Database 개요
1. 데이터(Data)
- 정의: 현실 세계에서 관찰되거나 측정된 사실이나 값(Fact)
- 현대 정보 사회의 가장 가치 있는 원자재이자, 모든 의사결정과 시스템의 기반이 되는 핵심 자산
- 특징
- 단독으로 존재할 때는 단순한 수치나 문자에 불과하여 큰 의미를 갖지 못함
- 특정 목적에 맞게 가공되고 문맥(Context)이 부여되면 비로소 가치 있는 ‘정보(Information)’로 전환됨
- 예시
- 데이터 (Data): 38 (단순한 숫자)
- 정보 (Information): “오늘 서울의 최고 기온은 38°C이다.” (의미가 부여된 데이터)
- 예시
- 데이터의 분류
- 형태 및 구조화 수준에 따른 분류
- 데이터가 얼마나 일정한 규칙과 틀을 가지고 저장되어 있는지에 따라 구분됨
이 분류에 따라 어떤 DBMS(MySQL인지, MongoDB인지)를 사용할지를 결정함
- 정형 데이터 (Structured Data)
- 정의: 고정된 필드(틀)에 정해진 형식으로 저장된 데이터
- 특징:
- 연산과 검색이 매우 빠름
- 주로 관계형 데이터베이스(RDBMS)의 표(Table) 형태로 관리됨
- 예시: 이름, 나이, 결제 금액, 날짜, 주소록 등
- 반정형 데이터 (Semi-structured Data)
- 정의: 고정된 틀은 없지만, 데이터 내에 구조를 설명하는 메타데이터나 태그(Tag)가 포함된 데이터
- 특징
- 스키마(틀) 변경이 자유로움
- 파일 형태로 교환하기 쉬움
- 예시: JSON, XML, HTML 파일, 설정 파일 등
- 비정형 데이터 (Unstructured Data)
- 정의: 형태가 전혀 정해져 있지 않고, 규칙성이 없는 데이터
- 특징
- 텍스트나 바이너리 형태로 존재
- 형태가 다양해 일반적인 테이블 구조에 담을 수 없음
- NoSQL이나 데이터 레이크(Data Lake)에 저장
- 예시: 이미지, 영상, 오디오 파일, SNS 게시글 원문, 이메일 내용 등
- 속성과 측정 기준에 따른 분류 (통계 및 분석 기준)
- 데이터가 나타내는 값의 성격에 따라 질적 데이터(정성적 데이터)와 양적 데이터(정량적 데이터)로 나뉨
- 이는 주로 SQL로 통계 및 분석 쿼리를 작성할 때 집계 방식을 결정하는 기준이 됨
- 질적 데이터 \(\approx\) 정성적 데이터 (숫자가 아닌 성질이나 상태를 나타냄)
- 양적 데이터 \(\approx\) 정량적 데이터 (숫자로 크기나 양을 나타냄)
- 질적(Qualitative) 데이터 vs 양적(Quantitative) 데이터
- 주로 ‘통계학’과 ‘데이터베이스(DB)’ 분야에서 데이터를 분류할 때 쓰는 표현
- 데이터의 ‘형태’가 숫자인가, 아닌가에 초점이 맞춰져 있음
- 질적 데이터
- 데이터의 성질이나 종류를 나타냄
- 숫자로 표기하더라도(예: 남자 1, 여자 2) 더하기나 빼기 같은 산술 연산이 불가능
- 예시: 혈액형(A, B, O, AB), 거주지역(서울, 부산), 만족도(상, 중, 하)
- 양적 데이터
- 양이나 크기를 나타냄
- 숫자로 표현되고 산술 연산이 의미가 있음
- 예시: 나이, 매출액, 조회수, 몸무게
분류 정의 특징 예시 질적 데이터
(Qualitative / 범주형)숫자로 표현할 수 없거나, 숫자로 표현해도 크기 비교가 불가능한 데이터 주로 분류나 그룹화를 할 때 사용함 (GROUP BY 대상) 성별(남/여), 혈액형, 상품 카테고리, 거주 지역 양적 데이터
(Quantitative / 수치형)숫자로 표현되며, 더하기·빼기 등 산술 연산이 의미가 있는 데이터 평균, 합계 등 통계량을 낼 때 사용함 (집계 함수 대상) 매출액, 회원 수, 방문 횟수, 기온, 몸무게 - 정성적(Qualitative) 데이터 vs 정량적(Quantitative) 데이터
- 주로 ‘비즈니스 분석’, ‘연구 방법론(설문/인터뷰)’, ‘기획’ 분야에서 데이터의 성격을 말할 때 쓰는 표현
- 데이터가 ‘수치화(측정)하기 쉬운가, 주관적인가’에 초점이 맞춰져 있음
- 정성적 데이터
- 수치로 쉽게 바꾸기 힘든 주관적인 경험, 감정, 생각, 맥락 등을 담은 데이터
- 연구자의 해석이 중요하게 작용함
- 예시: 고객의 심층 인터뷰 녹취록, 제품 사용 후기 원문, 사용자의 행동 관찰 일지
- 정량적 데이터
- 명확하게 자로 재거나 셀 수 있어서, 객관적으로 수치화된 데이터
- 예시: 설문조사의 5점 만점 점수, 웹사이트 이탈률, 월별 매출액
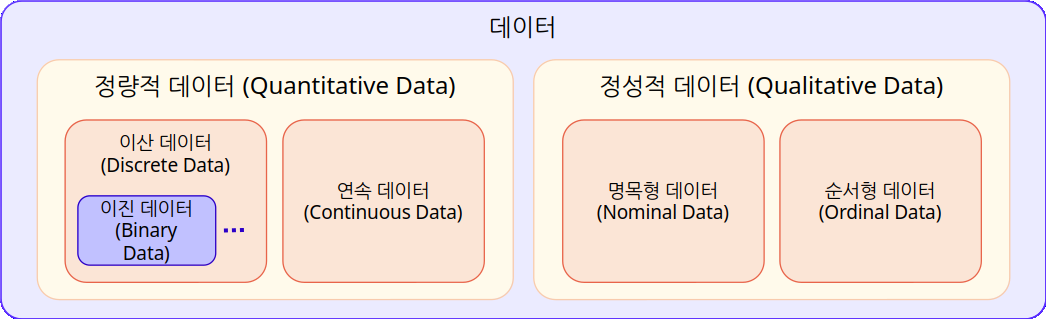
- 관계 및 구조에 따른 분류 (테이블형, 그래프 기반)
데이터가 서로 어떻게 연결되어 있고, 어떤 형태로 시각화·저장되는지에 따른 분류
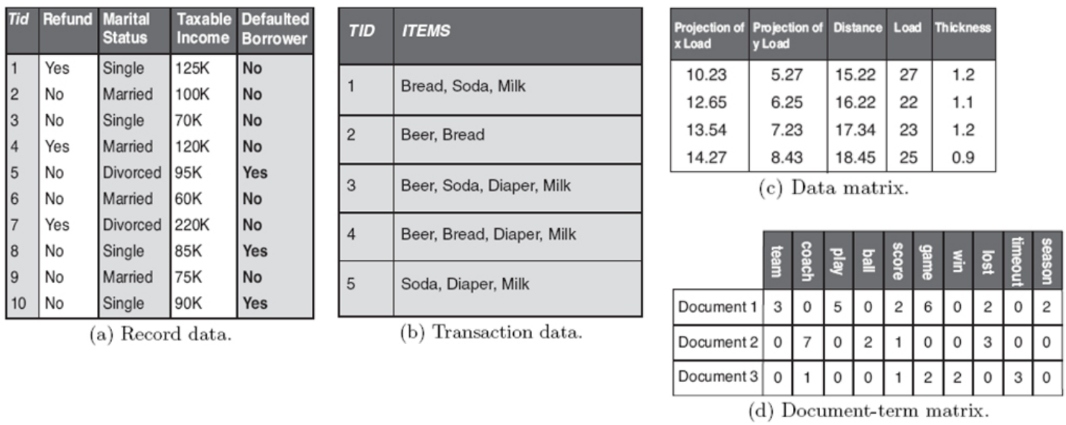
- 테이블형 데이터 (Tabular Data)
- 특징
- 데이터를 격자 모양의 표(행과 열) 형태로 표현
- 가장 전통적이고 대중적인 구조
- 연결 고리
- 구조화 수준으로 보면 완벽한 정형 데이터에 속함
- MySQL 같은 관계형 데이터베이스(RDBMS)에 저장됨
- 예시: 엑셀 시트, 대학교 학생 명부, 가입자 정보 테이블
- 특징
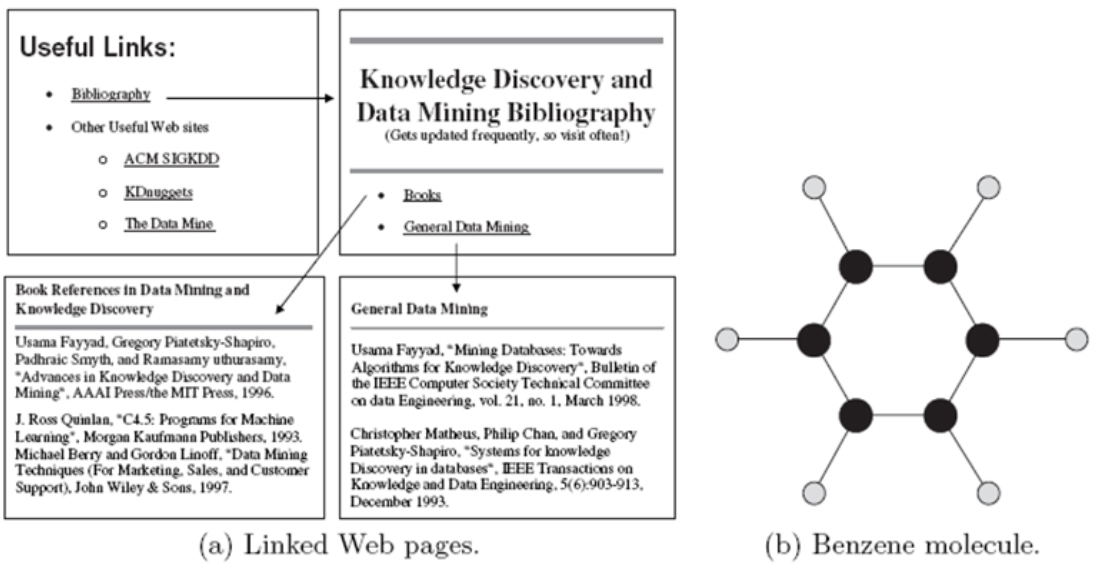
- 그래프 기반 데이터 (Graph-based Data)
- 특징
- 데이터 개체들을 점(Node)으로, 개체 간의 관계를 선(Edge)으로 연결하여 표현하는 구조
- 데이터 간의 연관 관계를 추적하는 데 최적화되어 있음
- 연결 고리
- 데이터 구조의 유연성이 높아 반정형 혹은 비정형 데이터의 성격을 가짐
- Neo4j 같은 그래프 데이터베이스(Graph DB)에 저장됨
- 예시: 페이스북의 친구 관계도, 내비게이션의 도로망(지도) 데이터, 웹 페이지의 링크 구조
- 특징
- 순서 및 시간에 따른 분류 (순서형, 시계열)
데이터에 ‘순차적인 흐름이나 시간의 개념’이 포함되어 있는지에 따른 분류
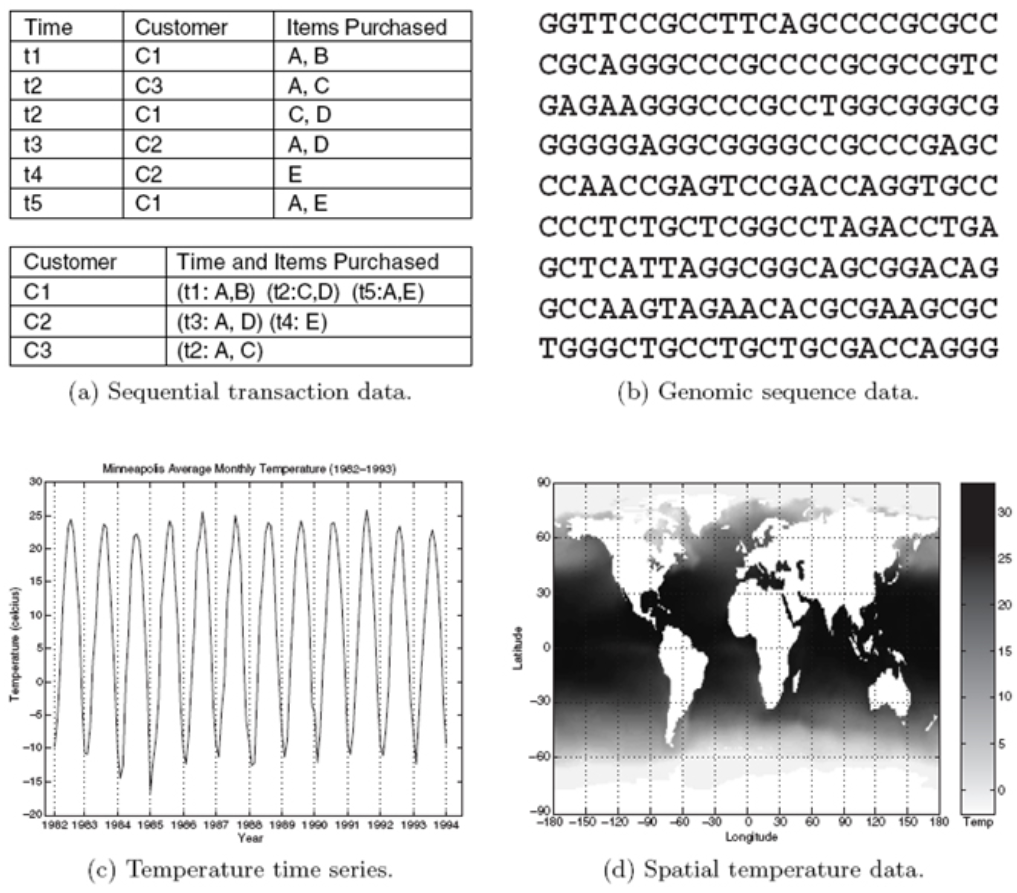
- 순서형 데이터 (Sequential Data)
- 특징
- 데이터의 ‘앞뒤 순서(Sequence)’가 결과에 결정적인 영향을 미치는 데이터
- 시간축이 명확하지 않더라도 사건의 발생 순서 자체가 중요함
- 연결 고리
- 텍스트나 자연어는 문맥(순서)이 중요하므로 비정형 데이터인 경우가 많음
- AI 모델(RNN, Transformer)에서 깊게 다룸
- 예시: 문장 속 단어들의 배열(자연어), DNA 염기서열, 웹사이트 방문자의 클릭 경로(Clickstream)
- 특징
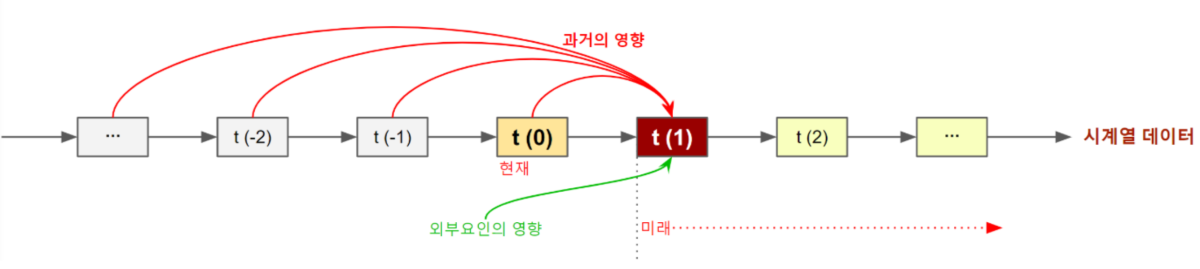
- 시계열 데이터 (Time-Series Data)
- 특징
- ‘일정한 시간 간격’에 따라 순차적으로 기록된 데이터
- 과거의 패턴을 통해 미래를 예측하는 분석에 주로 사용됨
- 연결 고리
- 시간, 센서값 등이 고정된 필드로 들어오면 정형 데이터가 됨
- 무수히 쏟아지는 로그 형태면 반정형 데이터가 됨
- 전용 저장소(InfluxDB, TimescaleDB)를 쓰기도 함
- 예시: 주식 가격 변동 그래프, 1시간 간격의 기온 데이터, 서버의 CPU 사용량 모니터링 로그
- 특징
- 데이터의 근원에 따른 분류
- 데이터가 생성되는 원천(Source)의 특성과 “한 번 생성된 데이터를 원래 상태로 되돌리거나 유추할 수 있는가”에 초점을 맞춘 엔지니어링 및 보안 중심의 분류 방식
- 데이터 수집과정은 데이터의 재생산 과정에 따름
특히 시스템 아키텍처를 설계하거나, 데이터 비식별화(보안), 그리고 데이터 압축/복원 시나리오에서 매우 중요하게 다뤄지는 개념
- 가역 데이터 (Reversible Data)
- 특정 가공이나 변환을 거친 후에도, 반대 연산이나 복원 알고리즘을 통해 원래의 원본 데이터로 100% 완벽하게 되돌릴 수 있는 데이터
- 생산된 데이터의 원본으로 일정 수준 환원이 가능한 데이터
- 특징
- 데이터의 손실이 없어야 하므로 엄격한 규칙성을 가짐
- 정보의 완벽한 보존이 최우선일 때 사용됨
- 원본과 1:1 대응 관계 🡲 환원 가능 🡲 이력추적 가능 🡲 원본 데이터가 변경되는 경우 변경사항 반영 가능
- 주요 예시 및 활용 분야
- 무손실 압축 파일
- .zip, .png, .flac 파일 등은 용량을 줄였다가 다시 압축을 풀면 단 1비트의 오차도 없이 원본으로 복원됨
- 양방향 암호화
- 데이터베이스에 저장된 사용자의 개인정보(예: 주민등록번호, 계좌번호)를 암호화 알고리즘(AES 등)으로 숨겼다가, 권한이 있는 사용자가 조회할 때 복호화(Decryption)하여 원본을 보여주는 케이스
- 수학적 변환 데이터
- 인코딩(Base64)이나 진법 변환된 데이터
- 무손실 압축 파일
- 특정 가공이나 변환을 거친 후에도, 반대 연산이나 복원 알고리즘을 통해 원래의 원본 데이터로 100% 완벽하게 되돌릴 수 있는 데이터
- 불가역 데이터 (Irreversible Data)
- 데이터가 생성되거나 가공되는 과정에서 원본 정보의 일부 또는 전부가 유실되어, 어떠한 방법을 써도 절대 원래의 원본 데이터로 되돌리거나 유추할 수 없는 데이터
- 재생산 시, 원본 데이터와는 전혀 다른 형태로 재생산됨 🡲 환원 불가
- 특징
- 단방향성(One-way)을 가짐
- 주로 보안 강화, 용량 극대화, 또는 현실 세계의 관측 데이터를 다룰 때 나타남
- 주요 예시 및 활용 분야
- 단방향 해시 함수 (암호학)
- 사용자의 비밀번호를 저장할 때 쓰는 SHA-256, bcrypt 등이 대표적
- 원본 비밀번호를 복잡한 문자열(해시값)로 바꾸는 것은 가능하지만,
- 그 해시값을 역산해서 원본 비밀번호를 알아내는 것은 수학적으로 불가능함
- 손실 압축 파일
- .jpg 이미지, .mp3 음악, .mp4 영상 등은 사람이 인지하지 못하는 미세한 데이터 영역을 강제로 지워 용량을 줄임
- 이 파일들은 다시 압축을 풀어도 지워진 데이터가 돌아오지 않음
- 현실 세계의 자연 현상 데이터
- 센서가 수집한 온도, 습도, 바람의 세기 등은 한 번 측정되어 데이터화되면, 그 데이터만 보고 당시의 대기 상태 전체를 분자 단위로 역추적해 복원하는 것은 불가능함
- 통계적 요약 및 가명화 데이터
- 대형 로그 데이터에서 ‘일별 매출 합계’만 남기고 상세 내역을 지우거나, 개인정보를 알아볼 수 없게 마스킹(예: 홍*동) 처리한 데이터
- 단방향 해시 함수 (암호학)
- 데이터가 생성되는 원천(Source)의 특성과 “한 번 생성된 데이터를 원래 상태로 되돌리거나 유추할 수 있는가”에 초점을 맞춘 엔지니어링 및 보안 중심의 분류 방식
- 형태 및 구조화 수준에 따른 분류
2. 데이터베이스(Database, DB)
- 정의
- 여러 사용자가 서로 다른 목적으로 동시에 공유하여 사용할 수 있도록 체계적으로 통합·관리되는 데이터의 집합
- 단순히 데이터를 모아둔 것을 넘어, 컴퓨터 시스템에 전자적으로 저장되며,
- 필요한 데이터를 몇 밀리초(ms) 만에 찾아낼 수 있도록 효율적인 검색과 수정이 가능한 형태로 구조화되어 있음
2.1 왜 데이터베이스를 사용해야 하는가? (vs 파일 시스템)
과거에는 종이에 연필로 기록해 장부로 관리(오프라인 관리)
컴퓨터가 확산되면서 엑셀이나 텍스트 파일(파일 시스템)로 데이터를 관리
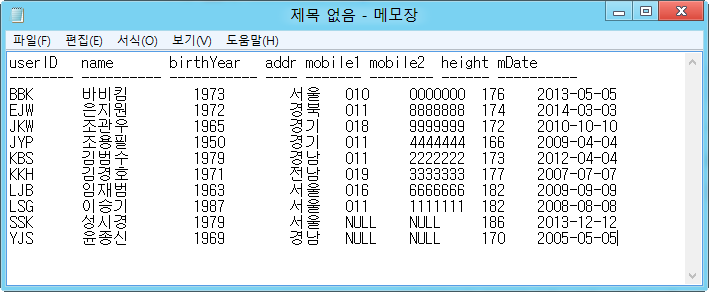
- 데이터의 양이 많아지고 사용자가 늘어나면서 다음과 같은 한계에 부딪힘
- 데이터 중복 및 불일치 문제
- 하나의 데이터가 여러 파일에 흩어져 있으면 수정 시 일부가 누락되어 데이터가 서로 달라지는 문제가 생김
- 동시성 문제
- 파일 시스템은 누군가 엑셀 등의 파일을 수정 중이면 다른 사람이 편집할 수 없거나 덮어쓰여짐
- 보안 및 권한 문제
- 데이터 중복 및 불일치 문제
- 이러한 문제를 해결하기 위해 데이터베이스가 탄생함
- 데이터 중복 및 불일치 방지 🡲 DB는 이를 중앙에서 한 번에 관리함
- 동시성 제어 🡲 DB는 수천 명이 동시에 접근해도 데이터가 깨지지 않도록 통제함
- 보안 및 권한 관리 🡲 열(Column) 단위, 행(Row) 단위까지 세밀하게 접근 권한을 제어할 수 있음
2.2 데이터베이스의 4대 핵심 특징
- 실시간 접근성 (Real-time Accessibility)
- 사용자가 요청하는 순간 실시간으로 데이터를 처리하여 응답함
- 계속적인 변화 (Continuous Evolution)
- 데이터의 삽입(Insert), 삭제(Delete), 수정(Update)을 통해 항상 최신 상태를 유지함
- 동시 공유 (Concurrent Sharing)
- 여러 사용자가 서로 다른 목적으로 동시에 동일한 데이터에 접근할 수 있음
- 내용에 의한 참조 (Content Reference)
- 데이터의 저장 위치나 주소가 아닌, 데이터의 ‘값(내용)’을 가지고 원하는 데이터를 찾음
2.3 데이터베이스 핵심 필수 용어 정의
데이터베이스 실무와 학습에서 가장 기본이 되는 6가지 필수 용어
- 스키마 (Schema)
- 정의
- 데이터베이스의 ‘뼈대’ 또는 ‘구조’를 의미
- 설명
- 데이터베이스에 어떤 테이블이 들어가고,
- 각 테이블에는 어떤 종류의 데이터(문자, 숫자 등)가 어떤 규칙으로 저장되는지
- 등을 정의한 청사진(설계도)
- 정의
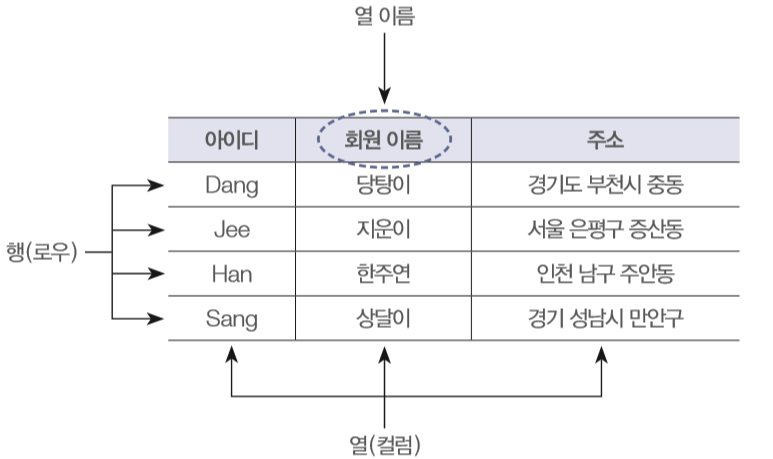
- 테이블 (Table) / 엔티티 (Entity)
- 정의
- 데이터를 저장하는 가장 기본적인 단위
- 행과 열로 구성된 표
- 설명
- (개념적으로는) 관리하고자 하는 대상(예: 사용자, 상품, 주문)을 ‘엔티티’라고 부름
- 이것이 데이터베이스 내에 실제 구현된 결과물이 ‘테이블’
- 정의
- 컬럼 (Column) / 속성 (Attribute)
- 정의
- 테이블의 세로줄을 의미
- 데이터의 고유한 특성을 담고 있음
- 설명
- 예를 들어 회원 테이블이 있다면
- 이름, 이메일, 가입일 등이 각각의 컬럼이 됨
- 각 컬럼은 정해진 데이터 타입(예: INT, VARCHAR)만 가질 수 있음
- 예를 들어 회원 테이블이 있다면
- 정의
- 로우 (Row) / 레코드 (Record) / 튜플 (Tuple)
- 정의
- 테이블의 가로줄을 의미
- 관계된 데이터들의 하나의 완전한 세트
- 설명
- 회원 테이블에서 “1번 회원 / 홍길동 / hong@email.com / 2026-05-29”라는 구체적인 실제 데이터 한 줄 전체가 하나의 로우
- 정의
- 기본키 (Primary Key, PK)
- 정의
- 테이블 내에서 각 로우(행)를 유일하게 식별할 수 있는 유일한 고유값 컬럼
- 설명
- 대한민국 국민에게 ‘주민등록번호’가 있듯이, 테이블 내의 모든 데이터는 중복되지 않는 고유한 PK를 가짐
- PK는 절대 비어있을 수 없으며(NOT NULL), 중복될 수 없(UNIQUE)
- 예: 회원번호, 주문번호
- 정의
- 외래키 (Foreign Key, FK)
- 정의
- 다른 테이블의 기본키(PK)를 참조하는 컬럼
- 테이블 간의 ‘관계’를 맺어줌
- 설명
- 주문 테이블에 회원번호 컬럼이 있다면, 이는 회원 테이블의 PK를 참조하는 외래키(FK)가 됨
- 이를 통해 “이 주문을 한 사람이 누구인지” 테이블 간의 연결 고리를 만듦
- 주문 테이블에 회원번호 컬럼이 있다면, 이는 회원 테이블의 PK를 참조하는 외래키(FK)가 됨
- 정의
2.4 데이터 아키텍처 계층 구조
데이터베이스 시스템이 구동되는 전체적인 계층을 위에서 아래로 요약하면
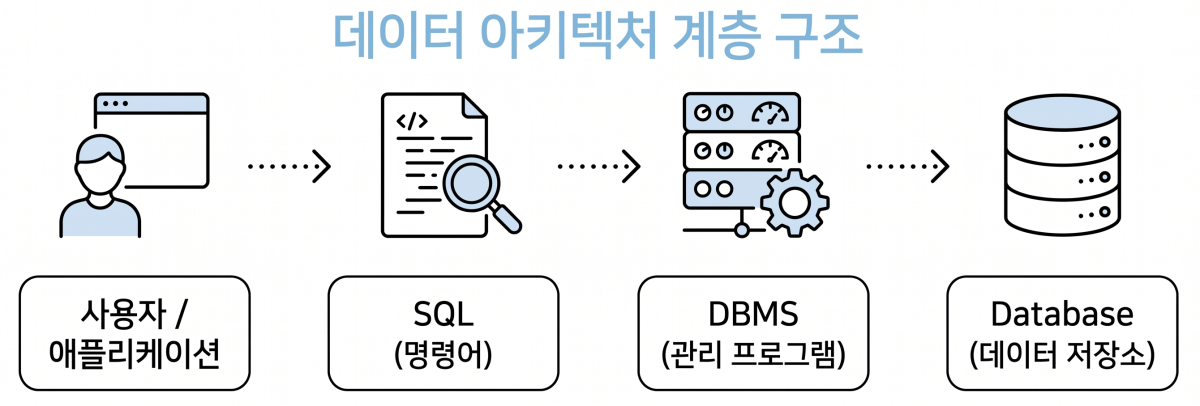
사용자/응용 프로그램: 필요한 데이터를 요청함
- SQL (구조화 질의어)
- 사용자가 데이터베이스와 소통하기 위해 사용하는 표준 언어
- 예: “회원 테이블에서 홍길동을 찾아줘”
- DBMS (데이터베이스 관리 시스템) -SQL 명령을 해석하여 실제 데이터 저장소에 안전하게 접근하고 결과를 돌려주는 소프트웨어 엔진
- 예: MySQL, Oracle
- Database (데이터베이스)
- 데이터가 물리적(디스크, 메모리)으로 정형화되어 저장되어 있는 물리적/논리적 집합소
3. 데이터베이스 관리 시스템(DBMS)
- 데이터베이스 관리 시스템(Database Management System, DBMS)
- 사용자와 데이터베이스 사이에서 데이터를 관리하고 사용자의 요구에 따라 효율적으로 정보를 생성해 주는 소프트웨어
- 예: MySQL, Oracle, PostgreSQL 등
- 데이터베이스가 데이터를 모아둔 ‘창고’라면, DBMS는 그 창고를 안전하게 관리하고 물건을 대신 꺼내주는 ‘창고 관리인’
- 엑셀 파일이나 단순 텍스트 파일과 달리, 대용량의 데이터를 여러 사람이 동시에 안전하게 쓸 수 있도록 통제해 주는 역할을 수행
DBMS 개념도
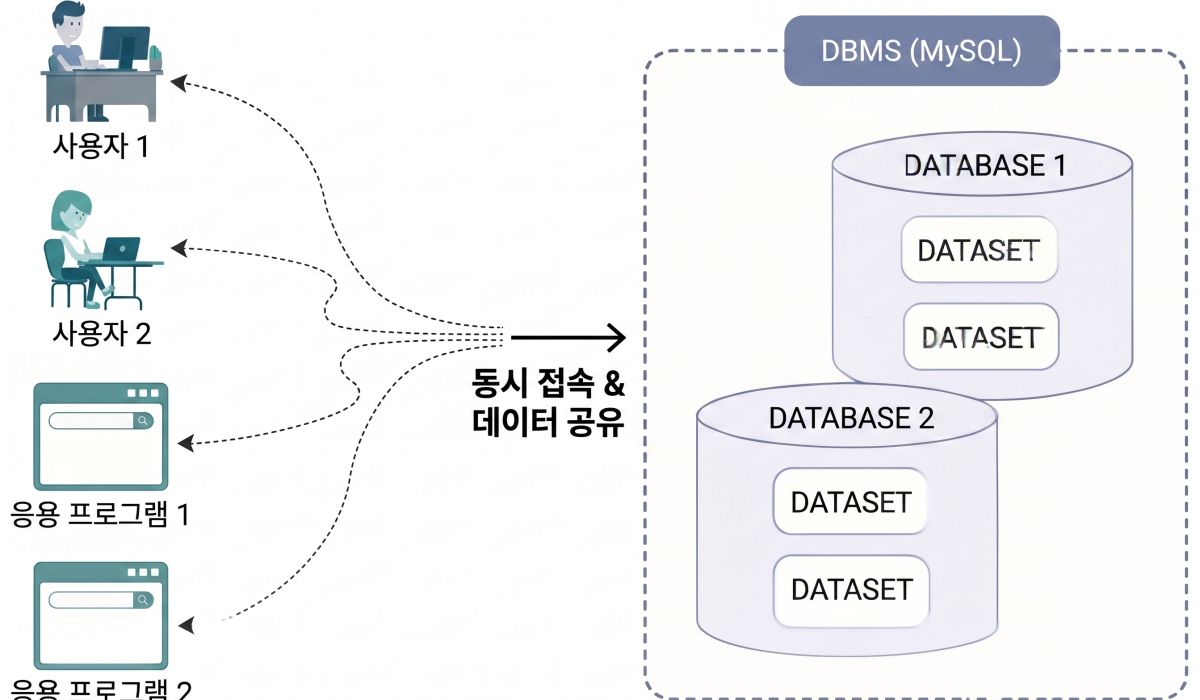
- DBMS의 3대 필수 기능
- 정의 (Definition)
- 데이터의 형태, 구조, 데이터가 가질 수 있는 조건(제약조건)을 설정
- 조작 (Manipulation)
- 데이터를 조회(Select), 삽입(Insert), 수정(Update), 삭제(Delete)할 수 있는 수단(예: SQL) 제공
- 제어 (Control)
- 데이터의 정확성 유지(무결성)
- 여러 사람이 동시에 접근해도 무너지지 않게 통제
- 권한이 있는 사람만 접근할 수 있도록 보안 유지
- 정의 (Definition)
- DBMS의 발달과 종류
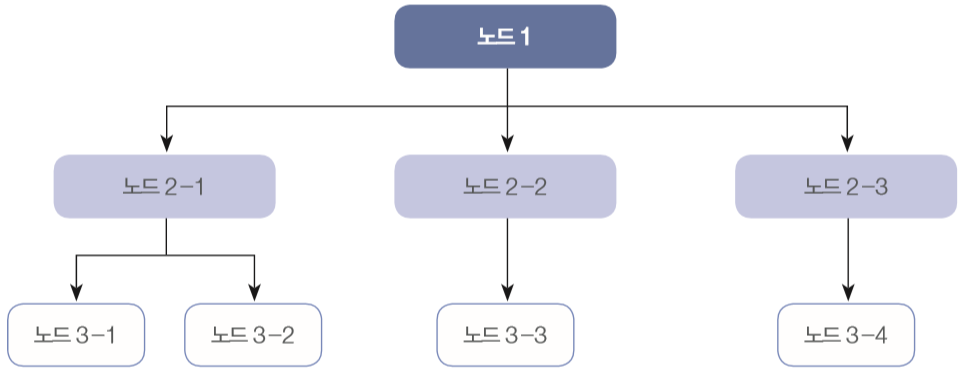
- 계층형 DBMS
- 처음으로 나온 DBMS 개념 - 1960년대에 시작
- 각 계층은 트리Tree 형태, 1:N 관계
- 문제점
- 처음 구축한 이후 그 구조를 변경하기가 상당히 까다로움
- 주어진 상태에서의 검색은 상당히 빠름
- 접근 유연성 부족해서 임의의 검색에는 어려움
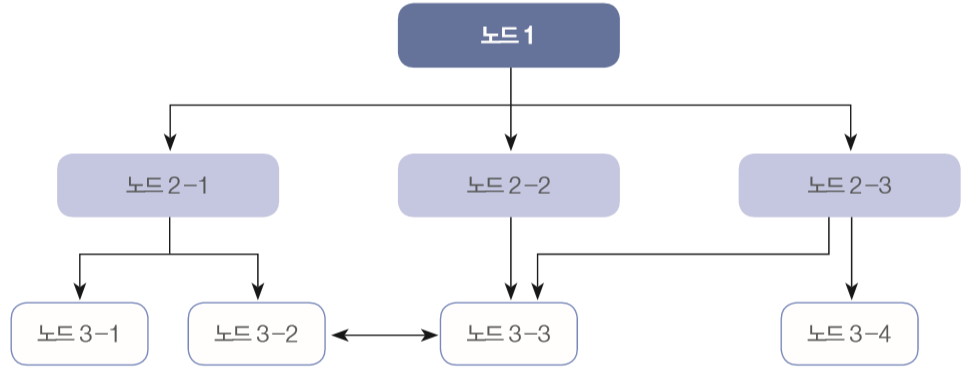
- 망형 DBMS
- 계층형 DBMS의 문제점을 개선하기 위해 1970년대에 시작
- 1:1,1:N, N:M(다대다) 관계 지원 - 효과적이고 빠른 데이터 추출
- 복잡한 내부 포인터 사용 🡲 프로그래머가 이 모든 구조를 이해해야만 프로그램의 작성 가능
- 관계형 DBMS (Relational DBMS, RDBMS)
- 1969년 E.F.Codd라는 학자가 수학 모델에 근거해 고안
- 에드거 F. 코드(E. F. Codd, 1923~2003): 관계형 데이터베이스(RDBMS)의 이론적 기반을 확립한 영국계 미국인 컴퓨터 과학자
- 데이터를 표(Table) 형태의 최소 단위로 관리하는 가장 표준적인 시스템
- 테이블은 하나 이상의 열로 구성
- 장점
- 다른 DBMS에 비해 업무가 변화될 경우 쉽게 변화에 순응
- 유지보수 측면에서도 편리
- 대용량 데이터의 관리와 데이터 무결성Integration보장
- 단점
- 시스템 자원을 많이 차지해 시스템이 전반적으로 느려지는 것 🡲 하드웨어가 발전하면서 해결됨
- 종류: MySQL, Oracle, PostgreSQL, MS SQL Server
- 1969년 E.F.Codd라는 학자가 수학 모델에 근거해 고안
- 비관계형 DBMS (NoSQL)
- 정해진 틀 없이 자유로운 형태(JSON, Key-Value 등)로 데이터를 대량 적재할 때 사용
- 종류: MongoDB, Redis, Cassandra
- 계층형 DBMS
4. 구조화 질의어(SQL)
- SQL (Structured Query Language, 구조화 질의어)
- 관계형 데이터베이스(RDBMS)에 저장된 데이터를 관리하고 소통하기 위해 사용하는 표준 컴퓨터 언어
- DBMS와 대화하기 위한 표준 언어
- 데이터베이스라는 창고(RDBMS)에 있는 데이터를 조회하고, 넣고, 수정하고, 지우기 위해 창고 관리인(DBMS)에게 건내는 ‘표준 명령어(대화 수단)’
- SQL의 3대 핵심 기능 분류
- SQL은 목적에 따라 크게 세 가지 종류의 명령어로 나뉨
- DCL (Data Control Language - 데이터 제어어)
- 역할: 데이터베이스에 대한 접근 권한을 주거나 빼앗을 때 사용
- 명령어: GRANT (권한 부여), REVOKE (권한 회수), DENY (명시적 거부)
- 포함 범위: 데이터베이스 시스템 전체 시스템 및 보안 영역
- 가장 강력하고 넓은 범위를 제어함
- DDL이나 DML을 실행할 수 있는 ‘권한 자체’를 통제하는 계층
- DCL(GRANT, REVOKE)을 통해 허가를 받아야만 그 안의 DDL이나 DML 영역으로 진입할 수 있으므로, 모든 데이터베이스 행위의 최상위 울타리 역할을 수행
- DDL (Data Definition Language - 데이터 정의어)
- 역할: 테이블이나 데이터베이스 같은 ‘데이터의 틀’을 만들고 변경할 때 사용
- 명령어: CREATE (생성), ALTER (수정), DROP (삭제), TRUNCATE (초기화)
- 포함 범위: 데이터베이스, 테이블, 뷰 등 ‘틀(구조)’ 영역
- DCL의 허가를 받은 사용자가 들어와서 데이터를 담을 ‘바구니(테이블)’를 만들고 변형하고 부수는 계층
- 테이블 구조(CREATE, ALTER, DROP)가 먼저 생성되어야만 그 안에서 실제 데이터를 조작할 수 있으므로, DML을 포함하는 상위 개념
- DML (Data Manipulation Language - 데이터 조작어)
- 역할: 데이터를 실제로 다룰 때 사용하며, 실무에서 가장 많이 사용됨
- 명령어: SELECT (조회), INSERT (삽입), UPDATE (수정), DELETE (삭제)
- 포함 범위: 테이블 내부의 ‘실제 데이터(Row/Record)’ 영역
- DDL로 만들어진 바구니 안에서 실제 알갱이(데이터)들을 넣고, 바꾸고, 지우고, 조회하는 가장 구체적이고 작은 단위의 계층
- 구조(DDL)가 없다면 존재할 수 없으며, 일반 개발자가 실무에서 가장 많이 마주하는 영역
- DCL (Data Control Language - 데이터 제어어)
- SQL은 목적에 따라 크게 세 가지 종류의 명령어로 나뉨
- SQL의 주요 특징
- 세계적 표준
- ISO(국제표준화기구)에서 지정한 표준 언어
- MySQL, Oracle, PostgreSQL 등 어떤 DBMS를 쓰더라도 기본 문법은 거의 동일하게 작동함
- 선언적 언어
- “데이터가 어디에 어떻게 저장되어 있는지” 과정을 지시하는 것이 아니라,
- “내가 원하는 결과 데이터가 무엇인지(What)”만 선언하면 DBMS가 알아서 찾아옴
- 영어와 유사한 문법
- 대문자/소문자를 가리지 않으며,
- 영어 문장 구조(SELECT name FROM users WHERE id = 1)와 매우 비슷하여 직관적이고 배우기 쉬움
- 세계적 표준