ERD 설계
1. ERD 설계의 개념과 의의
- ERD(Entity-Relationship Diagram) 설계는 단순히 데이터베이스 테이블을 시각적으로 그리는 작업이 아님
- 학술적·기술적으로 “현실 세계의 비즈니스 도메인을 정형화된 모델링 언어를 통해 데이터 구조로 추상화하는 고도의 엔지니어링 과정”을 의미함
1.1 ERD 설계의 핵심 개념
- 비즈니스 규칙(Business Rule)의 기호화
- 현업에서 사용하는 말(말씀, 문서, 업무 프로세스)은 모호성을 가짐
- 예시: 우리는 단골 고객에게 특별 혜택을 준다 🡲 개발 불가능
- ERD 설계는 이러한 모호한 비즈니스 규칙을 엔터티(Entity), 속성(Attribute), 관계(Relationship), 사상수(Cardinality)라는 엄격한 표준 기호로 치환하여 단 하나의 의미로만 해석되도록 고정하는 작업
- 현업에서 사용하는 말(말씀, 문서, 업무 프로세스)은 모호성을 가짐
- 점진적 구체화 (Multi-Level Modeling)
- ERD 설계는 한 번에 완성되지 않고 인간의 사고 흐름에 맞춰 점진적으로 발전함
- 개념적 설계
- 기술적 요소를 배제하고 “무엇(What)”을 관리할 것인가에 집중 🡲 핵심 뼈대 확립
- 논리적 설계
- 어떻게 데이터 중복을 없애고 무결성을 유지할 것인가(정규화)에 집중 🡲 상세 속성과 식별자 정의
- 물리적 설계
- 특정 DBMS의 특성과 하드웨어 성능(반정규화, 인덱스)을 고려
- 실제 컴퓨터 공간에 이식할 수 있는 도면으로 완성
- 개념적 설계
- ERD 설계는 한 번에 완성되지 않고 인간의 사고 흐름에 맞춰 점진적으로 발전함
1.2 ERD 설계의 의의
- 프로젝트 생명주기(SDLC) 관점에서 ERD 설계가 가지는 의의
- ‘선(先) 설계, 후(後) 구현’을 통한 비용의 기하급수적 절감
- 개발 프로세스에서 설계가 가지는 가장 큰 의의는 경 경제성
- 요구사항의 모순이나 데이터 구조의 결함을 코딩 단계(구현)나 테스트 단계에서 발견
- 시스템 전반을 뜯어고쳐야 함 🡲 막대한 재작업 비용(Rework Cost) 발생
- ERD 설계 단계에서 발견
- 지우개와 연필(혹은 모델링 툴)만으로 구조를 쉽게 변경 가능
- 프로젝트의 위험 요소를 가장 저렴한 비용으로 선제 해결 가능
- 요구사항의 모순이나 데이터 구조의 결함을 코딩 단계(구현)나 테스트 단계에서 발견
- 개발 프로세스에서 설계가 가지는 가장 큰 의의는 경 경제성
- 비즈니스 언어와 데이터 언어 사이의 유일한 ‘번역기(Bridge)’
- 시스템 개발에는 기획자, 현업 실무자, DBA, 백엔드 개발자, 프론트엔드 개발자 등 다양한 이해관계자가 참여함
- 이들은 서로 사용하는 언어가 다름
- 예시
- 현업 : “주문이 들어오면 공장에 알림을 보내고 재고를 깎아주세요.”
- 개발자 : “Insert 쿼리가 발생하면 트리거를 태우거나 메시지 큐로 이벤트를 쏴야겠군.”
- 예시
- ERD는 이 양 극단의 언어를 연결하는 공통의 시각 언어(Universal Visual Language)
- 잘 차려진 ERD 한 장을 보며 기획자와 개발자가 함께 업무 로직의 타당성을 검증할 수 있는 소통의 도구로서 거대한 의의를 가짐
- 데이터 무결성(Data Integrity)과 안정성의 청사진
- 프로그램 소스 코드는 버그가 나면 수정해서 다시 배포하면 그만
- 그러나 **한번 깨지거나 중복되어 엉망이 된 데이터는 복구하기가 불가능에 가깝거나 엄청난 대가를 치러야 함
- ** ERD 설계 과정에서 진행하는 ‘정규화(Normalization)’와 ‘제약조건(Constraint) 정의’**
- 데이터가 태어날 때부터 소멸할 때까지 오염되지 않고 일관성을 유지할 수 있도록 보호막을 치는 과정
- 즉, 시스템의 ‘영혼’과 같은 데이터를 안전하게 담는 그릇을 디자인하는 엄숙한 의의가 있음
- 시스템 자산의 공식 문서화 (Data Governance)
- 대다수의 기업 시스템은 구축 이후 수년, 수십 년간 유지보수 과정을 거침
- ERD는
- 최초 개발자가 퇴사하더라도 시스템의 구조를 원형 그대로 파악할 수 있게 해주는 최종 명세서이자 인수인계서
- 잘 관리된 ERD는 기업의 데이터 자산을 체계적으로 관리하는 ‘데이터 거버넌스’의 핵심 기반이 ehla
- ‘선(先) 설계, 후(後) 구현’을 통한 비용의 기하급수적 절감
- 코딩은 컴퓨터에게 일을 시키는 기술이지만, ERD 설계는 복잡한 현실 세계를 정돈된 논리로 지배하는 아키텍처 기술
- 훌륭한 개발자는 키보드를 두드리는 시간보다, ERD를 보며 데이터의 흐름과 비즈니스의 모순을 고민하는 시간에 더 집중해야 함
2. ERD 설계 도구의 선택
- 기본적으로 고려해야 할 4가지 핵심 사항
도구를 평가하기 전, 우리 프로젝트 환경과 조직이 어떤 상태인지 먼저 정의해야 함
- 포워드 엔지니어링(Forward Engineering)의 깊이
- 핵심 질문
- 모델러가 그린 그림(ERD)이 실제 DB 스키마(DDL)로 얼마나 정밀하게 변환되는가?
- 고려 사항
- 단순히
CREATE TABLE문만 뽑아주는 수준인지? - 테이블 스페이스 지정, 외래키(FK) 제약조건 옵션(
ON DELETE CASCADE등), 데이터 타입의 DBMS별 완벽 호환성까지 지원하는지?
- 단순히
- 핵심 질문
- 라운드 트립(Round-Trip) 및 동기화(Synchronization) 능력
- 핵심 질문
- 설계가 바뀐 내용이나, 반대로 운영 중인 DB가 바뀐 내용을 양방향으로 안전하게 일치시킬 수 있는가?
- 고려 사항
- 실무에서는 ERD 설계 후 개발 도중에 구조가 바뀌는 일이 허다함
- 이때 기존 데이터를 날리지 않고 차이점만 분석하여
ALTER문을 안전하게 생성해 주는 Diff 엔진(동기화 기능)의 유무가 생산성을 결정지을 수 있음
- 핵심 질문
- 팀 협업 및 변경 이력 관리 (Version Control)
- 핵심 질문
- 여러 명의 아키텍트와 개발자가 동시에 하나의 ERD를 수정할 수 있는가?
- 변경 이력이 추적되는가?
- 고려 사항
- 대형 프로젝트일수록 파일 단위(예:
.xml,.erd)로 공유하면 충돌이 발생함 - Git과의 궁합이 좋거나(텍스트 기반 저장), 자체 클라우드/리포지토리를 통해 동시 편집 및 버전 관리(History)를 지원해야 함
- 대형 프로젝트일수록 파일 단위(예:
- 핵심 질문
- 다중 DBMS(Multi-Database) 지원 여부
- 핵심 질문
- 우리 시스템이 단일 DB만 쓰는가, 아니면 다양한 DB(MySQL, PostgreSQL, Oracle 등)를 혼용하는가?
- 고려 사항
- 특정 DBMS 전용 툴(예: MySQL Workbench)은 해당 DB에는 최적화되어 있으나
- 다른 DB로 이전하거나 이기종 DB를 결합할 때 한계가 있음
- 전사 표준 도구를 고를 때는 범용성을 반드시 고려해야 함
- 핵심 질문
- 구체적인 ERD 도구 선택 기준 (Evaluation Criteria)
| 평가 기준 | 세부 검토 항목 | 비고 |
|---|---|---|
| 엔지니어링 성능 (Engineering Capability) | • Forward: ERD 🡲 DB 생성 스크립트 추출 정확도 • Reverse: 가동 중인 DB 🡲 ERD 시각화 정밀도 • Diff/Sync: 설계와 실제 DB 간의 차이점 자동 동기화 | • 실무형 설계 도구와 단순 드로잉 툴(Draw.io 등)을 가르는 가장 결정적인 기준 |
| 표기법 및 모델링 규격 (Notation Support) | • 까마귀 발 표기법(Information Engineering) 지원 여부 • IE, IDEF1X, Chen 등 다양한 표준 표기법 전환 가능 여부 • 개념/논리/물리 단계별 뷰 전환 지원 | • 교육 및 표준화 관점에서 매우 중요 • 논리 모델(한글명)과 물리 모델(영문명)이 따로 관리되어야 진정한 모델링 툴 |
| 협업 및 클라우드 (Collaboration) | • 동시 편집(Real-time Co-editing) 기능 제공 여부 • 웹 브라우저 기반(SaaS) 가동 여부 • 변경 사항에 대한 코멘트 및 승인(Approve) 워크플로우 | • 원격 근무나 대규모 조별 프로젝트 강의 시 SaaS 기반 툴이 압도적으로 유리함 (예: DrawDB, ERDLab 등) |
| 비용 및 라이선스 (Cost & License) | • 오픈소스(Open-Source) 또는 완전 무료(Free) 여부 • 상용 도구인 경우 학생/교육용 라이선스 제공 여부 • 온프레미스(On-Premise) 구축 시 추가 비용 발생 여부 | • 기업에서는 ERwin, DA# 같은 고가 장비를 쓰지만, • 교육 현장이나 스타트업에서는 오픈소스나 오픈소스 기반 무료 에디션이 최선 |
| 생산성 및 UI/UX (Productivity) | • 테이블/컬럼 드래그 앤 드롭의 직관성 • 도메인(Domain) 정의 기능 (예: '주소' 타입을 정의해 재사용) • 사전 정의된 단어집/용어 사전(Dictionary) 연동 기능 | • 데이터 표준화(명명 규칙)를 강제할 수 있는 용어 사전 기능이 있으면 대형 프로젝트 설계 시 품질이 비약적으로 상승함 |
| 인프라 및 설치 환경 (Environment) | • OS 호환성 (Windows, Mac, Linux Mint/Ubuntu 등) • 웹 기반 가동 vs 무거운 데스크톱 가프리케이션 설치 • 자원 소모량 (대규모 테이블 배치 시 렉 발생 여부) | • 리눅스 환경에서 AI 모델링과 DB를 동시에 다루는 개발자에게는 크로스 플랫폼(Java 기반 또는 웹 기반) 지원이 필수적 |
- “도구 선택 시뮬레이션” 가이드 (3가지 가상 시나리오)
- 시나리오 A (스타트업 / 빠른 MVP 개발 / 웹 기반):
- 요구 조건: 설치 없고, 돈 안 들고, 팀원 3명이 동시에 브라우저에서 보면서 설계하고 싶다.
- 추천 매핑: DrawDB (웹 기반 오픈소스, DDL 즉시 추출)
- 시나리오 B (전통적인 공공/금융 대기업 프로젝트 / 데이터 표준화 필수):
- 요구 조건: 테이블이 500개가 넘고, 한글 논리명과 영문 물리명을 엄격히 분리해야 하며, 용어 사전이 필요하다.
- 추천 매핑: ERwin, DA# (상용) 또는 오픈소스 중 강력한 아키텍처를 가진 pgModeler
- 시나리오 C (풀스택 개발자 과정 / SQL 단기 속성):
- 요구 조건:
- SQL 쿼리도 날려야 하고, 가끔 테이블 관계도 직접 그려서 DB에 바로 반영하고 싶다.
- 프로그램을 여러 개 깔기 싫다.
- 추천 매핑: DBeaver Community Edition (Custom ERD 기능 활성화)
3. MySQL Workbench
3.1 MySQL Workbench 개요
- 오라클(Oracle)에서 공식 제공하는 MySQL 전용 무료 데이터베이스 디자인 및 관리 툴
오랜 기간 검증된 정통 모델링 도구의 UI 지원
- MySQL Workbench의 특징
- 전통적인 3단계 모델링 최적화
- 개념적/논리적 모델을 그리고, 이를 물리적 DB로 포워드 엔지니어링(Forward Engineering)하는 전통적인 데이터 모델링 워크플로우를 가장 정석대로 지원함
- MySQL 및 MariaDB 100% 호환
- 국내 수많은 국비지원 교육이나 부트캠프에서 표준처럼 사용하는 도구
- 레퍼런스와 트러블슈팅 자료가 인터넷에 가장 풍부함
- 설계 및 연동 방식
- 화면에 네모(테이블)를 그리고 속성을 정의한 뒤, 마우스로 선을 연결해 PK/FK 관계를 맺는 비주얼 설계(EER Model) 기능이 핵심
- 설계가 끝나면 [Database] -> [Forward Engineer] 메뉴를 통해, 마우스 클릭 몇 번만으로 실제 라이브 DB 서버에 실시간으로 테이블과 제약조건을 생성(Apply)해 줌
- 전통적인 3단계 모델링 최적화
3.2 MySQL Workbench 설치
Windows 10/11 기준 MySQL Workbench 설치 과정
- 1단계: 사전 필수 패키지 확인 (매우 중요)
- Workbench를 설치하기 전에 Windows에 Visual C++ Redistributable(재배포 가능 패키지)이 설치되어 있어야 함
- 설치되어 있지 않으면 Workbench 실행 시 MSVCP140.dll이 없어 프로그램을 시작할 수 없다는 에러가 발생
- 공식 마이크로소프트 서포트 페이지에서
VC_redist.x64.exe를 다운로드하여 먼저 설치
- Workbench를 설치하기 전에 Windows에 Visual C++ Redistributable(재배포 가능 패키지)이 설치되어 있어야 함
- 2단계: 설치 파일 다운로드
- MySQL 공식 다운로드 페이지(dev.mysql.com/downloads/workbench) 접속
- OS는 Microsoft Windows 선택
Windows (x86, 64-bit), MSI Installer(약 30~40MB) 파일 [Download] 버튼 클릭- 로그인 창이 뜨면 🡲 하단의 “No thanks, just start my download.”를 눌러 바로 다운로드
- 3단계: 마법사(Wizard) 실행 및 설치
- 다운로드된
.msi파일을 더블 클릭하여 실행 - Destination Folder: 설치 경로를 지정, 기본값(
C:\Program Files\MySQL\MySQL Workbench 8.0\) 상태로 [Next] - Setup Type: Complete(전체 설치)를 선택하고 [Next]
- Ready to Install: 내용 확인 후 [Install] 버튼을 클릭하면 관리자 권한 요청 후 설치가 진행됨
- Finish: 설치가 완료되면
Launch MySQL Workbench체크박스를 켜둔 채로 [Finish] 🡲 프로그램 정상 구동 확인
- 다운로드된
- 1단계: 사전 필수 패키지 확인 (매우 중요)
Linux 설치
AI 서버 운영이나 개발자 실습을 위해 Ubuntu 24.04 환경 등에서 설치하는 과정
- 1단계: 시스템 패키지 업데이트
설치 전 최신 의존성 라이브러리를 반영
sudo apt update && sudo apt upgrade -y
- 2단계: 웹에서 패키지 다운로드
일반 실행 패키지(25.3M)의 링크를 주소창에서 복사
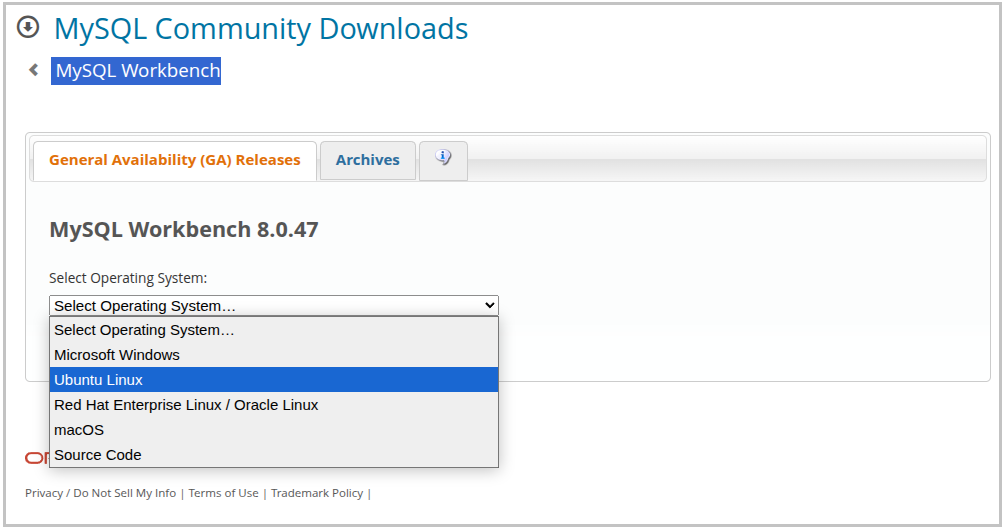
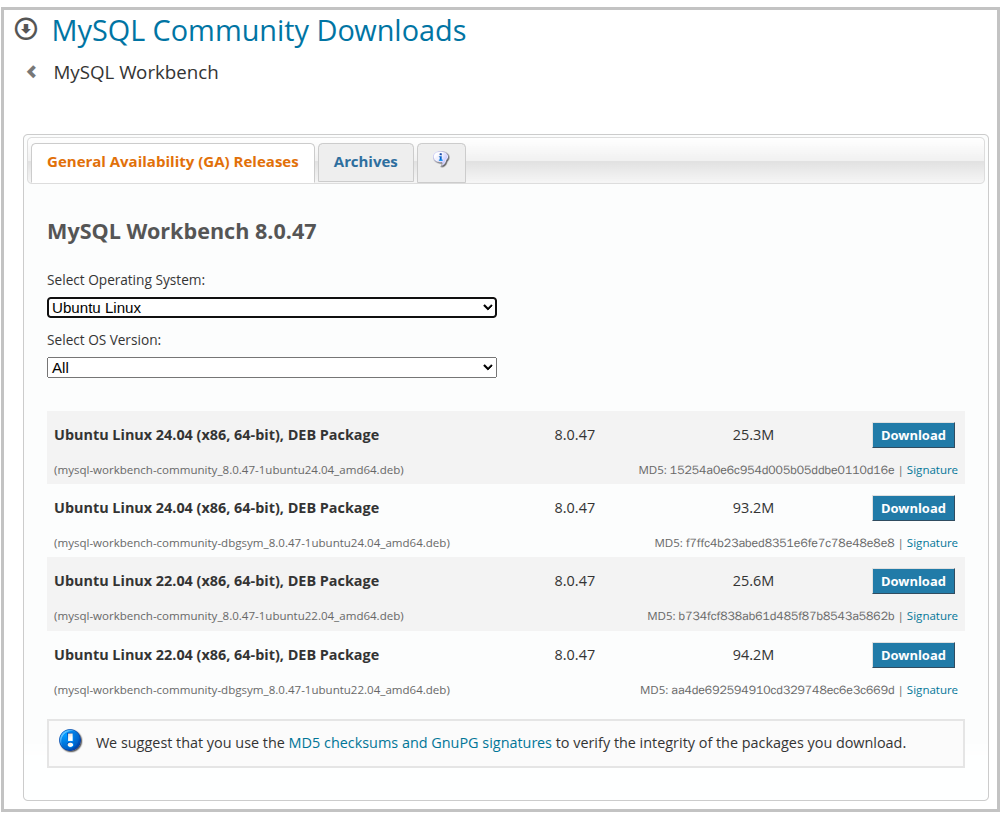
- 리눅스(Ubuntu 계열) 다운로드 선택지 2종의 차이점
“디버깅(오류 추적) 정보의 포함 여부”와 그로 인한 “용량 차이”
mysql-workbench-community_8.0.47-1ubuntu24.04_amd64.deb(25.3M)- 정의: 일반 사용자와 개발자를 위한 실제 실행 바이너리 패키지(Production 빌드)
- 특징: 프로그램 실행에 필요한 최적화된 코드만 들어있어 용량이 작음
- 용도: 일반적인 ERD 설계, SQL 실습, DB 관리 등 모든 실무 및 강의 환경에서는 이 파일만 설치하면 됨
mysql-workbench-community-dbgsym_8.0.47-1ubuntu24.04_amd64.deb(93.2M)- 정의:
- 디버그 심볼(Debug Symbols)이 포함된 디버깅 전용 패키지
- 파일명의
dbgsym이 Debug Symbol을 의미함
- 파일명의
- 디버그 심볼(Debug Symbols)이 포함된 디버깅 전용 패키지
- 특징:
- Workbench가 실행되다가 갑자기 크래시(Crashes)가 나거나 메모리 누수가 발생했을 때, 시스템의 어떤 소스 코드 라인에서 에러가 났는지 추적할 수 있는 메타데이터가 들어있음
- 핵심 코드는 없고 오직 ‘심볼’만 들어있기 때문에 단독 실행은 불가능
- ①번 패키지(
mysql-workbench-community_8.0.47-1ubuntu24.04_amd64.deb)가 먼저 설치되어 있어야 함
- 용도:
- MySQL Workbench 자체의 버그를 수정하려는 오픈소스 기여자(Contributor)
- 리눅스 커널 수준에서 프로그램 오류를 딥러닝하게 분석해야 하는 시스템 엔지니어가 주로 사용
- 정의:
- 리눅스(Ubuntu 계열) 다운로드 선택지 2종의 차이점
또는 터미널에서
wget명령어로 직접 다운로드 (2026년 기준 8.0.47 버전 예시)wget https://dev.mysql.com/get/Downloads/MySQLGUITools/mysql-workbench-community_8.0.47-1ubuntu24.04_amd64.deb
- 3단계: dpkg를 통한 설치 및 의존성 문제 해결
다운로드한 패키지 설치:
sudo dpkg -i mysql-workbench-community_8.0.47-1ubuntu24.04_amd64.deb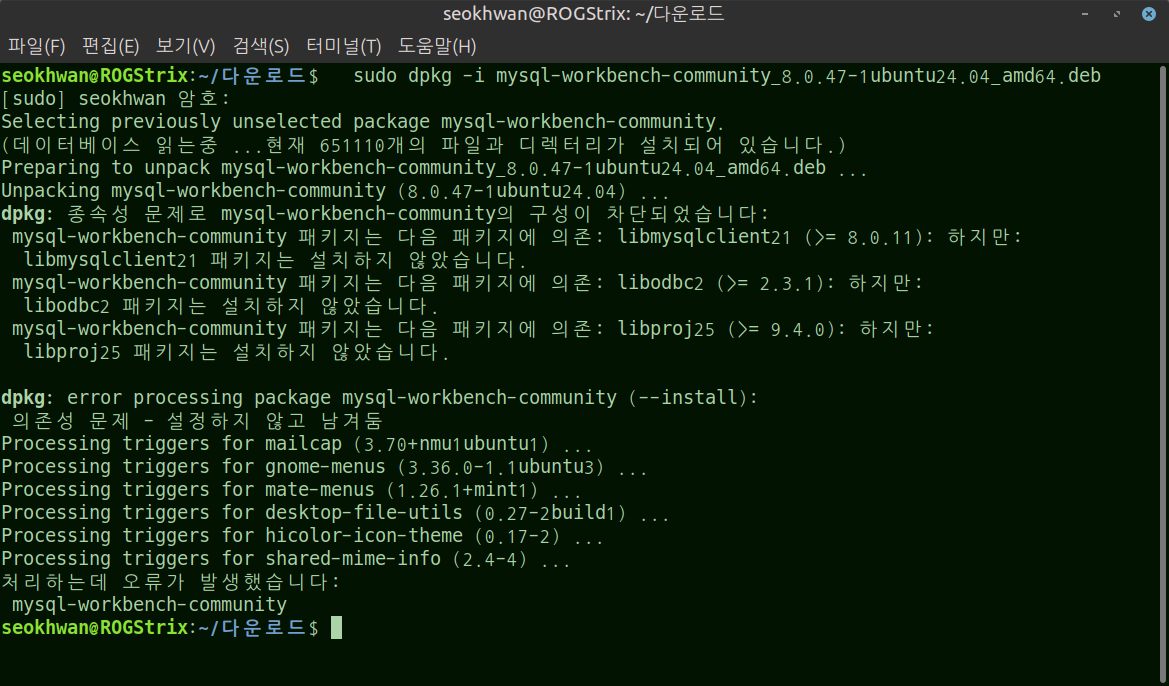
만약 여기서 의존성 에러가 발생한다면
- 리눅스에서
.deb파일을 직접 설치할 때 간혹 필요한 주변 라이브러리(의존성)가 누락되어 에러가 날 수 있음 아래 명령어를 입력하여 깨진 의존성을 자동으로 교정하고 설치를 마무리
sudo apt --fix-broken install -y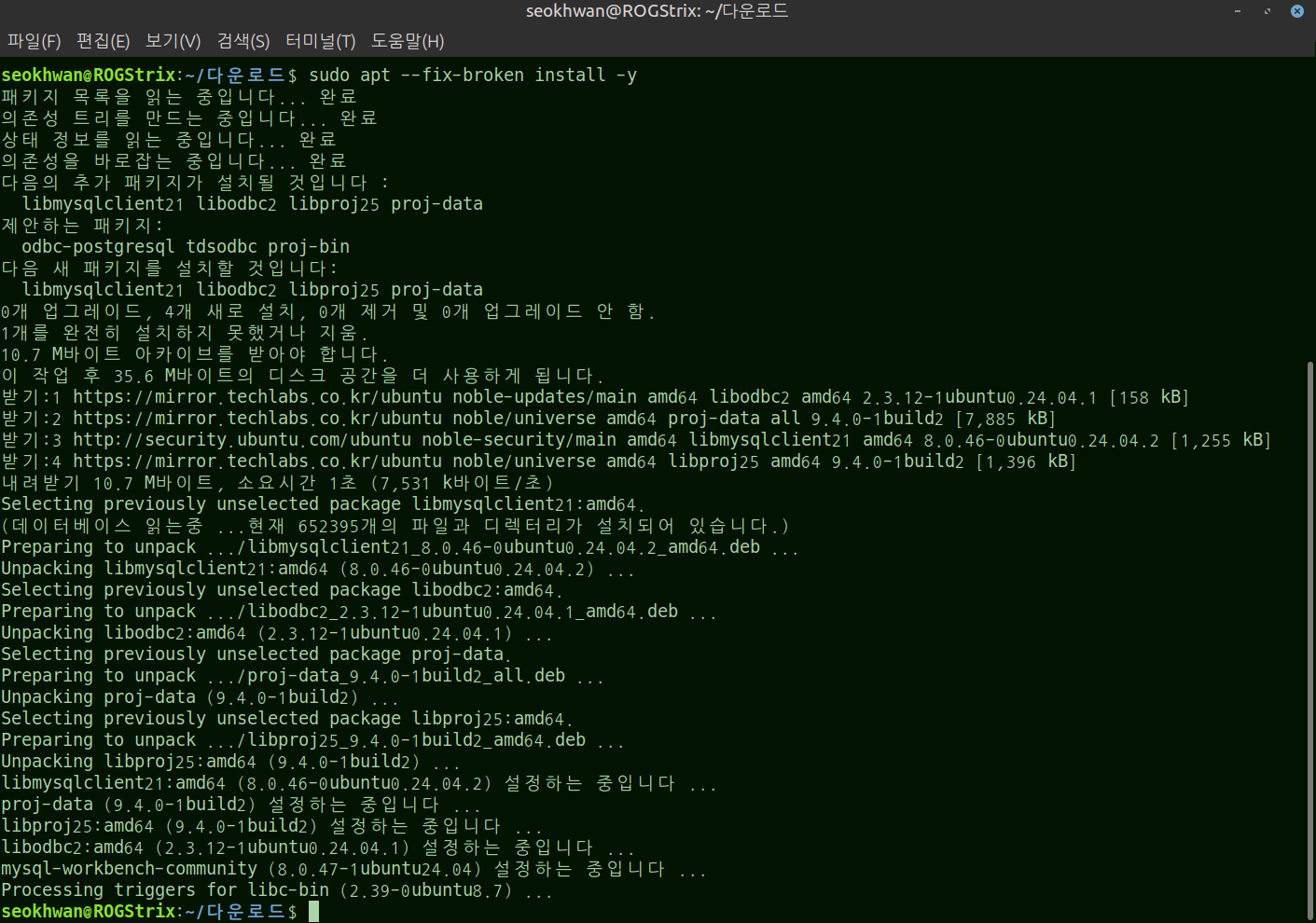
- 리눅스에서
- 4단계: 프로그램 실행 및 검증
- 설치가 완료되면 쉘 커맨드라인에 아래 명령어를 입력
또는 우분투 대시(Application 돋보기)에서 “MySQL Workbench”를 검색하여 실행
mysql-workbench &- 명령어 뒤의
&의 의미는 해당 프로그램을 백그라운드로 실행하라는 의미임
- MySQL Workbench는 엄격한 OS 정보(배포판 이름 등) 검증을 수행하므로 Ubuntu, Debian, RedHat 등 대표적인 배포판 명 외에는 모두 오류처리 함
- 실제 내용에는 아무 문제 없는 경우가 대부분임
- 명령어 뒤의
오류 메시지 발생 시 그냥 “OK” 버튼을 누르면 지나감
- 리눅스(특히 Ubuntu) 환경에서 MySQL Workbench를 실행했을 때, 간혹 화면 서체(Font)가 깨지거나 단축키가 꼬이는 현상이 발생할 수 있음.
- 이 경우, 시스템 기본 폰트 패키지(
fonts-noto-cjk)가 잘 설치되어 있는지 체크할 것
4. ERD 작성하기
4.1 기본적인 ERD 작성 예제
- 백지 상태에서 엔터티를 추가하고, 관계를 맺은 뒤, 실제 데이터베이스(DB)를 향한 포워드 엔지니어링(Forward Engineering)
- [고객(Customer)]과 [주문(Order)]이라는 간단하고 명확한 $1:N$ 비즈니스 관계 설계하기
- 실습 시나리오
- 우리 쇼핑몰은 고객(Customer) 정보를 관리합니다.
- 한 명의 고객은 여러 번 주문(Order)을 넣을 수 있습니다.
- 단, 가입하지 않은 고객은 주문할 수 없습니다.
- 이 규칙을 만족하는 ERD를 설계하고 실제 DB에 테이블을 생성합니다.
- 1단계: 새로운 모델링 공간(EER Canvas) 만들기
- MySQL Workbench 실행
상단 메뉴에서 [File] 🡲 [New Model]
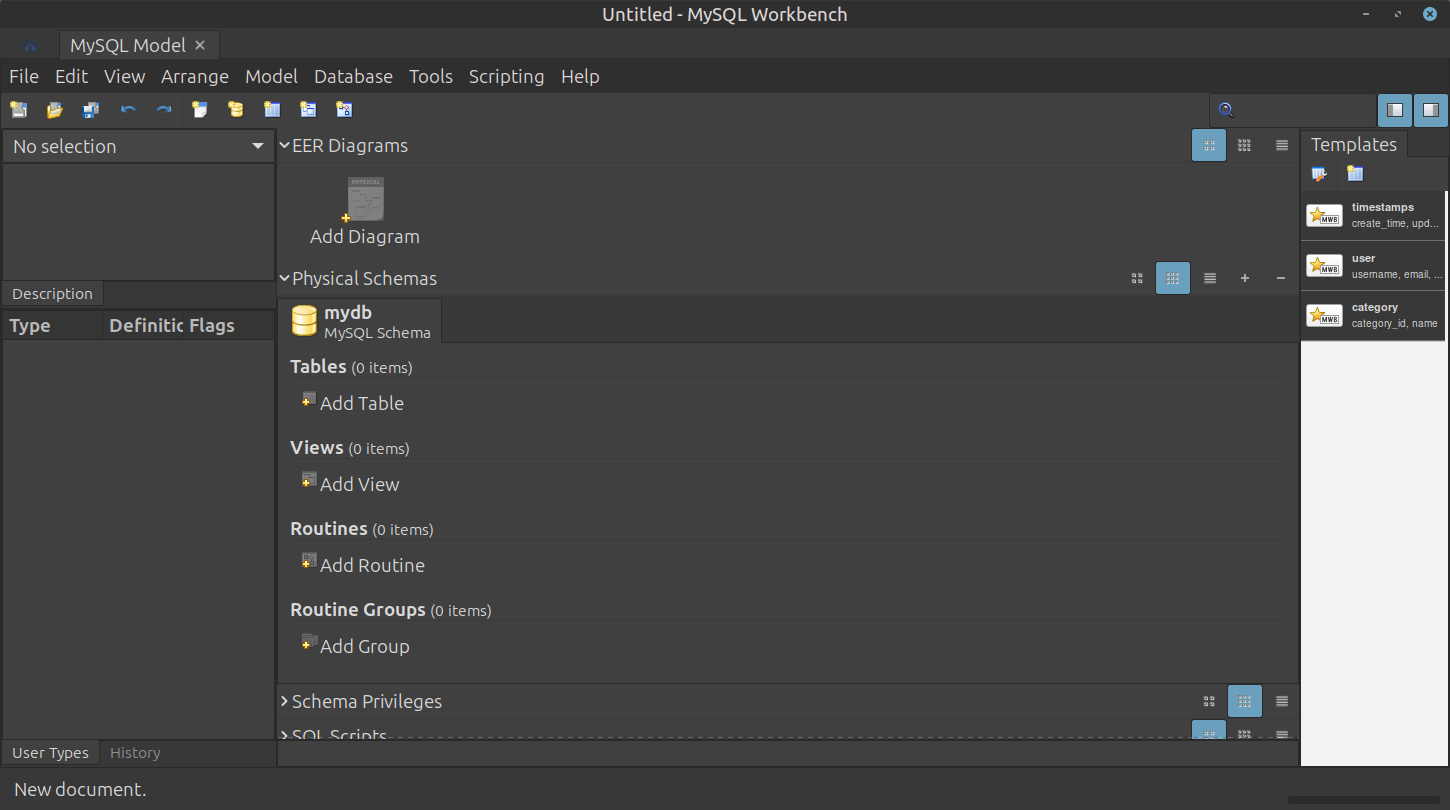
- 새로운 모델 창이 뜨면, 중간에 있는 [Add Diagram] 아이콘(노란색 플러스가 그려진 다이어그램 모양)을 더블 클릭
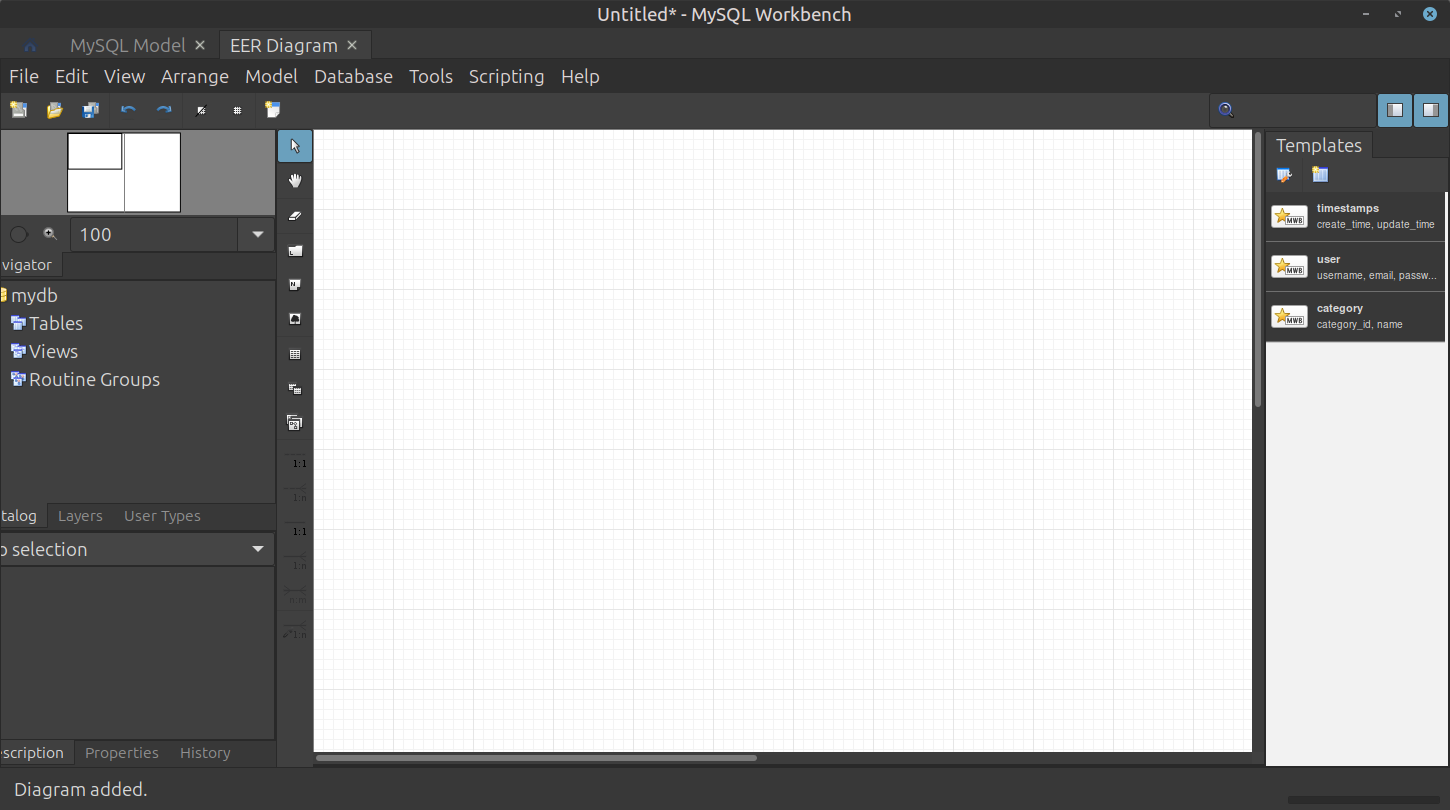
모눈종이 형태의 깨끗한 설계용 캔버스(EER Diagram) 화면이 열림
- 2단계: ‘고객(Customer)’ 엔터티(테이블) 설계
왼쪽 세로 툴바에서 [Place a New Table] 아이콘(사각형 모양, 단축키
T) 클릭 🡲 캔버스 빈 곳을 아무 데나 클릭 🡲table1이라는 임시 테이블 생성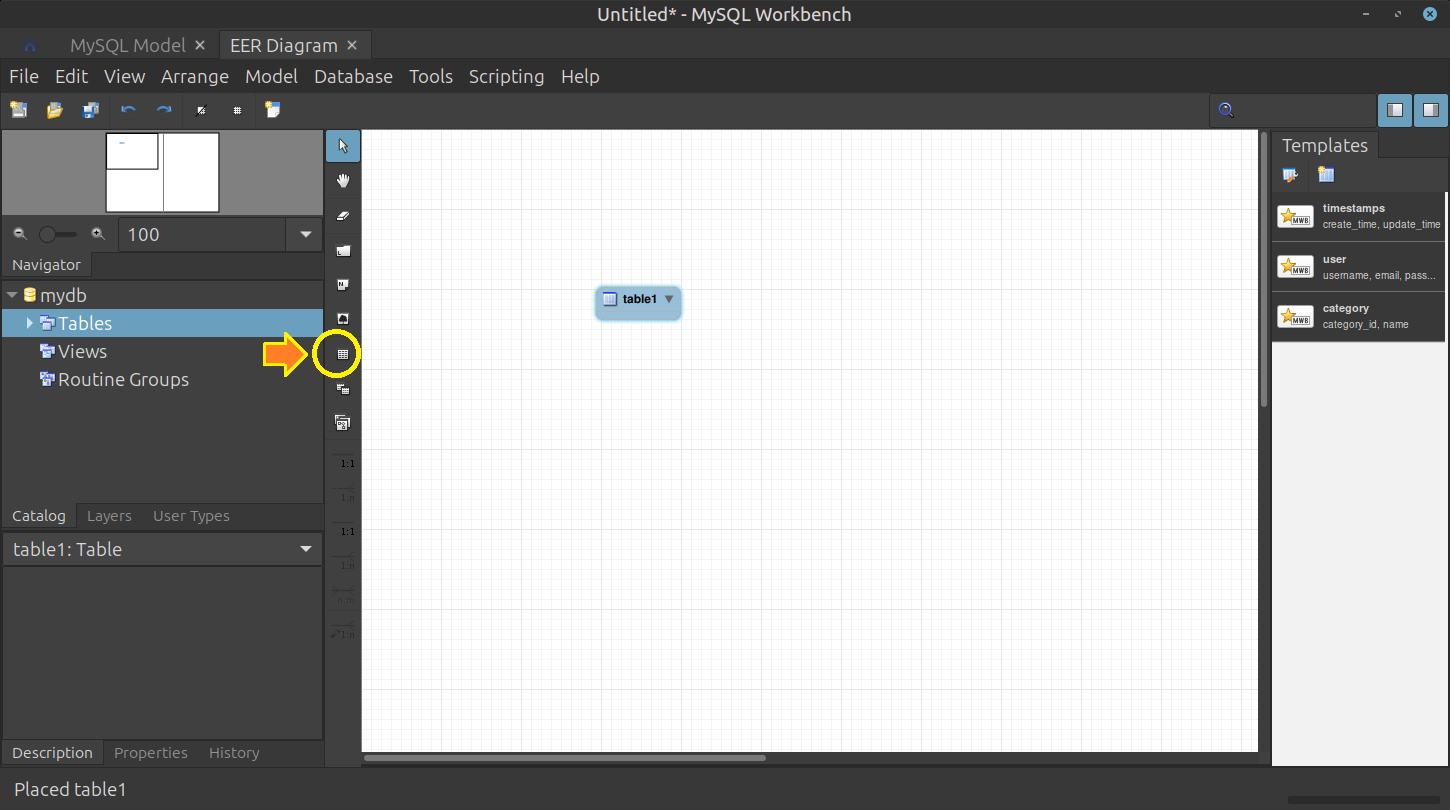
생성된
table1더블 클릭 🡲 화면 하단에 상세 속성을 편집할 수 있는 워크스페이스가 열림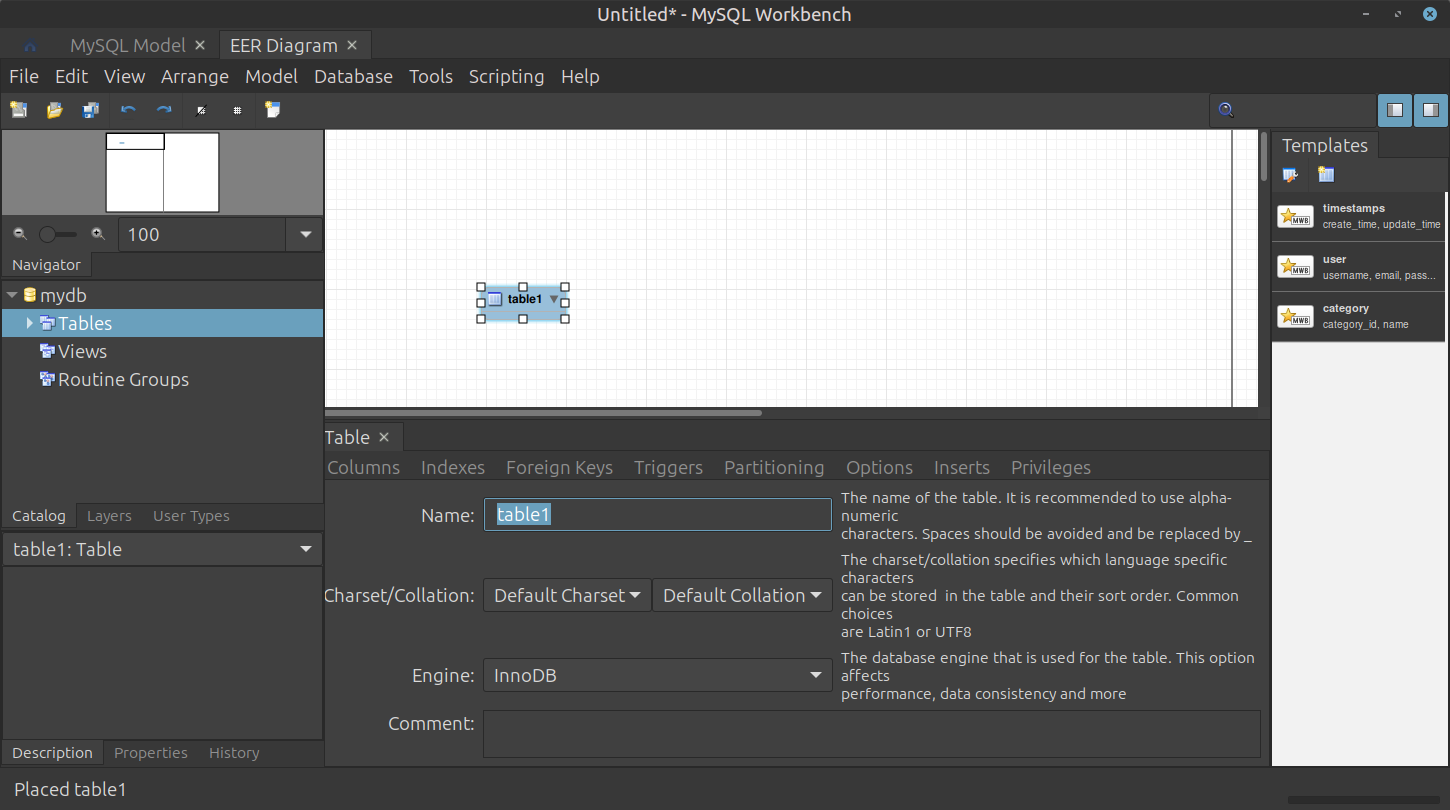
Table Name을
customer로 변경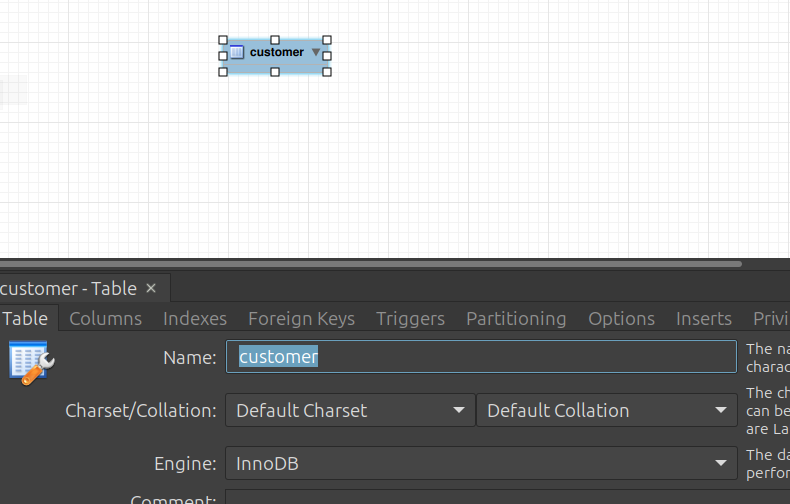
아래 Columns 탭의 빈 칸을 더블 클릭하여 다음과 같이 속성을 차례대로 추가
Column Name Data Type PK NN AI 비고 id INT ✅ ✅ ✅ 고유 일련번호 (자동 증가) name VARCHAR(45) ✅ 고객 이름 (필수 입력) email VARCHAR(100) 고객 이메일 (선택 입력) 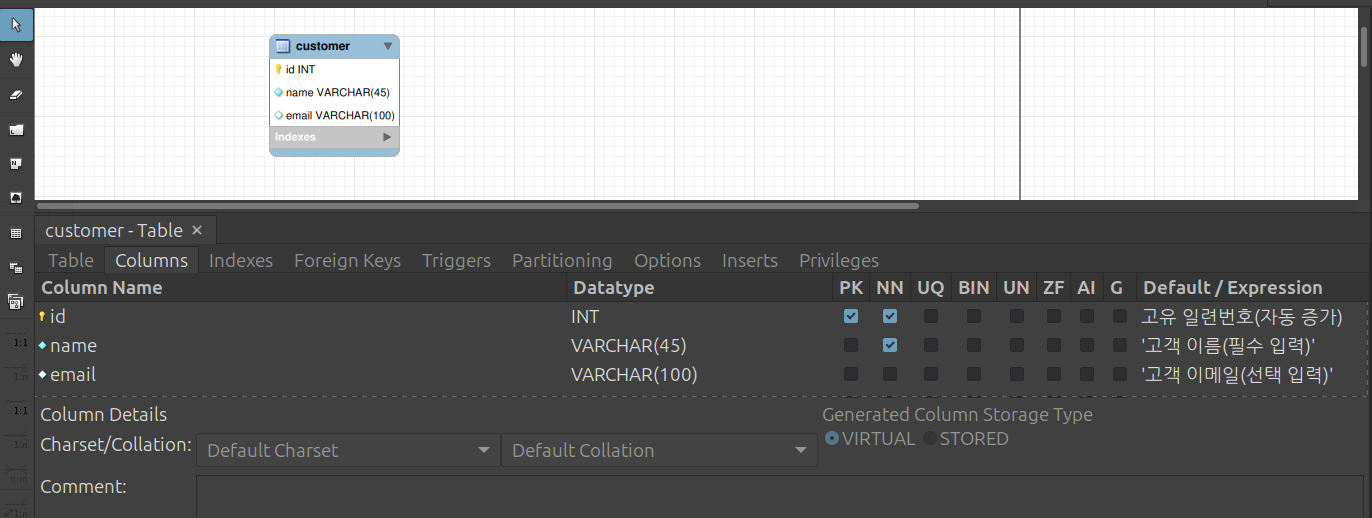
- 체크박스 용어 정리:
- PK (Primary Key): 주식별자(기본키)
- NN (Not Null): 필수 입력 항목 (빈 값 허용 안 함)
- AI (Auto Increment): 시스템이 순번을 자동으로 1씩 증가시킴 (인공키 전략)
- 3단계: ‘주문(Order)’ 엔터티(테이블) 설계
- 왼쪽 툴바에서 사각형 아이콘(
T)을 누르기 - 캔버스 다른 빈 곳을 클릭하여
table2를 만듦 table2를 더블 클릭하여 하단 편집창을 열기- Table Name을
order로 변경(SQL 예약어와 겹칠 수 있으므로 실무에서는 보통orders로 많이 사용) - Columns 탭에 아래 속성을 추가
Column Name Data Type PK NN AI 비고 id INT ✅ ✅ ✅ 주문 고유 번호 order_date DATETIME(45) ✅ 주문이 일어난 날짜와 시각 amount INT ✅ 총 주문 금액 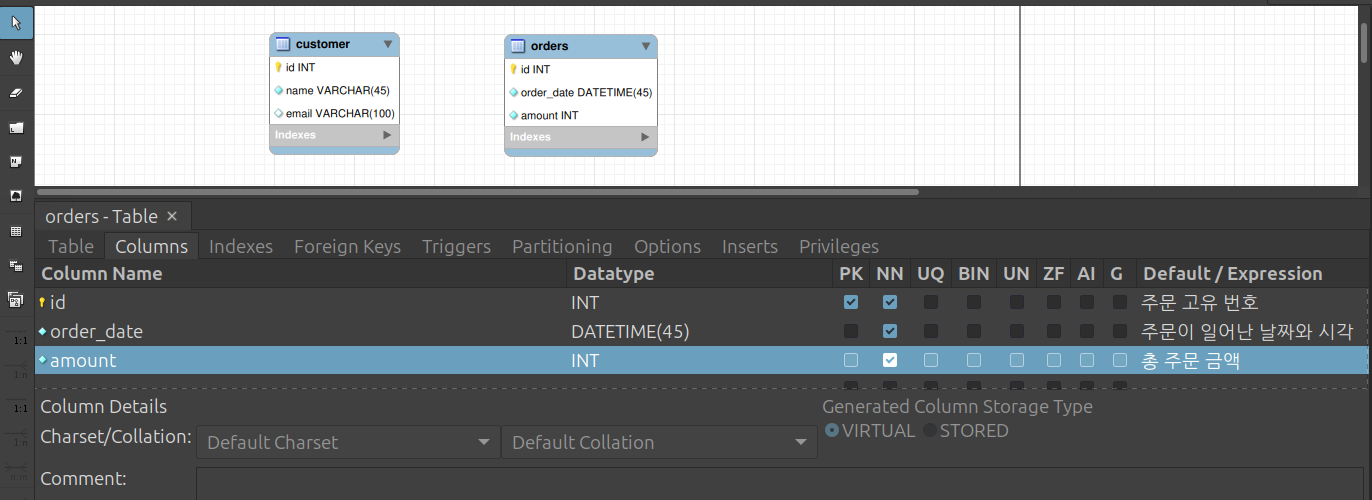
- 왼쪽 툴바에서 사각형 아이콘(
- 4단계: 까마귀 발 표기법으로 \(1:N\) 관계 연결하기 (핵심)
- 시나리오에서
- 한 명의 고객은 여러 번 주문할 수 있고,
- 가입 안 한 고객은 주문 불가
- 즉,
customer가 \(1\),order가 \(N\) 이 되며 필수적 비식별 관계가 됨
- 왼쪽 세로 툴바 하단에서 점선 모양의 [Place a Relationship Using Non-Identifying Relation (1:N)] 아이콘 클릭
- 마우스를 올리면
1:N Non-Identifying Relationship이라고 뜸
- 마우스를 올리면
- 반드시 자식 테이블(\(N\) 쪽)을 먼저 클릭하고, 부모 테이블(\(1\) 쪽)을 나중에 클릭
- 첫 번째 클릭:
order테이블 클릭 - 두 번째 클릭:
customer테이블 클릭
- 첫 번째 클릭:
- 클릭과 동시에 두 테이블 사이에 점선 관계선이 연결됨
order테이블 하단에customer_id라는 외래키(FK) 속성이 자동으로 생성 됨
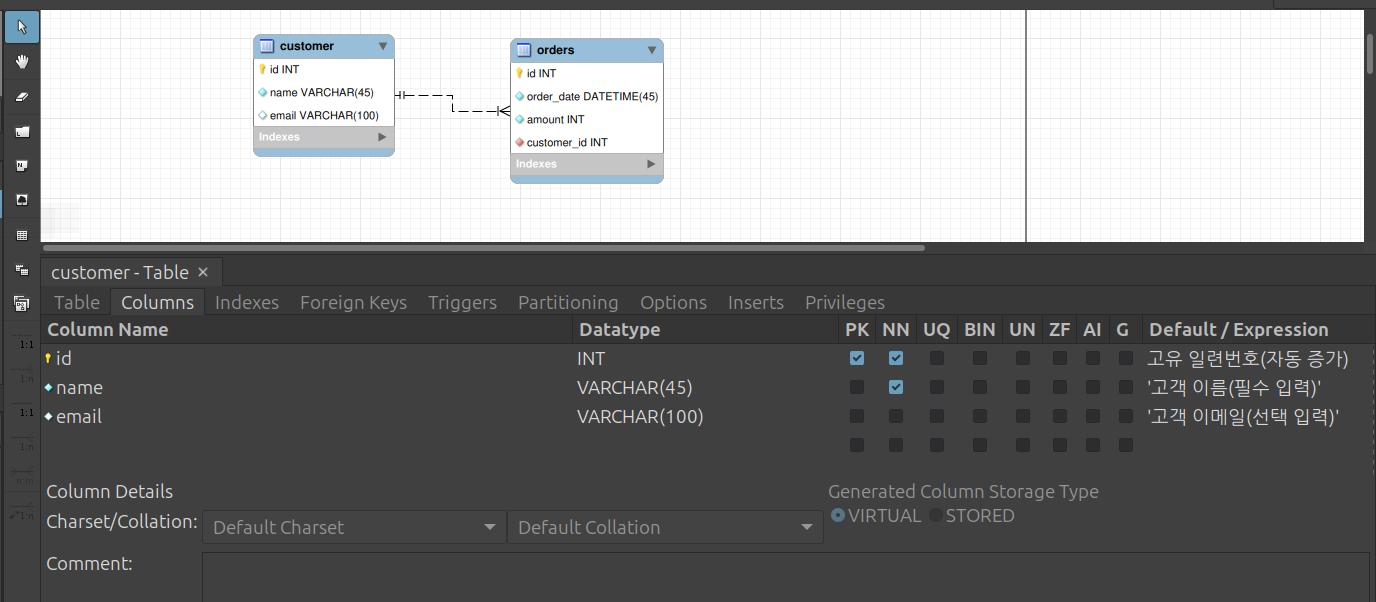
- 시나리오에서
- 5단계: 실제 로컬/원격 DB로 물리적 반영하기 (Forward Engineering)
- 그린 도면을 바탕으로 실제 MySQL 서버에 테이블을 집어넣을 차례
상단 메뉴에서 [Database] 🡲 [Forward Engineer…] 클릭
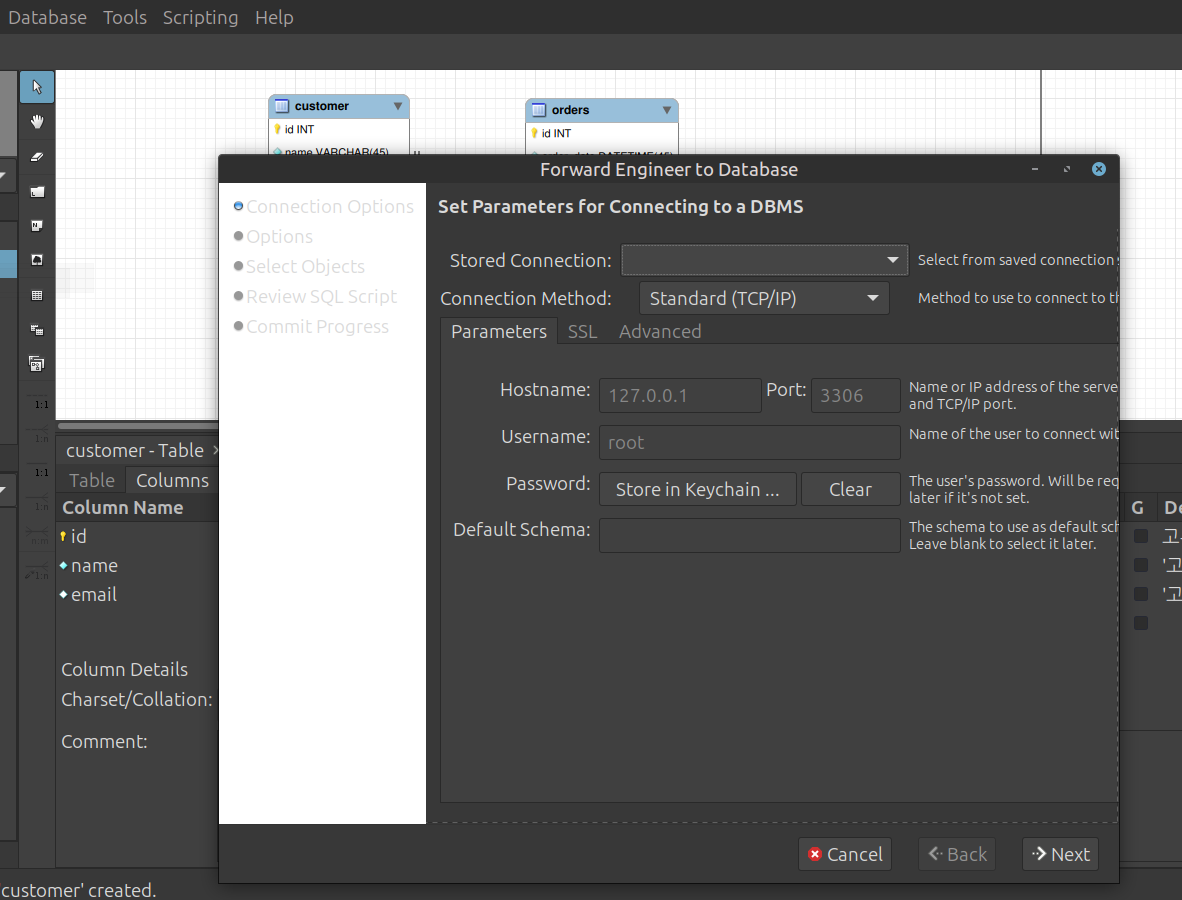
Connection Options: 접속할 MySQL 서버 정보(Stored Connection)를 선택하고 [Next]
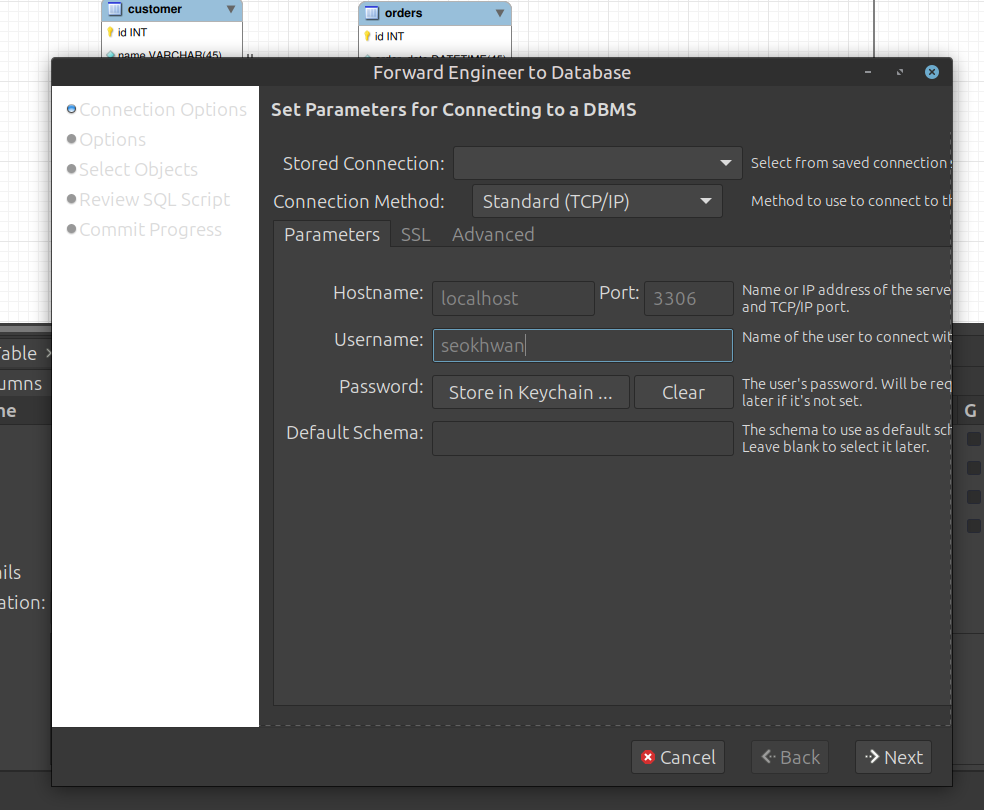
- Options: 기본 설정 그대로 두고 [Next]
Select Objects: Export MySQL Table Objects에 체크된 것을 확인하고 [Next]
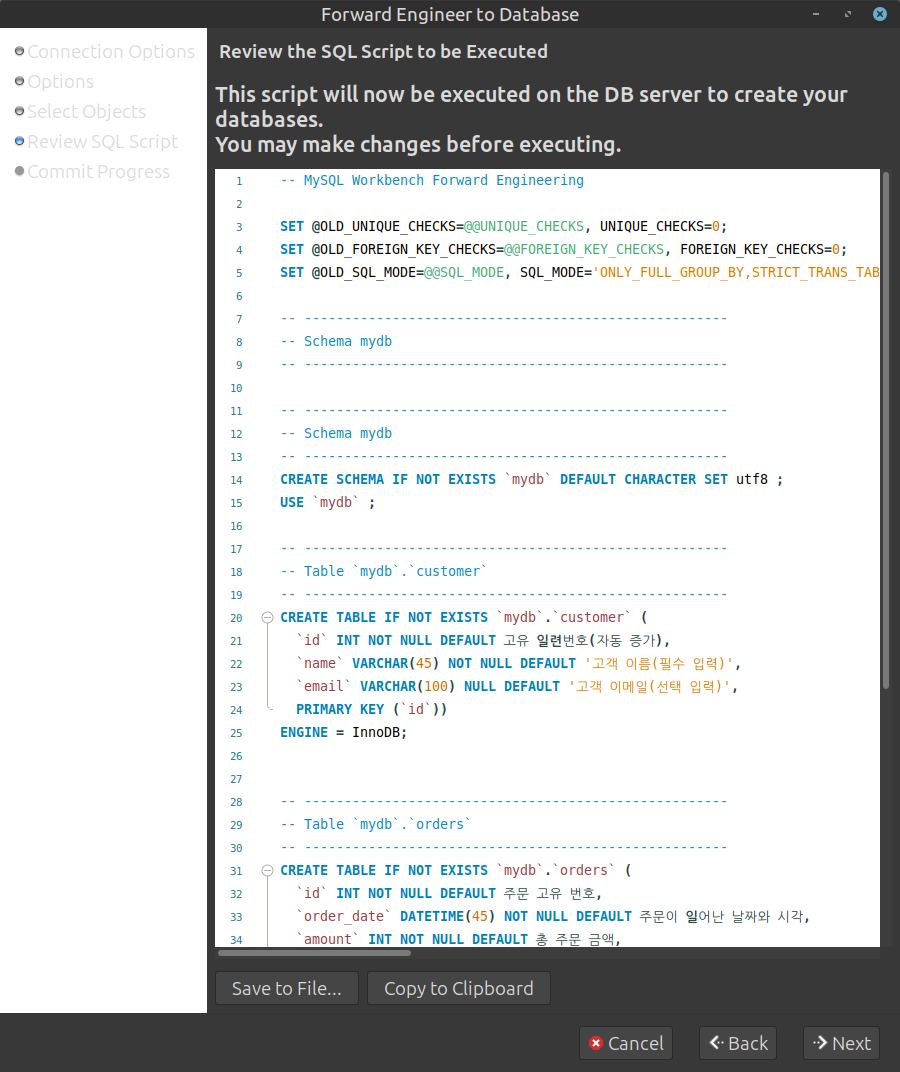
- Review Script:
- Workbench가 자동으로 만든 완벽한
CREATE TABLEDDL 스크립트가 화면에 출력됨 - 구조를 눈으로 확인한 뒤 [Next]
- Workbench가 자동으로 만든 완벽한
- DB 비밀번호를 요구하면 입력
Execution Progress: 모든 스크립트가 성공적으로 실행되었다는 메시지(
Forward Engineering Finished Successfully)가 뜨면 [Close]
- 최종 확인 및 검증
- Workbench 첫 메인 화면으로 돌아와 실제 가동 중인 MySQL Connection을 더블 클릭
- 왼쪽 Navigator 탭 🡲 Schemata에서 방금 밀어 넣은 데이터베이스를 확장
customer테이블과order테이블이 완벽하게 생성되어 있고,order테이블의 Foreign Keys 항목에fk_order_customer가 정밀하게 박혀 있는 것을 확인
4.2 까마귀 발 표기법
- 공식 명칭: IE(Information Engineering) 표기법
- 선의 끝 모양이 마치 까마귀 발가락을 닮았다고 하여 ‘까마귀 발 표기법 (Crow’s Foot Notation)’이라고 자주 부름
- 데이터 모델링에서 엔터티(Entity) 간의 관계(Relationship)를 시각적으로 표현할 때 전 세계적으로 가장 널리 쓰이는 표준 표기법
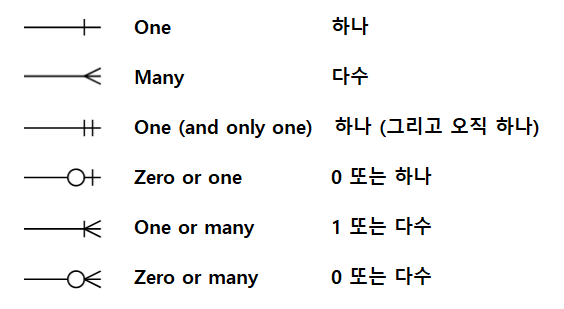
- 까마귀 발 표기법의 핵심 구조: 세 부위의 법칙
- 관계선(Relationship Line)의 양 끝단에 세 가지 기호(선, 동그라미, 세 갈래 발)를 조합하여 비즈니스 규칙을 표현
선의 끝부분을 읽을 때는 안쪽에서부터 바깥쪽으로 순서대로 해석
- 수량 / 사상수 (Cardinality)
- 관계선의 가장 바깥쪽 끝에 위치
한 엔터티가 다른 엔터티의 데이터 ‘몇 개’와 연결될 수 있는지를 나타냄
- 하나 ($1$):
- 직선 하나(
|)로 표시 - 정확히 1개의 데이터와만 매핑된다는 뜻
- 직선 하나(
- 여러 개 ($N$):
- 세 갈래로 갈라지는 까마귀 발 모양(
⤙)으로 표시 - 0개, 1개 또는 그 이상의 다수 데이터와 매핑될 수 있다는 뜻
- 세 갈래로 갈라지는 까마귀 발 모양(
- 필수성 / 선택성 (Optionality)
- 관계선의 수량 기호 바로 안쪽에 위치
상대방 데이터가 ‘반드시 존재해야 하는지(필수)’ 아니면 ‘없어도 되는지(선택)’를 나타냄
- 필수 (Mandatory):
- 직선 하나(
|)로 표시 - 상대방 데이터가 최소 1개는 무조건 존재해야 함
- 직선 하나(
- 선택 (Optional):
- 동그라미(
O)로 표시 - 상대방 데이터가 0개여도 상관없다는 뜻
- 동그라미(
- 4가지 핵심 기호 조합과 비즈니스 해석
- 실무에서 마주치는 모든 관계선은 아래 4가지 조합 안에서 결정됨
“최소 몇 개(안쪽 기호)에서 최대 몇 개(바깥쪽 기호)까지 매핑되는가?”의 관점으로 이해할 것
- 식별 관계(Identifying) vs 비식별 관계(Non-Identifying)
까마귀 발 표기법에서는 두 엔터티가 부모-자식 간에 얼마나 강하게 결합되어 있는지를 선의 종류(실선/점선)로 구분함
- 식별 관계 (Solid Line: 실선)
- 개념:
- 부모 엔터티의 주식별자(PK)가 자식 엔터티의 주식별자(PK)의 일부분으로 포함되는 관계
- 의미:
- 자식은 부모 없이는 독자적으로 존재할 수 없음 (강한 종속 관계)
- 예시:
주문테이블(PK: 주문번호)과주문상세테이블(PK: 주문번호 + 순번)- 부모인 ‘주문’ 데이터가 삭제되면 ‘주문상세’는 존재 의리가 없으므로 함께 사라져야 함
- 개념:
- 비식별 관계 (Dashed Line: 점선)
- 개념:
- 부모 엔터티의 주식별자(PK)가 자식 엔터티의 주식별자가 아닌 일반 속성(외래키: FK)으로만 포함되는 관계
- 의미:
- 부모가 없어도 자식은 독립적으로 존재할 수 있거나, 단순히 참조만 하는 관계 (약한 종속 관계)
- *예시:
부서테이블(PK: 부서코드)과사원테이블(PK: 사원번호 / FK: 부서코드)- 부서에 소속되지 않은 신입사원(FK가 Null)이 존재할 수 있음
- 부서가 사라져도 사원 데이터 자체가 사라지지는 않음
- 개념:
- 어느 쪽 엔터티를 기준으로 읽어야 하는가?
- 화살표 동사 리딩법
- 주가 되는 엔터티에서 출발하여 선을 따라 반대편 끝에 박힌 까마귀 발 기호를 읽음
고객에서주문쪽을 바라보면O⤙(Optional Many)가 보일 때 🡲 고객은 주문을 0번 또는 여러 번 할 수 있음주문에서고객쪽을 바라보면||(Mandatory One)가 보일 때 🡲 모든 주문은 반드시 한 명의 고유한 고객에 의해 이루어져야 함