CNN 모델
1. CNN 개요
- CNN (Convolutional Neural Network, 합성곱 신경망)
- 딥러닝 분야에서 이미지(Image) 및 영상(Video) 데이터를 처리하는 데 혁명적인 성공을 거둔 인공신경망의 한 종류
- 얼굴 인식, 자율주행, 의료 영상 분석 등 다양한 분야에서 핵심적인 역할
- CNN이 이미지에 효과적인 이유
- 이미지 처리 시 기존의 완전 연결 신경망(Fully Connected Network, FCN)의 한계
- 너무 많은 가중치 -이미지가 커질수록 모든 픽셀을 입력으로 사용하고
- 각 픽셀이 다음 계층의 모든 뉴런과 연결되면,
- 모델이 감당하기 어려울 정도로 가중치(파라미터)의 수가 폭증함
- 공간 정보 손실
- FCN은 이미지를 1차원 데이터로 펼쳐서 처리하기 때문에,
- 픽셀 간의 중요한 공간적 관계(예: 물체의 형상, 위치 등)를 학습하기 어려움
- 너무 많은 가중치 -이미지가 커질수록 모든 픽셀을 입력으로 사용하고
- CNN은 이러한 문제를 해결하기 위해 고안됨
- CNN은 우리 눈의 시각 피질이 작동하는 방식, 즉 시야의 특정 부분에 반응하는 뉴런들의 계층적 구조를 모방하여 설계됨
- 신경망 동작을 처리하기 위하여 컨볼루션 연산을 이용함
- CNN 모델에서는 컨볼루션 연산을 기반으로 각 영역(픽셀)이 서로 얼마나 일치하는지 계산하여 그 계산 결과를 활용함
- 이미지 처리 시 기존의 완전 연결 신경망(Fully Connected Network, FCN)의 한계
2. 뇌의 시각정보 처리 구조
- 눈과 망막의 구조
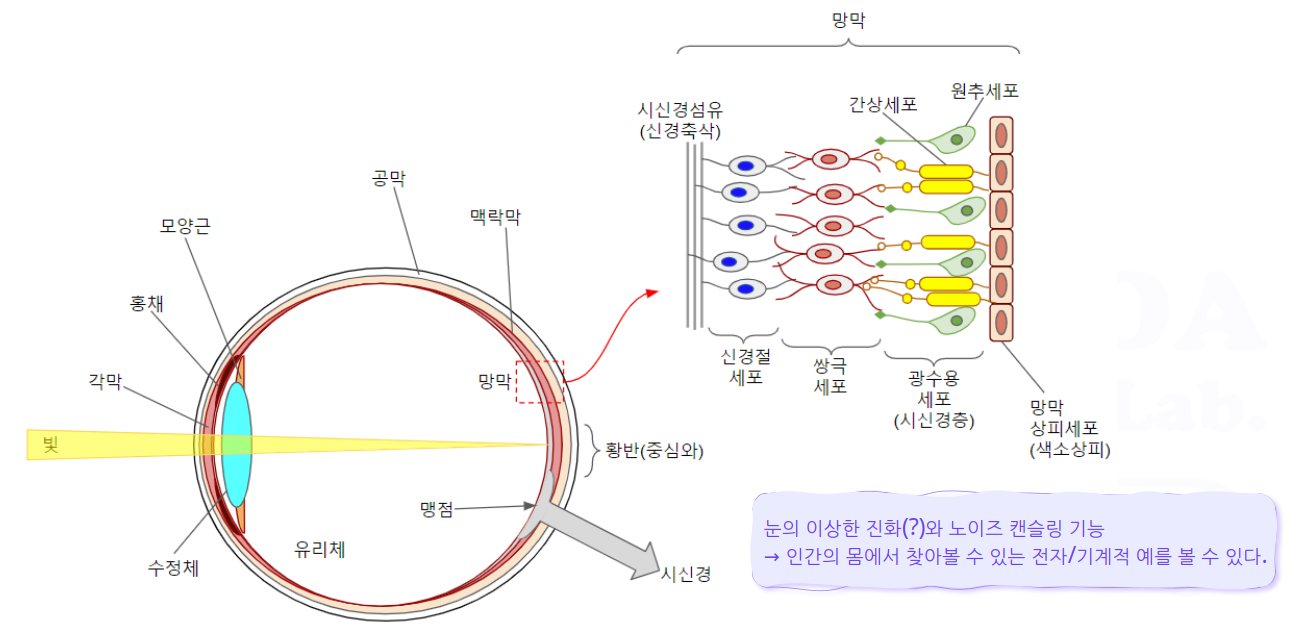
- 광수용세포는 빛에 대해 화학적으로 반응하는 광색소 함유
- 색채를 지각하는 원추세포, 명암을 탐지하는 간상세포
- 각 원추세포마다 다른 광색소를 함유함 (적색, 녹색, 청색)
- 빛이 광수용세포에 닿으면 광색소의 생화학적 특성에 따라 전위 변화가 발생하고 이온 투과성을 변경시킴
- 이온 투과성의 변화에 따라 광수용세포에서 신경전달물질이 분비되며 이로 인하여 전기 신호가 발생, 전달됨
- 시각 정보의 흐름
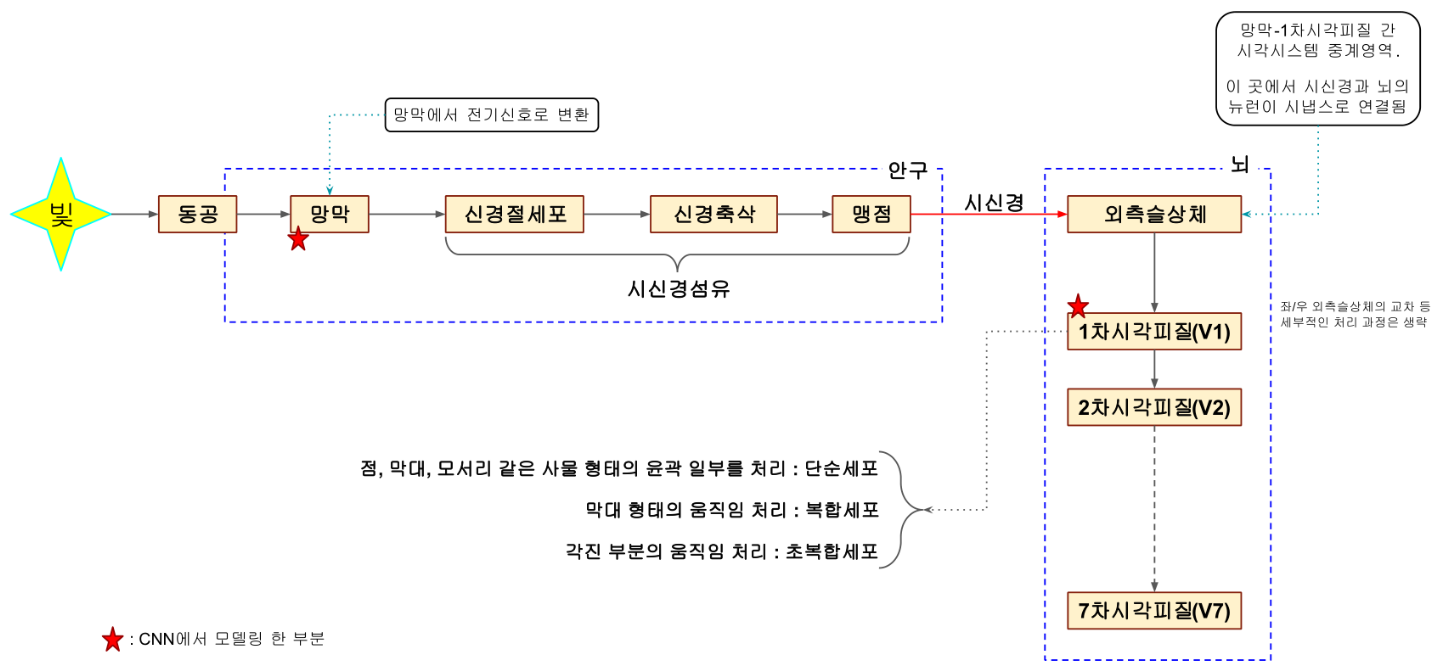
- 시각 피질
- 각 부위의 작동 방식
- 안구에서 신경절 세포는 마지막 출력에 해당하는 영역, 뉴런과 동일한 방식으로 동작함
- 망막에서 전기신호로 변환된 시각 정보는 신경절 세포의 반응률에 영향을 미침
- 신경절 세포의 반응률에 영향을 미치는 망막 표면의 영역을 해당 세포의 수용야(Receptive Field) 라고 하며 “ 중심흥분+ 주변억제” 와 “ 중심억제+ 주변흥분” 의 두 가지 형태가 존재함
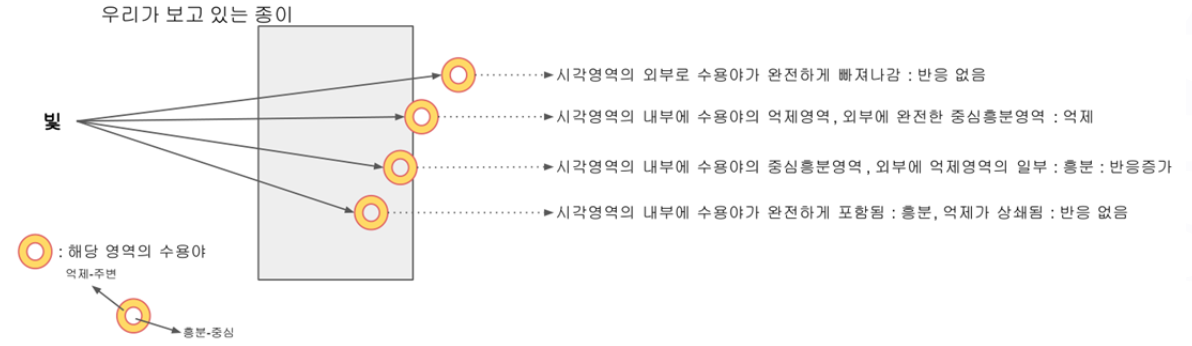
- 시각피질에서의 시각정보 처리
- 1차 시각피질의 세포들
- 단순세포
- 국소적인 영역을 보고, 단순한 패턴에 자극을 받는 세포 ➜ 점, 막대, 모서리 같은 사물 형태의 윤곽 일부를 처리
- 엄격한 위치 선택성을 가짐 (정확한 입력패턴에 반응)
- 복합세포
- 넓은 영역을 보고, 복잡한 패턴에 자극을 받는 세포 ➜ 막대 형태의 움직임 처리
- 초복합세포: 각진 부분(모서리)의 움직임 처리(복합세포, 초복합세포를 하나로 묶어서 보기도 함)
- 입력패턴을 조금 벗어나도 반응함
- 넓은 영역을 보고, 복잡한 패턴에 자극을 받는 세포 ➜ 막대 형태의 움직임 처리
- 단순세포
- 각 세포들은 수직으로 세워놓은 기둥 형태로 조직되어 있음( 시각피질에서만 이런 형태)
- 각 세포들은 서로 다른 방향의 자극에 대해 반응함
- 시각피질에서 이러한 기둥 조직에 의해 방향성 정보를 부호화 하는 것이 시각적 공간을 뉴런에 의해서 재구성하는데 매우 중요한 역할을 하는 것으로 추정됨
- 세포기둥은 세포들의 단순한 집합이 아니라 역동적 기능 단위임
단순세포와 복합세포의 반응성을 모형화하면…
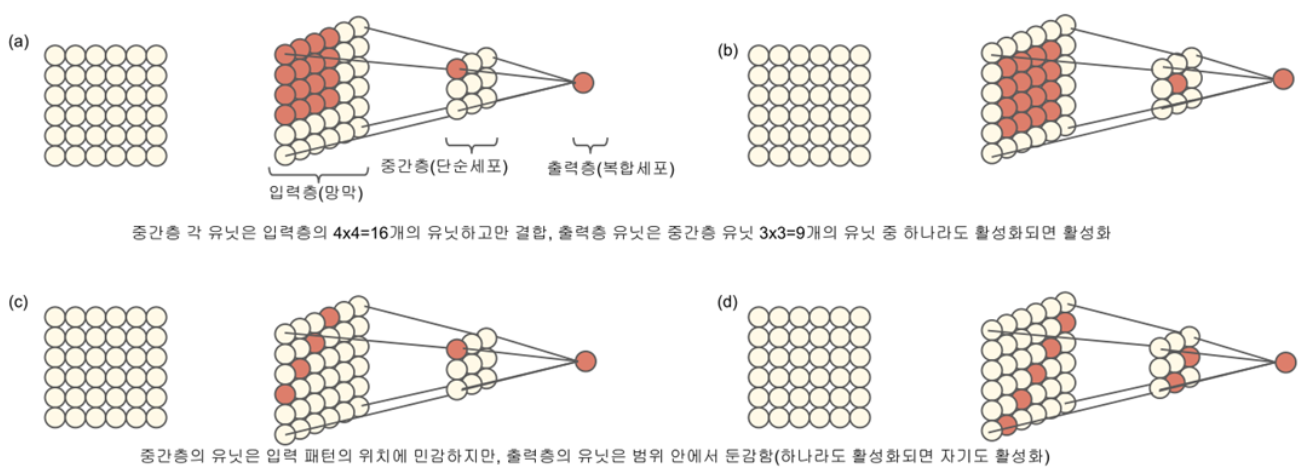
- 1차 시각피질의 세포들
- 각 부위의 작동 방식
- CNN 모델의 구상
- 눈과 시각피질 사이의 시각정보 처리 방식에서 개념 도입
- 망막에서의 빛 인식 영역 ➜ 입력층
- 시각피질의 단순세포에 의한 입력패턴 대응 영역 ➜ 중간층
- 시각피질의 복합세포에 의한 활성화 및 차원축소 영역 ➜ 출력층
- 해당 영역에 대한 수용야(감수영역이라고도 함) ➜ 필터
- 수용야의 영역 크기 ➜ 윈도우
- 수용야의 이동 범위 ➜ 스트라이드
- 수용야의 영역 처리 ➜ 패딩
- 시각 처리 신경망은 단순세포와 복잡세포가 층을 이루어 구성되어있고, 층간 연산에 따라 동작하는 것으로 관찰되고 있음
- CNN 모델은 이러한 과정을 반영하고 있음
- 눈과 시각피질 사이의 시각정보 처리 방식에서 개념 도입
- 시각 정보의 전달 경로
- CNN 모델과 비교해 볼것
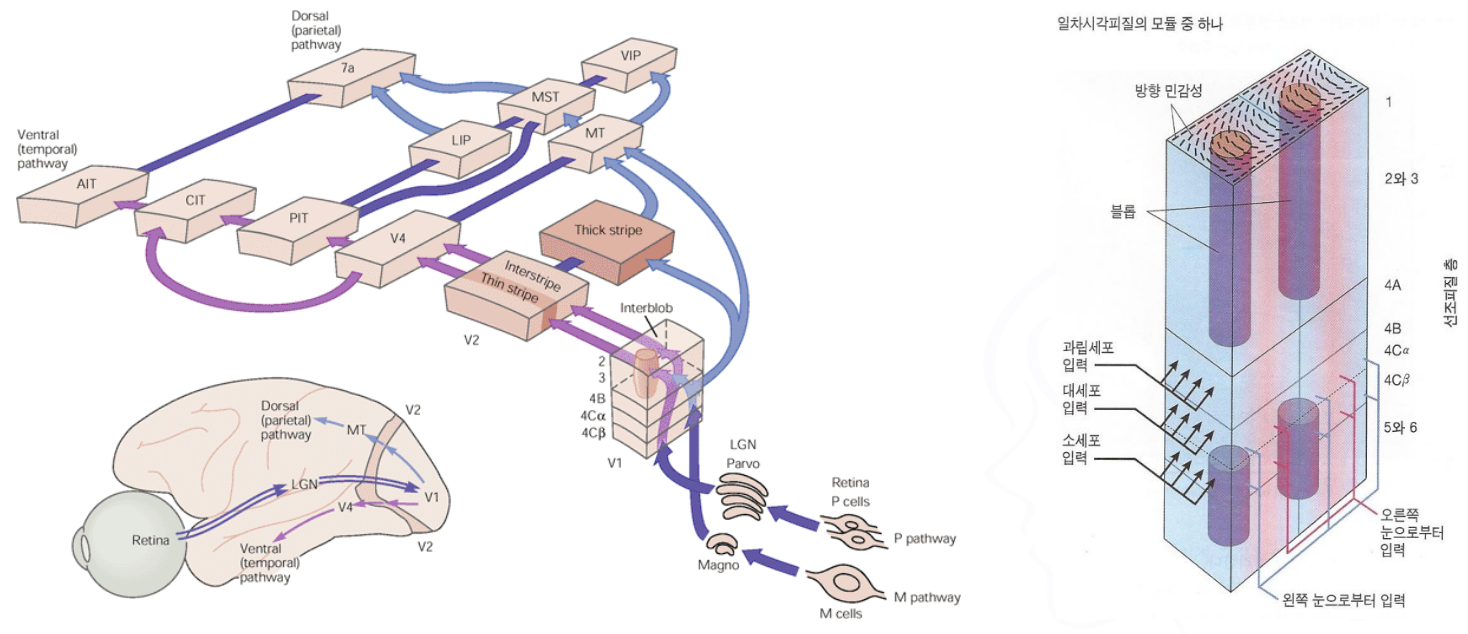 (그림출처: http://www.seehint.com/word.asp?no=13222)
(그림출처: http://www.seehint.com/word.asp?no=13222)
3. CNN의 핵심 구성 계층
- CNN은 크게 특징 추출 계층(Feature Extraction Layers)과 분류 계층(Classification Layers)으로 나눌 수 있음
- 이들은 각각 여러 개의 특정 계층들로 구성됨
3.1 컨볼루션 계층
- 컨볼루션 계층(Convolutional Layer)
- CNN의 가장 핵심적인 계층
- 이미지를 특정 시야로 훑으면서 특징을 찾아내는 연산
- 컨볼루션(Convolution, 합성곱)이란?
- 두 함수(또는 신호, 이미지 데이터)를 결합하여 새로운 함수를 생성하는 수학적 연산
- 두 개의 함수가 있을 때, 둘 중에서 하나의 함수를 반전, 이동(전이)시킨 후, 두 함수를 곱한(결합한) 결과를 적분하여 그 파형(그래프)을 얻는 연산 방법
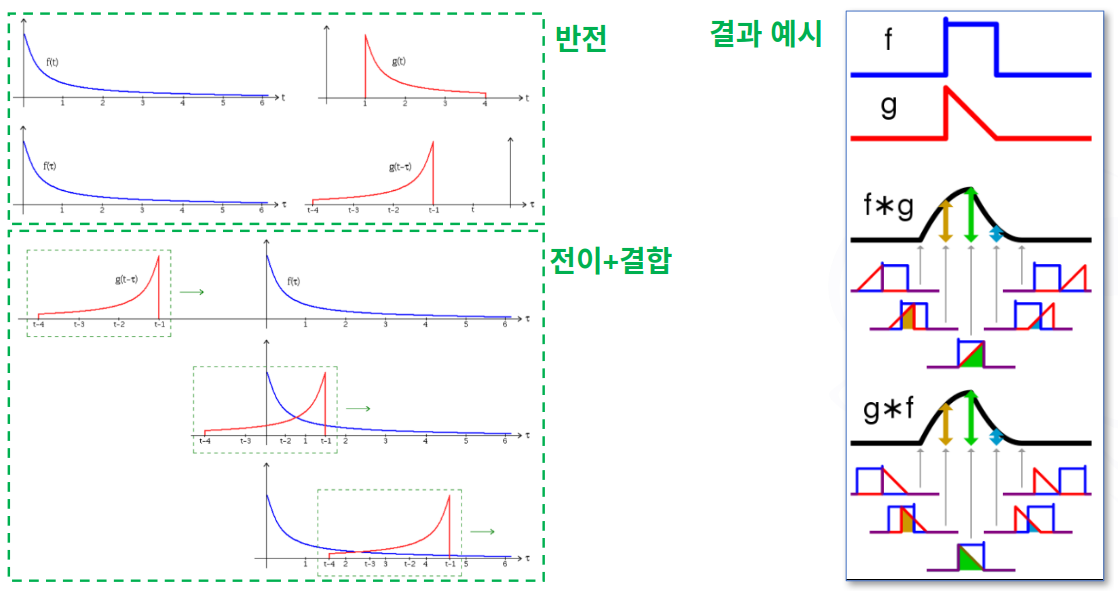 (그림출처: 위키피디아)
(그림출처: 위키피디아) - 특히 이미지 처리나 딥러닝(Convolutional Neural Network, CNN)에서 핵심적으로 사용됨
- 두 함수(또는 신호, 이미지 데이터)를 결합하여 새로운 함수를 생성하는 수학적 연산
- 컨볼루션 연산이 CNN 모델의 이미지 인식에 어떤 식으로 작용하나?
- CNN에서는 “하나의 함수가 다른 함수와 얼마나 일치하는가?”의 의미로 사용
- 하나의 필터(커널)에 대하여 이미지의 각 부분들이 필터와 얼마나 일치하는지 계산
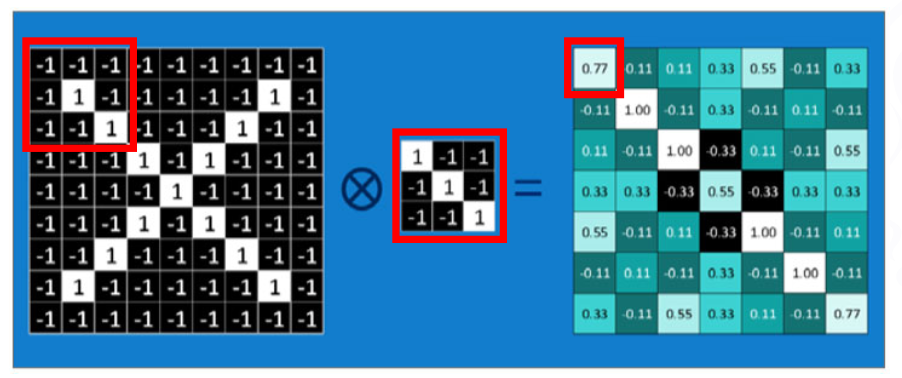
① 각 요소를 1:1 대응으로 곱한 후 총합 계산 : (-1 + 1 + 1) + (1 + 1 + 1) + (1 + 1 + 1) = 7
② 총합을 필터의 요소 개수(9개)를 기준으로 평균 계산 : 7 / 9 = 0.777777..(그림출처: 파이토치 첫걸음 (최건호 저, 한빛미디어))
- 정리하자면 이미지의 특정 부분을 자세히 들여다보면서 어떤 특징(가장자리, 색상 변화 등)이 있는지 분석하고,
그 분석 결과를 바탕으로 새로운 특징 요약 지도를 만들어낸다고 할 수 있음
- 필터 (Filter 또는 Kernel)
- 컨볼루션 계층의 핵심
- 필터
- 작은 크기의 행렬(예: 3x3, 5x5)
- 이미지의 특정 패턴(엣지, 코너, 색상 등)을 감지하는 역할
- 수많은 필터가 각기 다른 패턴을 감지하도록 학습됨
- 필터의 특징과 CNN에서의 필터
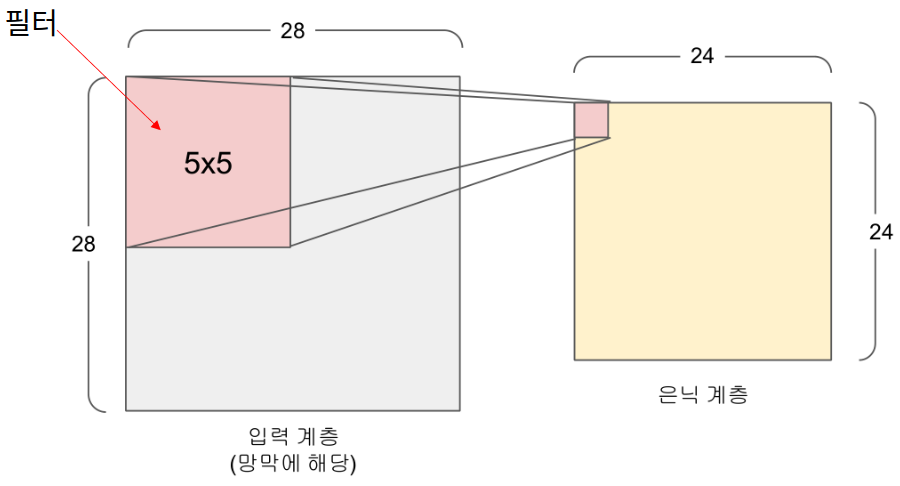
- 입력 계층과 은닉계층이 1:1 매핑되지 않음
- 시각피질의 수용야에 해당하는 윈도우는 정해진 크기만큼 좌표를 이동하며 입력계층의 데이터를 탐색함
- 픽셀 차이를 입력 계층과 겹쳐가며 이동하는데 이 간격을 스트라이드라고 함
- 필터의 크기(윈도우)가 5x5=25 인 경우는 25개의 픽셀이 하나의 뉴런에 대응됨
- 필터 사용의 장점
- 가중치의 수를 줄임으로써 전체 연산량을 대폭 감소시킬 수 있음
- 예를 들어, 입력층의 크기가 28x28 일때 기본 신경망의 경우 28x28=784 개의 가중치를 찾아야 하지만 Convolution Layer 에서는 5x5 개인 25 개의 가중치만 찾으면 됨
- 연산량의 대폭 감소로 학습이 더 빠르고 효율적으로 진행됨
- 단점
- 복잡한 특징을 가진 이미지의 분석이 어려움
- 보완책으로서 여러 개의 필터를 사용하며, 분석하고자 하는 내용에 따라 필터의 개수를 어떻게 정하는가 하는 것이 중요함
- 스트라이드 (Stride)
- 필터가 이미지 위를 이동하는 간격
- 스트라이드가 1이면 한 칸씩 이동하고, 2이면 두 칸씩 이동
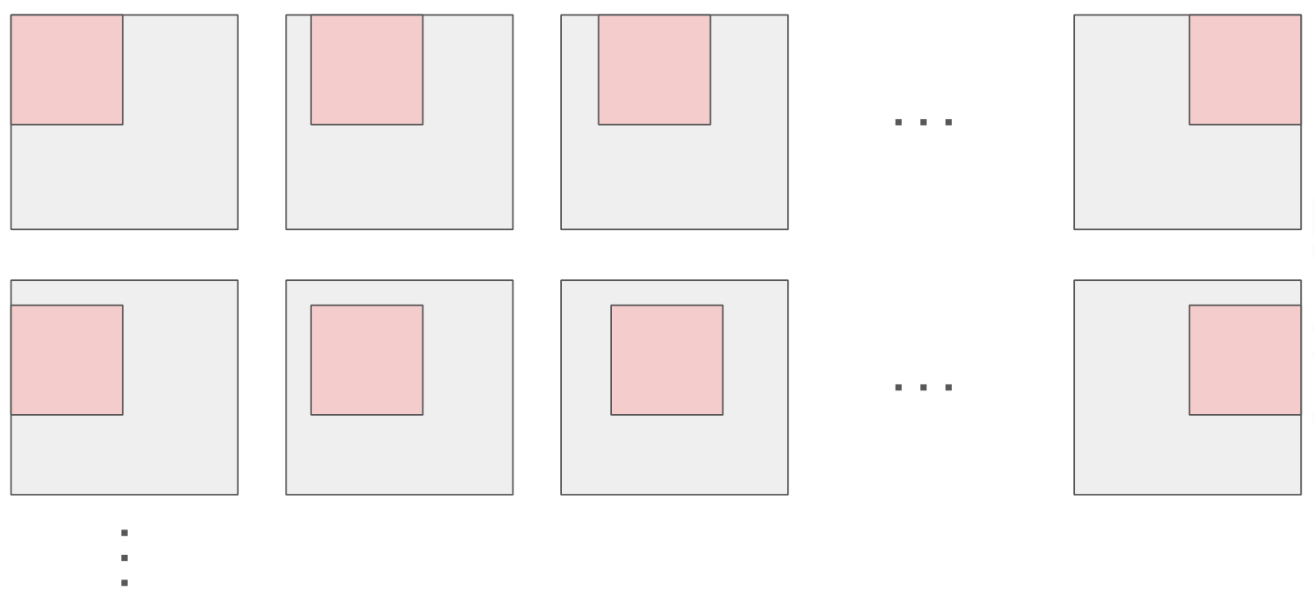
- 스트라이드가 커지면 특징 맵의 크기가 작아짐
- 필터가 이미지 위를 이동하는 간격
- 패딩 (Padding)
- 입력 이미지의 가장자리에 특정 값(주로 0)으로 채워 넣는 작업
- 패딩을 사용하면 컨볼루션 연산 후에도 특징 맵의 크기가 입력 이미지와 동일하게 유지할 수 있음
- 주로
valid또는same패딩 사용
- 주로
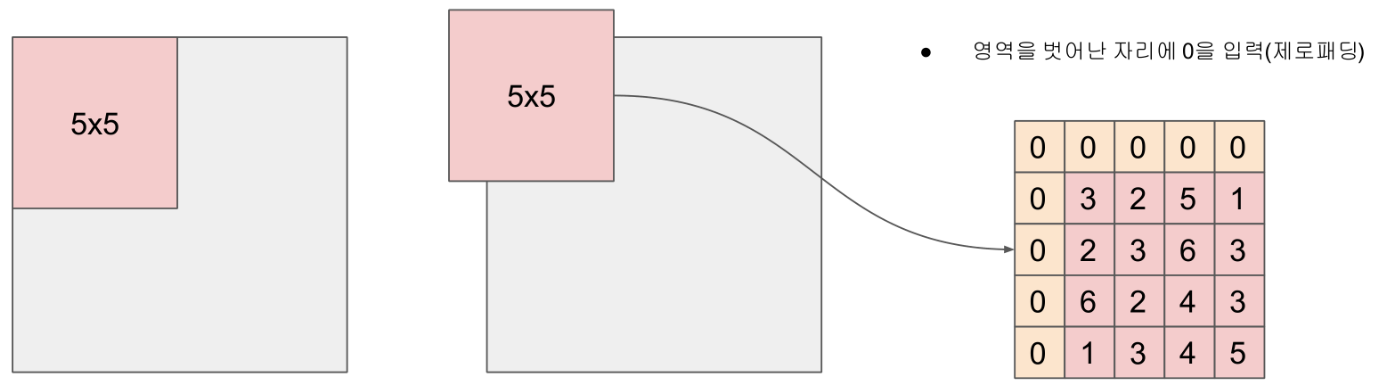
- CNN에서의 컨볼루션 연산 (Convolution Operation) 적용 방식
- 필터가 입력 이미지 위를 왼쪽 위부터 오른쪽 아래로 슬라이딩(Sliding)하며 이동
- 필터가 겹치는 이미지 영역의 픽셀 값들과 필터의 가중치들을
- 원소별로 곱하고(Element-wise Multiplication)
- 모두 더하여(Summation)
- 하나의 출력 값 도출
- 이 과정을 반복하여 필터가 이미지 전체를 훑으면
- 특징 맵 (Feature Map 또는 Activation Map)이 생성됨
- 이 특징 맵은 필터가 감지한 패턴이 이미지의 어느 위치에 얼마나 강하게 존재하는지를 나타냄
- 출력 크기 계산
\(((입력 크기 - 필터 크기 + 2 * 패딩) / 스트라이드) + 1\)
이미지에서 필터의 특징을 가진 영역을 어떻게 추출(인식)하나?
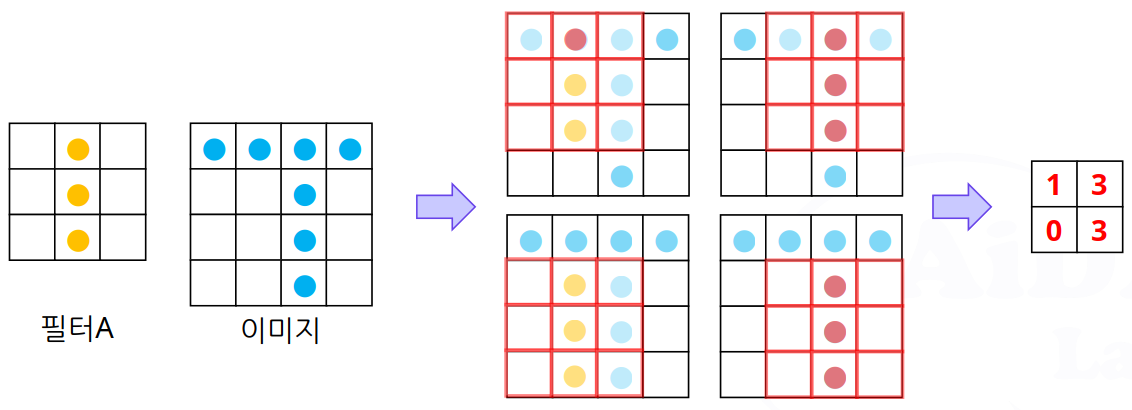
- 필터A: 수직의 edge를 검출하는 필터 ➜ 보다 큰 값이 있는 위치에 수직의 edge가 있다는 것을 의미함
- 각 층에서 Back Propagation을 수행할 때
- 예측 값과 실제 값을 비교한 오차를 정의(계산)한 후, 각 edge의 가중치를 갱신함
- 컨볼루션 계층(Convolution Layer) 정리
- Convolution, 즉 합성곱이란 이미지와 필터 사이에 정의되는 합성 곱 연산을 말함
- 이미지의 합성곱은 필터의 명암 패턴과 유사한 명암 패턴이 입력된 이미지의 어디에 있는지 검출하는 작용, 즉 필터가 나타내는 특징적인 명암 구조를 이미지로부터 추출하는 작용을 함
- 필터(커널이라고도 함)
- 입력층의 윈도우를 은닉층의 뉴런 하나로 압축할 때, 컨볼루션 계층에서는 윈도우의 크기만큼의 가중치와 1개의 편향 값(bias)을 적용
- 예를 들어 윈도우의 크기가 5x5라면 5x5개의 가중치와 1개의 편향 값이 필요함
- 이 5x5개의 가중치와 1개의 편향 값을 커널, 또는 필터라고 부름
- 필터는 해당 은닉층을 만들기 위한 모든 윈도우에 공통으로 적용됨
3.2 활성화 함수 계층
- 활성화 함수 계층 (Activation Function Layer)
- 컨볼루션 연산으로 얻은 특징 맵에 비선형성을 추가하는 계층
- 역할
- 신경망의 표현력을 높여 복잡한 패턴과 관계를 학습할 수 있게 함
- 주로 ReLU (Rectified Linear Unit) 사용
- ReLU의 작동 방식
- 입력 값이 0보다 작으면 0을 출력
- 0보다 크면 입력 값을 그대로 출력
- 간단한 계산으로 연산량이 적고,
- 0보다 작은 값을 0으로 만들어 스파스(sparse)한 활성화를 유도하여
- 학습 효율을 높임
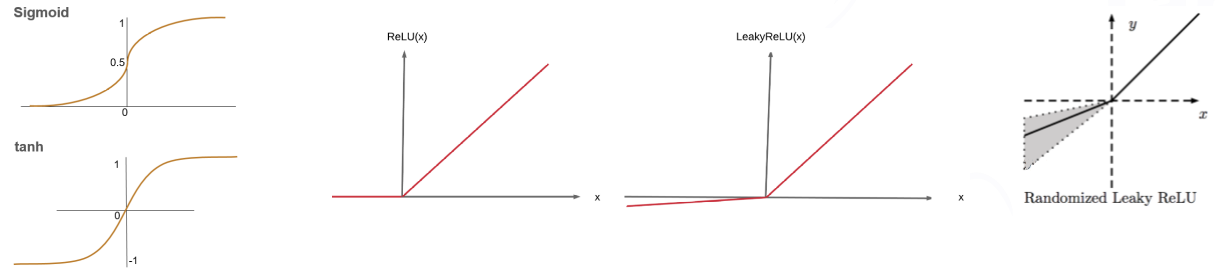
- ReLU의 작동 방식
- 신경망에서의 활성화 함수의 의미
- 실제 신경망에서는 우리 몸에서 반응할 필요가 있는 수준 까지만 신호를 전달하고 나머지의 신호는 무시 ➜ 비선형적 특징
- 합성곱 연산은 입력과 가중치로 이루어진 연산 ➜ 선형성을 가짐 ➜ 비선형 특성 부여를 위하여 활성화 함수가 필요함
3.3 풀링 계층
- 풀링 계층 (Pooling Layer)
- 특징 맵의 크기를 줄여 모델의 복잡성을 낮추고, 중요한 특징을 추출하는 계층
- 역할
- 공간적 다운샘플링 (Spatial Downsampling)
- 특징 맵의 가로세로 크기를 줄여 파라미터 수 감소
- 변동 불변성 (Translation Invariance)
- 이미지의 미세한 위치 변화에도 특징 감지 능력이 유지되도록 함
- 예: 물체가 약간 움직여도 같은 특징으로 인식
- 이미지의 미세한 위치 변화에도 특징 감지 능력이 유지되도록 함
- 과적합 방지 (Regularization)
- 불필요한 노이즈를 제거하고
- 모델의 일반화 성능을 향상
- 공간적 다운샘플링 (Spatial Downsampling)
- 주요 종류
- 맥스 풀링 (Max Pooling)
- 특정 영역 내에서 가장 큰 값(가장 두드러진 특징)만 추출
- 가장 많이 사용됨
- 평균 풀링 (Average Pooling)
- 특정 영역 내의 모든 값들의 평균을 추출
- 맥스 풀링 (Max Pooling)
- Convolution Layer 와 Pooling Layer 의 관계 및 역할
- 이미지 데이터, 즉 2 차원의 평면 행렬에서 지정한 영역의 값들을 하나의 값으로 압축
- 압축할 때
- Convolution Layer: 가중치와 편향을 적용
- Pooling Layer: 값들 중 하나를 선택해서 가져오는 역할
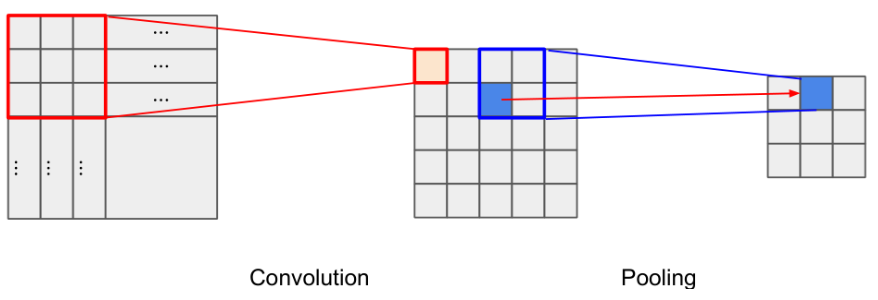
- Convolution Layer에서 해당 영역 내의 영상 위치가 다소 변경되더라도 인식할 수 있도록 함
- Max Pooling, Average Pooling이 많이 사용됨
3.4 완전 연결 계층
- 완전 연결 계층(Fully Connected Layer, FC Layer)
- 특징 추출 계층에서 얻은 고수준의 특징(High-level Features)을 기반으로 최종적인 분류나 회귀를 수행하는 계층
- 역할
- 특징 추출 계층에서 평면화(Flatten)된 특징들을 입력으로 받아,
- 각 뉴런을 이전 계층의 모든 뉴런과 연결
- 전통적인 신경망과 동일하게 작동하며, 최종 결정을 위한 복합적인 판단 수행
- 평면화 / 평활화 (Flattening)
- 컨볼루션 및 풀링 계층에서 2차원(또는 3차원) 형태였던 특징 맵들을 1차원 벡터로 쭉 펴는 작업
- 활용도
- 일반적으로 기존의 신경망에서 각 층별 연결에 사용되는 방식. 전결합층
- 모든 노드를 연결하므로 수많은 연산이 일어남
- CNN 의 특징은 모든 노드를 결합하지 않음으로써 연산량을 줄여 효율성을 높이는 방식
- 그럼 왜 사용하는가?
- 모든 노드를 연결하므로 1차원배열로 표시됨 ➜ 이미지의 공간정보가 사라짐
- 최종 결과값은 분류 결과 도출 ➜ 결국 마지막에 도출된 분류결과 Label을 선택하여야 함
- 최종 결과를 분류하기 위한 기반 정보는 모두 가지고 있어야 분류를 위한 SoftMax 함수를 사용할 수 있음
- 필수는 아니며 Convolution Layer 의 결과를 그대로 사용할 수도 있음
3.5 출력 계층
- 출력 계층 (Output Layer)
- 완전 연결 계층의 마지막 부분
- 최종 예측을 출력
- 분류 문제
- Softmax 활성화 함수
- 출력 값을 확률 분포로 변환하여 각 클래스에 속할 확률을 나타냄
- 가장 높은 확률을 가진 클래스가 최종 예측으로 결정
- 예: 0.8 확률로 ‘자동차’, 0.1 확률로 ‘보행자’ 등
- Softmax 활성화 함수
- 회귀 문제
- 활성화 함수를 사용하지 않거나,
- 선형 활성화 함수를 사용하여 연속적인 값을 직접 출력
- 예: 물체까지의 거리 12.5m
3.7 지역 대비 정규화
- LCN (Local Contrast Normalization)
- 자연물 이미지 등 주변의 조명, 카메라의 노출 등 환경 변화에 따라 이미지 전체의 밝기, 대비가 크게 변하는 경우 사용함
- 이미지 밝기 정규화의 방법
- 이미지의 집합(훈련 데이터)에 대한 통계치를 이용하여 이미지의 명암을 전체적으로 조절
- LCN
- 이미지 한 장, 한 장에 대하여 개별적으로 조절
- 고정된 가중치를 사용하므로 학습 가능한 파라미터는 없음
3.8 CNN 모델의 전체 구성
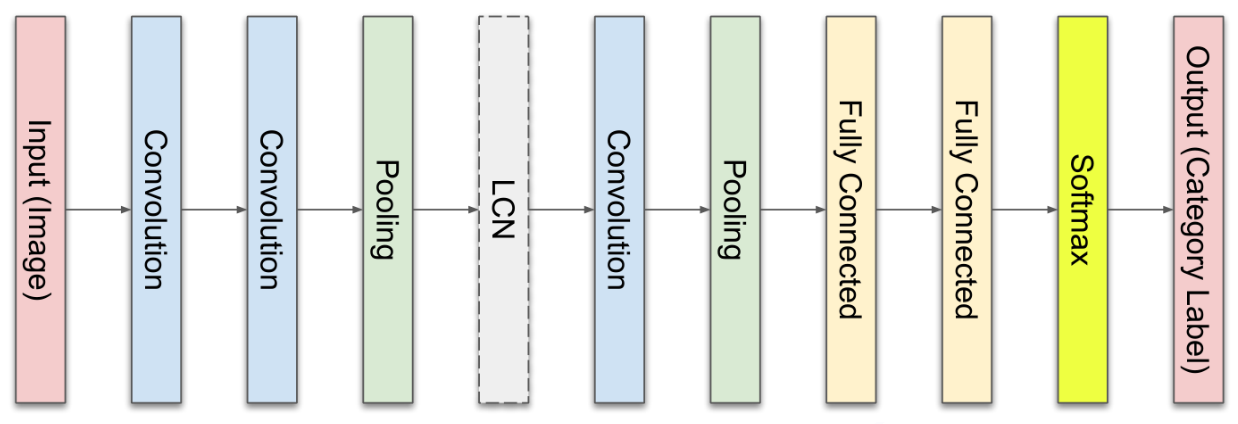
- 각 층들의 배치는 어떻게 정하나?
- 기준이 없음. 제맘대로 정함. 좋은 결과가 나올 때까지.
- 딥러닝 모델, CNN 모델 등은 비유하자면 인디언 기우제와 비슷함
- 초기 논문에서 제시된 구성의 예
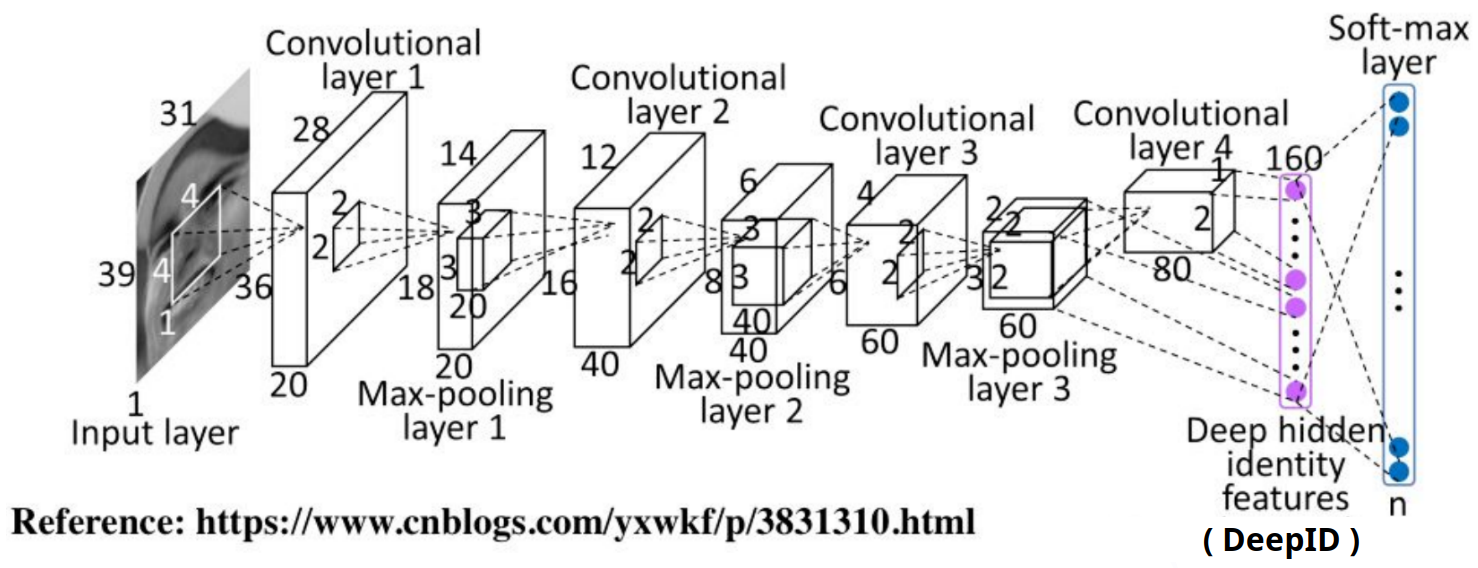
4. CNN의 동작 원리: 계층적 특징 학습
- CNN은 낮은 수준의 특징(Low-level Features)부터 높은 수준의 특징(High-level Features)까지 계층적으로 학습하는 방식으로 동작
- 초기 계층
- 이미지의 작은 영역에서 간단한 특징(엣지, 코너, 밝기 변화 등)을 감지
2 중간 계층 - 초기 계층에서 감지된 간단한 특징들을 조합하여 - 중간 수준의 특징(텍스처, 작은 부분의 형상 등)을 감지
- 마지막 계층 (특징 추출)
- 중간 계층의 특징들을 조합하여
- 고수준의 특징(물체의 일부분, 눈, 코, 귀 등)을 감지
- 분류 계층
- 추출된 고수준의 특징들을 바탕으로
- 최종적으로 이미지의 내용(객체, 상황)을 분류하거나 예측
- 이러한 계층적 학습 방식 덕분에 CNN은 이미지의 복잡하고 추상적인 특징들을 효과적으로 파악할 수 있음
5. 실습 코드
- 간단한 CNN 모델 구축 (MNIST 손글씨 분류)
- 가장 기본적인 CNN 모델 구축
- MNIST 손글씨 이미지 데이터셋(0-9까지의 숫자 이미지)을 분류
5.1 TensorFlow/Keras 버전
import tensorflow as tf
from tensorflow.keras import layers, models, datasets
import matplotlib.pyplot as plt
import numpy as np
print("TensorFlow Version:", tf.__version__)
# --- 1. 데이터셋 로드 및 전처리 ---
# MNIST 데이터셋 로드: 손글씨 숫자 이미지와 레이블 (0-9)
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 이미지 전처리:
# 1) 픽셀 값을 0-255 범위에서 0-1 범위로 정규화
train_images, test_images = train_images / 255.0, test_images / 255.0
# 2) CNN 모델은 입력 이미지에 채널(색상) 차원을 기대합니다.
# MNIST 이미지는 흑백이므로 (28, 28) -> (28, 28, 1)로 변경 (마지막 1은 채널 수)
train_images = train_images[..., np.newaxis].astype(np.float32)
test_images = test_images[..., np.newaxis].astype(np.float32)
print(f"학습 이미지 형태: {train_images.shape}, 학습 레이블 형태: {train_labels.shape}")
print(f"테스트 이미지 형태: {test_images.shape}, 테스트 레이블 형태: {test_labels.shape}")
# 데이터셋 시각화 (선택 사항)
# plt.figure(figsize=(10,10))
# for i in range(25):
# plt.subplot(5,5,i+1)
# plt.xticks([])
# plt.yticks([])
# plt.grid(False)
# plt.imshow(train_images[i], cmap=plt.cm.binary)
# plt.xlabel(train_labels[i])
# plt.show()
# --- 2. CNN 모델 구축 (Keras Functional API 사용) ---
def build_cnn_model_tf():
# 입력 계층: 28x28 픽셀, 1 채널 (흑백) 이미지
input_shape = (28, 28, 1)
# Keras Sequential API로 모델 정의 (간단한 모델 정의)
model = models.Sequential([
# 컨볼루션 계층 1
layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=input_shape),
layers.MaxPooling2D(pool_size=(2, 2)), # 풀링 계층 1
# 컨볼루션 계층 2
layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)), # 풀링 계층 2
# 컨볼루션 계층 3
layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'),
# 특징 맵을 1차원 벡터로 평탄화 (Fully Connected Layer에 입력하기 위함)
layers.Flatten(),
# 완전 연결 계층
layers.Dense(units=64, activation='relu'),
# 출력 계층 (클래스 10개, Softmax 활성화 함수로 확률 분포 출력)
layers.Dense(units=10, activation='softmax')
])
return model
model_tf = build_cnn_model_tf()
# 모델 구조 요약
model_tf.summary()
# --- 3. 모델 컴파일 및 학습 ---
# 컴파일: 모델 학습에 필요한 옵션 설정 (최적화 함수, 손실 함수, 평가 지표)
model_tf.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])
# 학습: 학습 데이터로 모델 훈련
print("\n--- TensorFlow CNN 모델 학습 시작 ---")
history_tf = model_tf.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
print("--- TensorFlow CNN 모델 학습 완료 ---")
# --- 4. 모델 평가 및 결과 시각화 ---
test_loss_tf, test_acc_tf = model_tf.evaluate(test_images, test_labels, verbose=2)
print(f"\nTensorFlow 테스트 정확도: {test_acc_tf:.4f}")
# 학습 과정 시각화
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history_tf.history['accuracy'], label='Training Accuracy')
plt.plot(history_tf.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('TensorFlow Model Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history_tf.history['loss'], label='Training Loss')
plt.plot(history_tf.history['val_loss'], label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('TensorFlow Model Loss')
plt.legend()
plt.show()
# 예측 (선택 사항)
# predictions = model_tf.predict(test_images[:5])
# predicted_classes = np.argmax(predictions, axis=1)
# print(f"\n예측: {predicted_classes}")
# print(f"실제: {test_labels[:5]}")
5.2 PyTorch 버전
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
print("PyTorch Version:", torch.__version__)
# --- 1. 데이터셋 로드 및 전처리 ---
# 데이터 전처리를 위한 변환 정의
# ToTensor: 이미지를 PyTorch Tensor로 변환하고 픽셀 값을 0-1 범위로 정규화 (PIL Image -> Tensor)
# Normalize: 평균 0, 표준편차 1로 추가 정규화 (필수는 아니지만 모델 학습에 도움)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # MNIST 데이터셋의 평균과 표준편차
])
# MNIST 데이터셋 로드
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# DataLoader를 사용하여 데이터 배치 단위로 로드
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1000, shuffle=False)
# 데이터셋 형태 확인 (배치, 채널, 높이, 너비)
sample_images, sample_labels = next(iter(train_loader))
print(f"학습 이미지 배치 형태: {sample_images.shape}, 학습 레이블 배치 형태: {sample_labels.shape}") # (Batch, Channel, Height, Width)
# --- 2. CNN 모델 구축 (PyTorch nn.Module 사용) ---
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 컨볼루션 계층 1: 입력 채널 1 (흑백), 출력 채널 32, 필터 3x3
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3)
# 컨볼루션 계층 2: 입력 채널 32, 출력 채널 64, 필터 3x3
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3)
# 맥스 풀링 계층
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 완전 연결 계층 (컨볼루션/풀링 후 Flatten된 특징 맵 크기에 따라 입력 차원 결정 필요)
# MNIST 28x28 이미지 기준으로 계산:
# conv1: (28-3+1) = 26x26
# pool1: 26/2 = 13x13
# conv2: (13-3+1) = 11x11
# pool2: 11/2 = 5x5 (내림) -> 64 채널 * 5 * 5 = 1600
self.fc1 = nn.Linear(in_features=64 * 5 * 5, out_features=128)
self.fc2 = nn.Linear(in_features=128, out_features=10) # 출력 클래스 10개 (0-9)
def forward(self, x):
# conv1 -> ReLU -> pool1
x = self.pool(F.relu(self.conv1(x)))
# conv2 -> ReLU -> pool2
x = self.pool(F.relu(self.conv2(x)))
# 특징 맵 평탄화 (배치 차원을 제외하고 1차원으로)
x = x.view(-1, 64 * 5 * 5)
# fc1 -> ReLU
x = F.relu(self.fc1(x))
# fc2 (출력)
x = self.fc2(x)
return x
# 모델 인스턴스 생성
model_pt = SimpleCNN()
# GPU 사용 가능 시 GPU로 모델 이동
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_pt.to(device)
# 모델 구조 요약 (torchsummary 사용 시 더 자세히 볼 수 있지만, 여기서는 간단히)
print("\n--- PyTorch CNN 모델 구조 ---")
print(model_pt)
# --- 3. 모델 컴파일 및 학습 ---
# 손실 함수 (Loss Function): 다중 클래스 분류에는 CrossEntropyLoss 사용
criterion = nn.CrossEntropyLoss()
# 최적화 함수 (Optimizer): Adam 사용
optimizer = optim.Adam(model_pt.parameters(), lr=0.001)
# 학습 함수
def train_model(model, device, train_loader, optimizer, epoch):
model.train() # 모델을 학습 모드로 설정
running_loss = 0.0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device) # 데이터를 해당 디바이스로 이동
optimizer.zero_grad() # 이전 그래디언트 초기화
output = model(data) # 순전파
loss = criterion(output, target) # 손실 계산
loss.backward() # 역전파
optimizer.step() # 가중치 업데이트
running_loss += loss.item()
if batch_idx % 100 == 0: # 100 배치마다 로그 출력
print(f'Epoch: {epoch}, Batch: {batch_idx}/{len(train_loader)}, Loss: {loss.item():.6f}')
return running_loss / len(train_loader)
# 평가 함수
def test_model(model, device, test_loader):
model.eval() # 모델을 평가 모드로 설정 (dropout, batchnorm 비활성화)
test_loss = 0
correct = 0
with torch.no_grad(): # 그래디언트 계산 비활성화 (메모리 절약, 속도 향상)
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item() # 배치당 손실 누적
pred = output.argmax(dim=1, keepdim=True) # 가장 높은 확률을 가진 클래스 예측
correct += pred.eq(target.view_as(pred)).sum().item() # 맞춘 개수 카운트
test_loss /= len(test_loader.dataset) # 평균 손실
accuracy = 100. * correct / len(test_loader.dataset)
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')
return test_loss, accuracy
# 학습 시작
epochs_pt = 5
train_losses_pt = []
test_losses_pt = []
test_accuracies_pt = []
print("\n--- PyTorch CNN 모델 학습 시작 ---")
for epoch in range(1, epochs_pt + 1):
train_loss = train_model(model_pt, device, train_loader, optimizer, epoch)
train_losses_pt.append(train_loss)
test_loss, test_accuracy = test_model(model_pt, device, test_loader)
test_losses_pt.append(test_loss)
test_accuracies_pt.append(test_accuracy)
print("--- PyTorch CNN 모델 학습 완료 ---")
# --- 4. 모델 평가 및 결과 시각화 ---
# 학습 과정 시각화
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs_pt + 1), test_accuracies_pt, label='Test Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('PyTorch Model Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs_pt + 1), train_losses_pt, label='Training Loss')
plt.plot(range(1, epochs_pt + 1), [l * test_loader.batch_size for l in test_losses_pt], label='Test Loss (rescaled)') # 테스트 로스 스케일 맞춰서
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('PyTorch Model Loss')
plt.legend()
plt.show()
# 예측 예시 (선택 사항)
# data, target = next(iter(test_loader))
# data, target = data.to(device), target.to(device)
# output = model_pt(data)
# pred = output.argmax(dim=1, keepdim=True)
# print(f"예측: {pred.flatten()[:5].tolist()}")
# print(f"실제: {target[:5].tolist()}")
- CNN은 이미지 및 영상 인식 분야에서 압도적인 성능을 보여주며 다양한 혁신을 이끌어 왔음
- 특히 자율주행에서는 차선 인식, 객체 탐지, 신호등 및 표지판 인식, 도로 상황 분류 등 거의 모든 ‘인지’ 단계에서 CNN 기반 모델이 사용됨
- CNN의 구조와 동작 원리는 딥러닝 기반 컴퓨터 비전 기술을 이해하고 활용하는 데 있어 가장 중요한 기초 지식이 될 것이므로
- 필터와 풀링이 이미지를 어떻게 ‘이해’하는지, 그리고 이 과정이 계층적으로 어떻게 복잡한 패턴을 찾아내는지 명확히 이해할 것