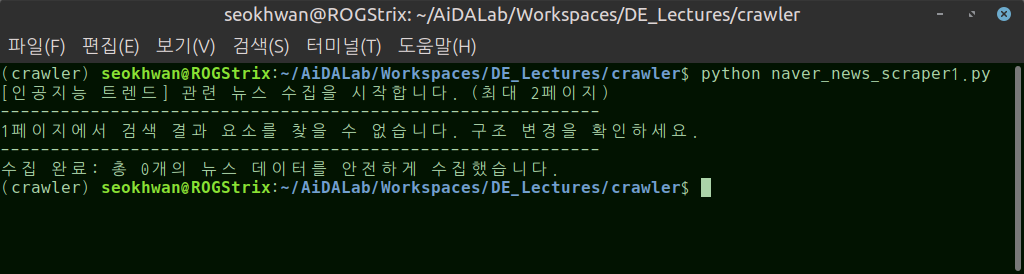
- 약 10번의 코드, 구조 변경 후 찾아낸 수정코드
#//file: "naver_news_scraper_2.py" import sys import time from bs4 import BeautifulSoup from selenium import webdriver from selenium.webdriver.chrome.options import Options def scrape_naver_news_absolute(search_keyword): print(f"🚀 [구조 격파 가동] '{search_keyword}' 뉴스 수집을 시작합니다.") print("-" * 60) chrome_options = Options() # Headless 모드 해제 (실제 브라우저 구동으로 보안 통과) chrome_options.add_argument("--no-sandbox") chrome_options.add_argument("--disable-dev-shm-usage") # 자동화 봇 감지 바 숨기기 chrome_options.add_experimental_option( "excludeSwitches", ["enable-automation"] ) chrome_options.add_experimental_option("useAutomationExtension", False) driver = webdriver.Chrome(options=chrome_options) # navigator.webdriver 변수 조작 (보안 솔루션 우회) driver.execute_cdp_cmd( "Page.addScriptToEvaluateOnNewDocument", { "source": "Object.defineProperty(navigator, 'webdriver', {get: () => undefined})" }, ) try: # 뉴스 탭 주소로 진입 url = f"https://search.naver.com/search.naver?where=news&query={search_keyword}" driver.get(url) # 화면에 뉴스 데이터가 바인딩될 때까지 3.5초간 충분히 대기 time.sleep(3.5) # 브라우저가 완성한 최종 가상 DOM 소스 확보 final_html = driver.page_source soup = BeautifulSoup(final_html, "html.parser") # [⭐ 핵심 수정: 클래스명 의존성 100% 제거] # 클래스명(news_tit 등)이 네이버 패치로 바뀌어도, '뉴스 기사 링크'라는 본질은 변하지 않습니다. # href 주소에 일반 언론사나 네이버 뉴스 포맷이 들어간 모든 <a> 태그를 포괄적으로 수집합니다. all_links = soup.find_all("a") news_results = [] for link_element in all_links: href = link_element.get("href", "") title = link_element.get_text(strip=True) # 네이버 뉴스 검색 결과 링크들의 공통적인 URL 패턴 및 글자 수 필터링 # 보통 제목 링크는 언론사 도메인이거나 네이버 뉴스 링크이며, 제목 텍스트가 10자 이상으로 깁니다. if ( "sp_nws" in href or "news.naver.com" in href or "sid=" in href or "article" in href ) and len(title) > 10: # 중복 수집 방지 및 무효 데이터 제거 if ( "네이버뉴스" not in title and {"title": title, "link": href} not in news_results ): news_results.append({"title": title, "link": href}) if not news_results: print( "⚠️ 브라우저 화면은 떴으나 데이터 추출 패턴이 일치하지 않습니다." ) return print(f"[성공] 화면 렌더링 검증 완료. 데이터를 출력합니다.\n") for index, res in enumerate(news_results, start=1): print(f"{index}. {res['title']}") print(f" 🔗 링크: {res['link']}") except Exception as e: print(f"❌ 에러 발생: {e}") finally: # 강사님이 결과를 눈으로 편하게 확인하실 수 있도록 5초간 창을 유지한 뒤 닫습니다. time.sleep(5) driver.quit() if __name__ == "__main__": if sys.platform == "win32": import io sys.stdout = io.TextIOWrapper(sys.stdout.detach(), encoding="utf-8") keyword = "인공지능 트렌드" scrape_naver_news_absolute(keyword)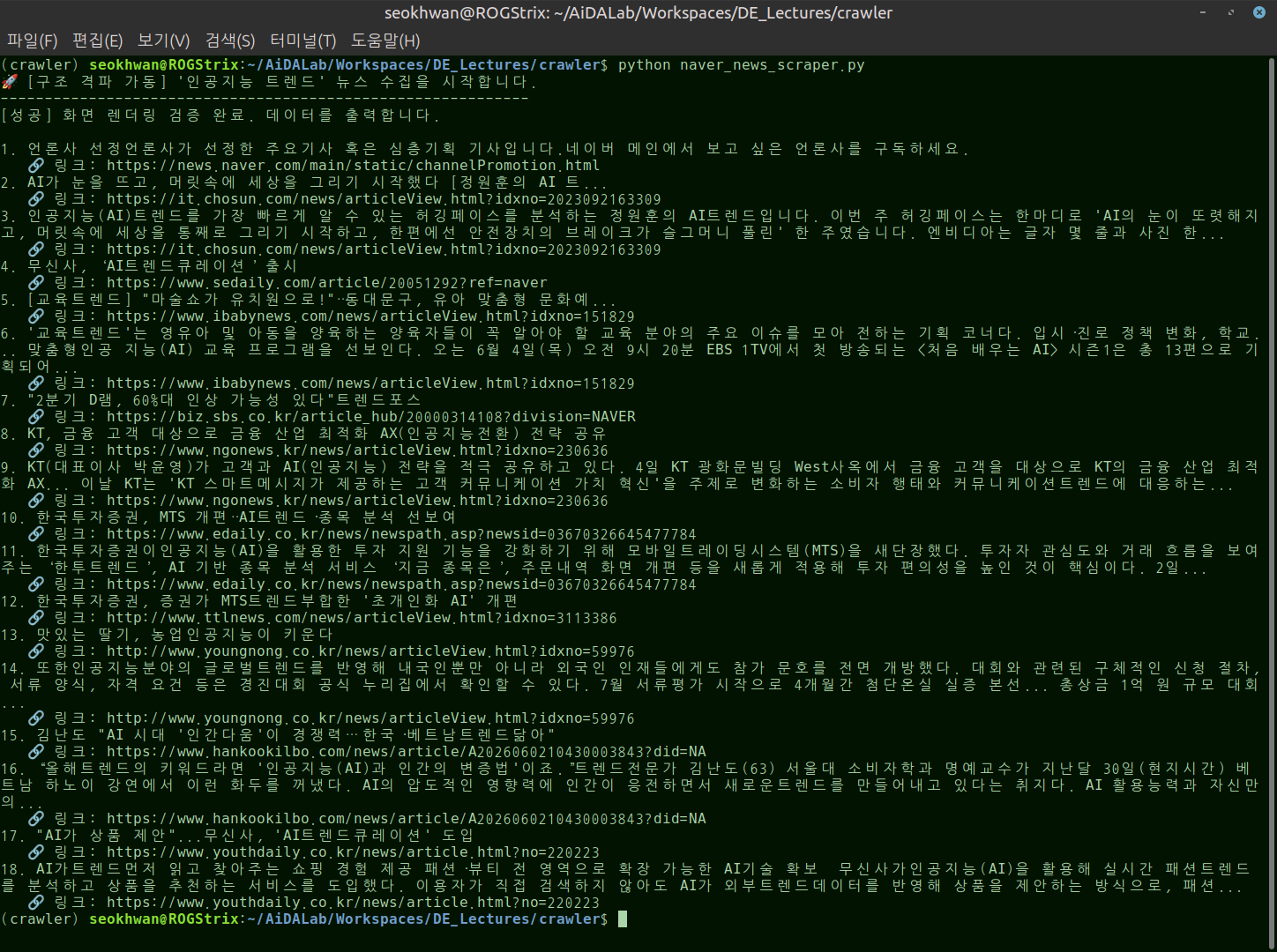
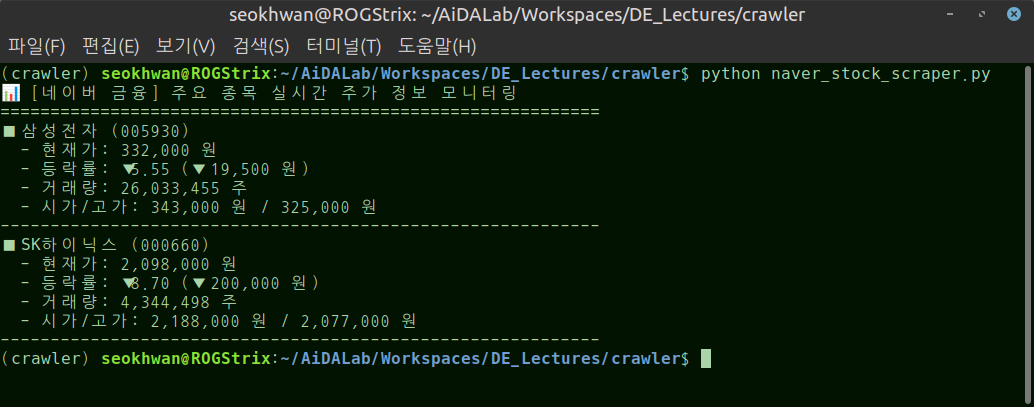
5.2 네이버 페이증권 기반 주가 정보 획득
네이버 페이 증권 페이지에서 특정 종목의 현재가, 변동 수치, 거래량 등의 주가 정보를 실시간으로 읽어오기
사전 준비
pip install requests beautifulsoup4실습 코드 (
naver_stock_scraper.py)#//file: "naver_stock_scraper.py" import sys import time import requests from bs4 import BeautifulSoup def get_naver_stock_info(company_code): """네이버 금융에서 특정 종목의 현재 주가 정보를 가져오는 함수 :param company_code: 6자리 종목 코드 (str) """ # 1. 대상 URL 설정 (네이버 금융 개별 종목 홈) url = f"https://finance.naver.com/item/main.naver?code={company_code}" # 2. 크롤링 차단 방지를 위한 브라우저 헤더 설정 headers = { "User-Agent": ( "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/120.0.0.0 Safari/537.36" ) } try: # HTTP GET 요청 및 예외 처리 response = requests.get(url, headers=headers, timeout=5) response.raise_for_status() except requests.exceptions.RequestException as e: print(f"📢 [네트워크 에러] 데이터 요청 실패: {e}") return None # 3. HTML 파싱 (BeautifulSoup 객체 생성) soup = BeautifulSoup(response.text, "html.parser") # 4. 주가 정보 영역 데이터 추출 (wrap_company 클래스 및 today 클래스 타겟) # 종목명 추출 wrap_company = soup.select_one(".wrap_company") if not wrap_company: print( f"⚠️ 종목 코드를 확인해 주세요. ({company_code} 데이터를 찾을 수 없습니다.)" ) return None company_name = wrap_company.select_one("h2 > a").get_text(strip=True) # 실시간 주가 정보 테이블 탐색 (.no_today 영역) no_today = soup.select_one(".no_today") if not no_today: print("⚠️ 주가 데이터 레이아웃을 분석할 수 없습니다.") return None # 현재가 추출 (blind 클래스 내 텍스트 활용) current_price = no_today.select_one(".blind").get_text(strip=True) # 전일대비 및 등락률 영역 탐색 (.no_exday 영역) no_exday = soup.select_one(".no_exday") # 상승, 하락 여부를 아이콘 텍스트로 판별 ico_direction = no_exday.select_one(".ico").get_text(strip=True) # 변동 금액과 등락률 (blind 클래스 안의 텍스트 추출) blinds = no_exday.select(".blind") change_amount = blinds[0].get_text(strip=True) if len(blinds) > 0 else "0" change_rate = blinds[1].get_text(strip=True) if len(blinds) > 1 else "0%" # 기호 가독성 처리 if "상승" in ico_direction or "상한" in ico_direction: direction_sign = "▲" elif "하락" in ico_direction or "하한" in ico_direction: direction_sign = "▼" else: direction_sign = "" # 5. 거래량 및 시가/고가/저가 추가 정보 추출 (실무 데이터 다각화용) # .no_info 테이블 내부의 blind 값을 순서대로 매핑 no_info = soup.select_one(".no_info") info_blinds = no_info.select(".blind") if no_info else [] prev_close = info_blinds[0].get_text(strip=True) if len(info_blinds) > 0 else "-" # 전일 market_open = info_blinds[1].get_text(strip=True) if len(info_blinds) > 1 else "-" # 시가 high_price = info_blinds[5].get_text(strip=True) if len(info_blinds) > 5 else "-" # 고가 volume = info_blinds[3].get_text(strip=True) if len(info_blinds) > 3 else "-" # 거래량 # 결과 데이터 구조화 (딕셔너리 반환) stock_data = { "종목명": company_name, "종목코드": company_code, "현재가": current_price, "전일대비": f"{direction_sign} {change_amount}", "등락률": f"{direction_sign}{change_rate}", "거래량": volume, "시가": market_open, "고가": high_price, "전일종가": prev_close, } return stock_data if __name__ == "__main__": # 윈도우 환경 콘솔 출력 인코딩 방어 코드 if sys.platform == "win32": import io sys.stdout = io.TextIOWrapper(sys.stdout.detach(), encoding="utf-8") # 실습용 타겟 종목 정의 (삼성전자: 005930, SK하이닉스: 000660) target_stocks = ["005930", "000660"] print("📊 [네이버 금융] 주요 종목 실시간 주가 정보 모니터링") print("=" * 60) for code in target_stocks: data = get_naver_stock_info(code) if data: print(f"■ {data['종목명']} ({data['종목코드']})") print(f" - 현재가: {data['현재가']} 원") print(f" - 등락률: {data['등락률']} ({data['전일대비']} 원)") print(f" - 거래량: {data['거래량']} 주") print( f" - 시가/고가: {data['시가']} 원 / {data['고가']} 원" ) print("-" * 60) # 연속 요청 시 매너 필터 (서버 과부하 방지) time.sleep(1.0)