YOLO 모델
1. YOLO 개요
1.1 YOLO란?
- 실시간 객체 탐지(Object Detection)를 위해 개발된 대표적인 딥러닝 모델
- 이름(YOLO: You Only Look Once, 한 번만 본다) 그대로 이미지를 단 한 번의 네트워크 통과로 객체의 위치(바운딩 박스)와 종류(클래스)를 동시에 예측하는 효율적인 방식을 채택하고 있음
1.2 왜 YOLO인가?
- CNN과 R-CNN (Regions with CNN)
- CNN은 너무 많은 연산을 요구함 ➜ 매우 느린 처리 속도
- RCNN: CNN 처리 이전에 인식하기 원하는 물체가 있을 가능성이 높은 후보 영역(Region)을 선택하는 방식
- 선택 영역(Region)에만 CNN 적용 ➜ 성능향상 효과
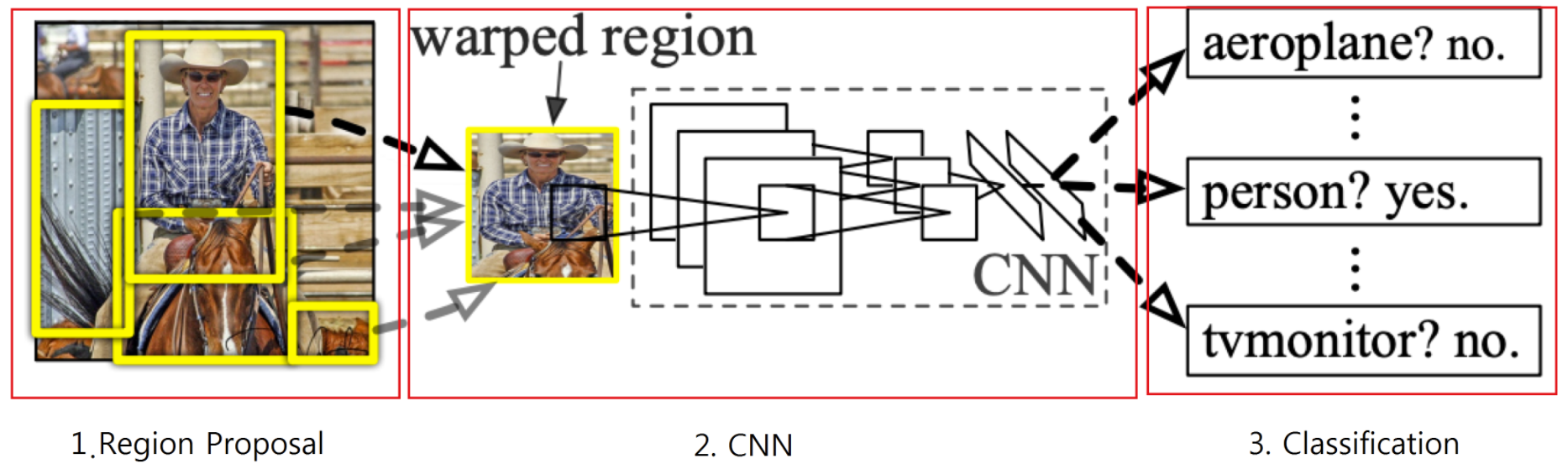
- R-CNN 모델의 프로세스
- 이미지 입력
- 후보영역 추출
- 다양한 방법이 제안되고 있음
- 딥러닝의 영역이 아닌 데이터 정규화의 영역에 가까움(CNN내부의 LCN과 비슷한 개념)
- 후보영역 추출방법의 개선으로 Fast-RCNN / Faster-RCNN 등의 모델 등장
- CNN 특징 계산
- 영역 분류
- CNN 계열 모델의 성능 비교
- CNN < R-CNN < Fast-RCNN < Faster-RCNN
- Faster-RCNN의 처리 방식
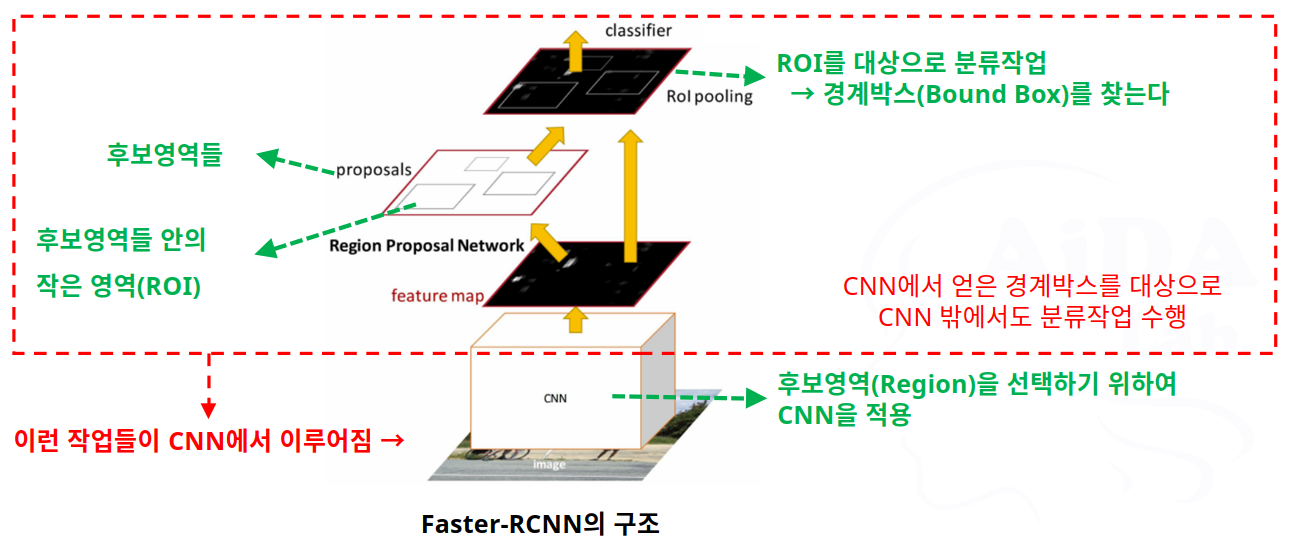
- 그러나 Faster-RCNN 모델도 실시간 처리에는 느려서 사용하기 어려움
- R-CNN 계열이 느린 이유
- 제안하는 후보 영역의 수가 너무 많음
- 후보 영역의 제안 과정에서도 부하가 큼
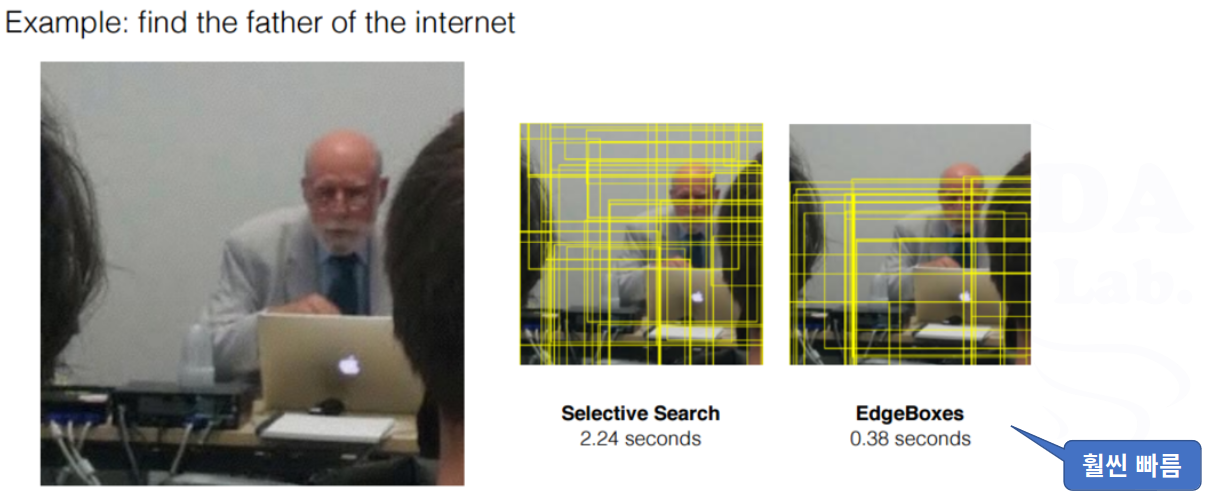
- 경계박스를 찾는 방법
Proposal 방식
Grid 방식
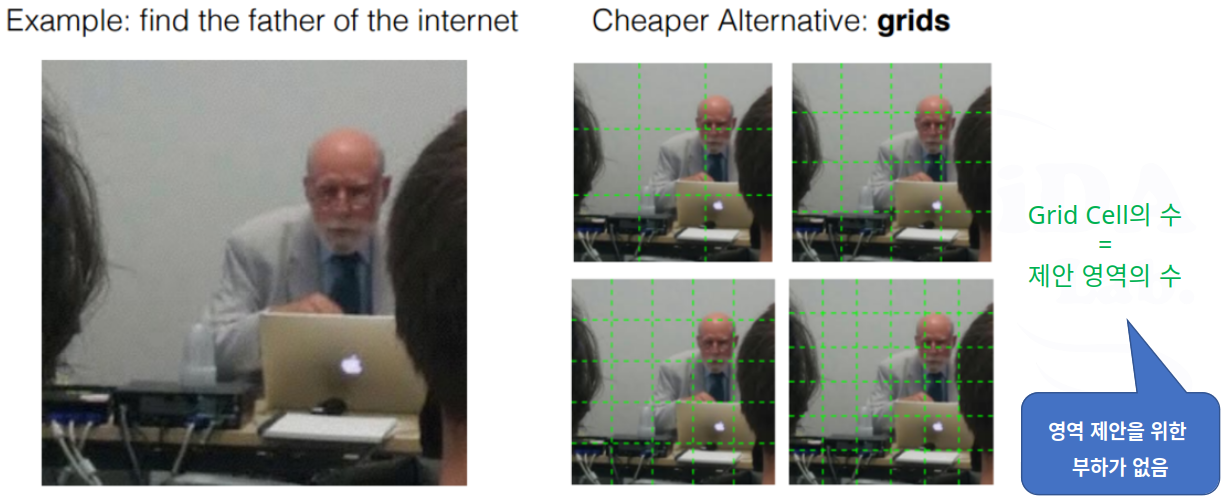
- YOLO에서는 Grid 방식을 더욱 발전시켜서 사용함
- Grid 방식 선택 이유: 후보 영역 제안 개수가 적으므로 실시간성 확보가 용이함
- Proposal 방식, Grid 방식에서의 의문점
- 찾고자 하는 물체(객체, Object)가 있을 것 같은 후보영역을 제안한다는데…
- 저렇게 박스를 제안할 때, 무슨 방법으로 박스 내부에 물체가 있을 것이라고 판단, 선택하는가?
- 박스 내부에 물체가 있다고 어떻게 보장하는가?
➜ 보장하지 않음 - 그냥 적당히 여러가지 정보, 기준을 잡고… 그냥 제안함(영상의 Edge 정보, 임의의 박스 등등)
- YOLO 모델에서는
- 말 그대로 영상을 1번만 읽음
- 최종 출력단에서 경계박스 검색과 클래스 분류를 동시에 수행 ➜ 속도가 빠르다
- 즉, 하나의 네트워크가 ➜ 동시에 ➜ 특징 추출, 경계박스 만들기, 클래스 분류를 한꺼번에 수행
(그래서 구조가 간단하고 빠름) - 그런데 어떻게?
2. YOLO 모델의 구조
- YOLO 모델의 처리 방식
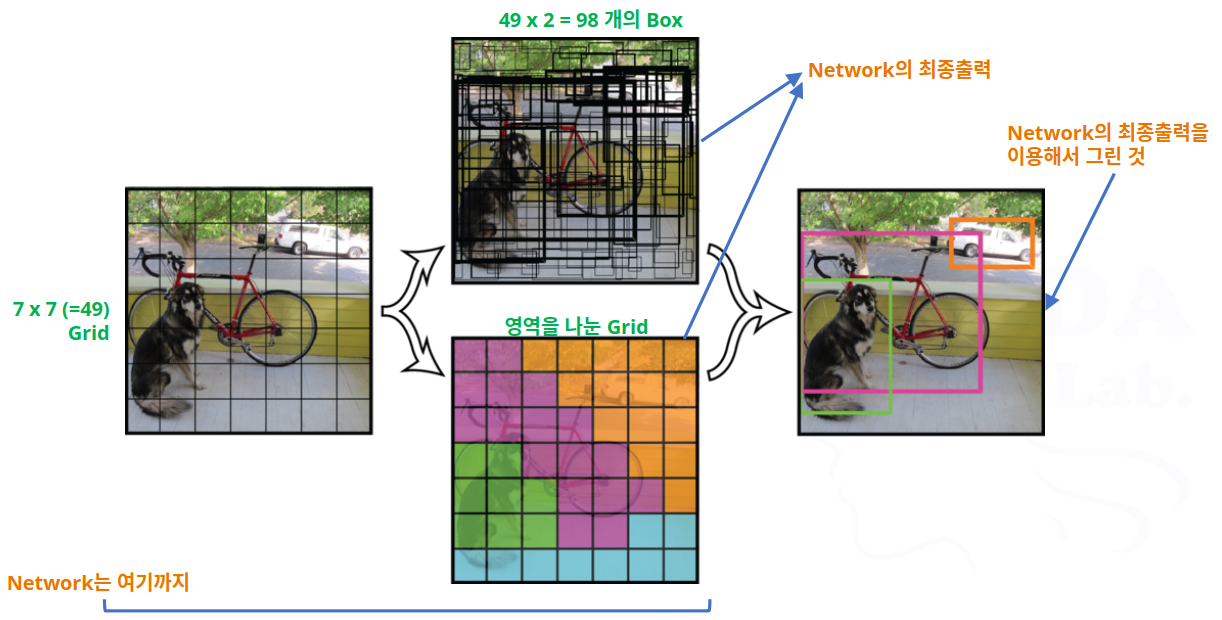
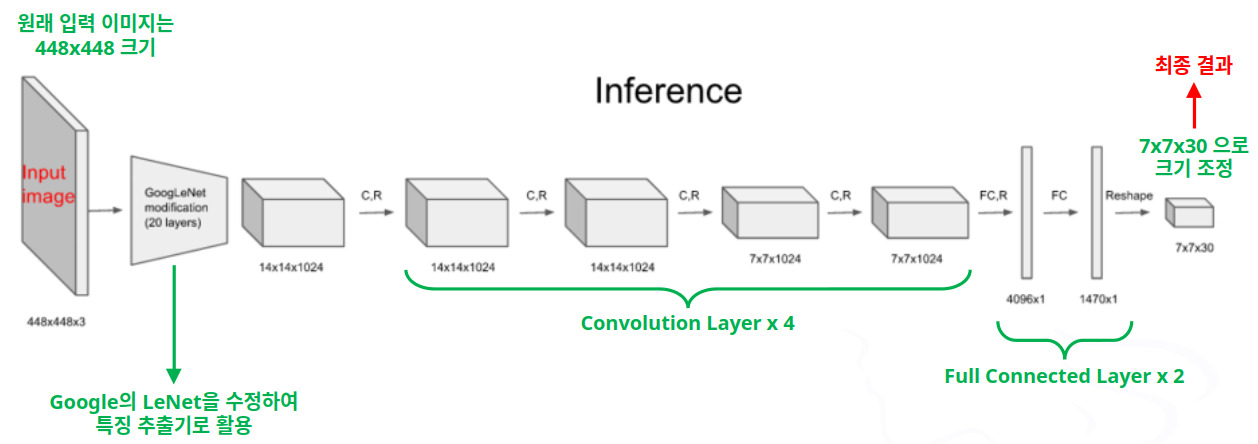
- YOLO 모델의 네트워크 구조
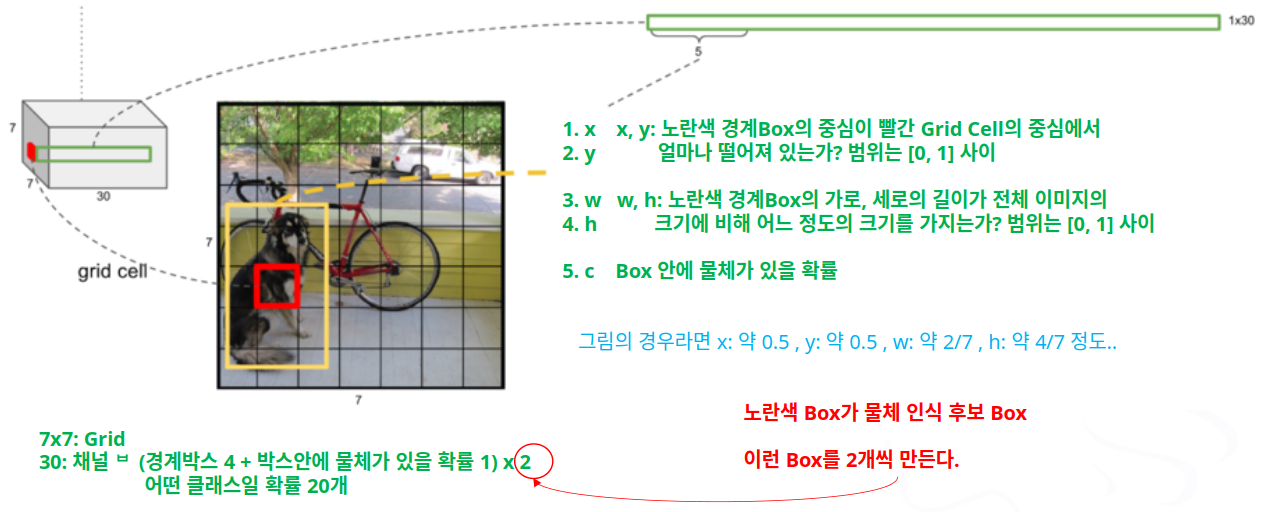
- YOLO 모델의 최종 결과에는 무엇이 들어 있을까?
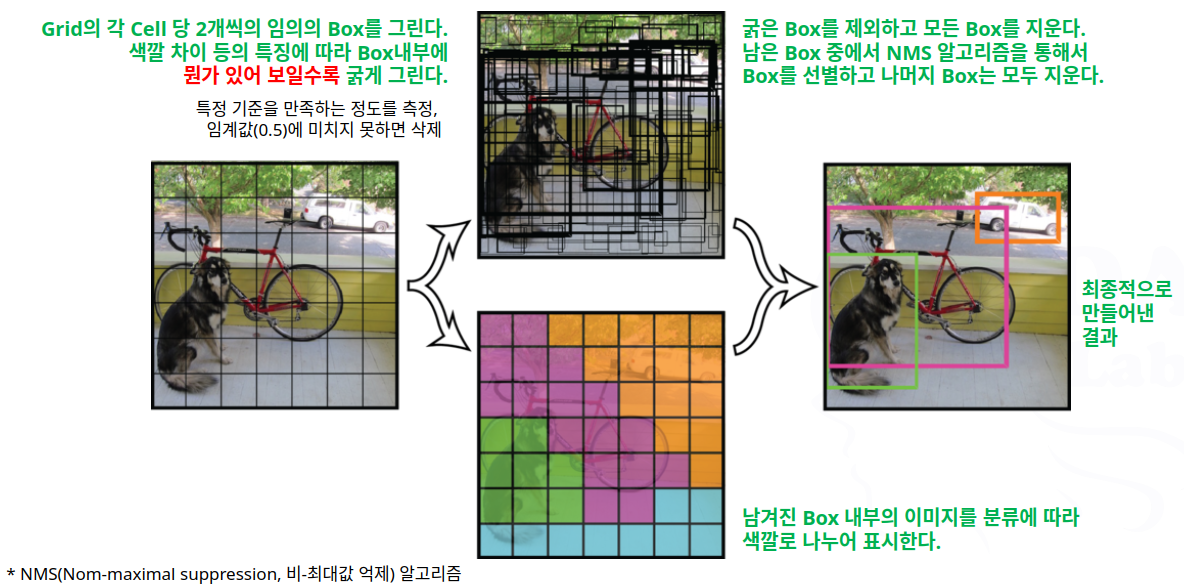
- 1단계
- 2단계
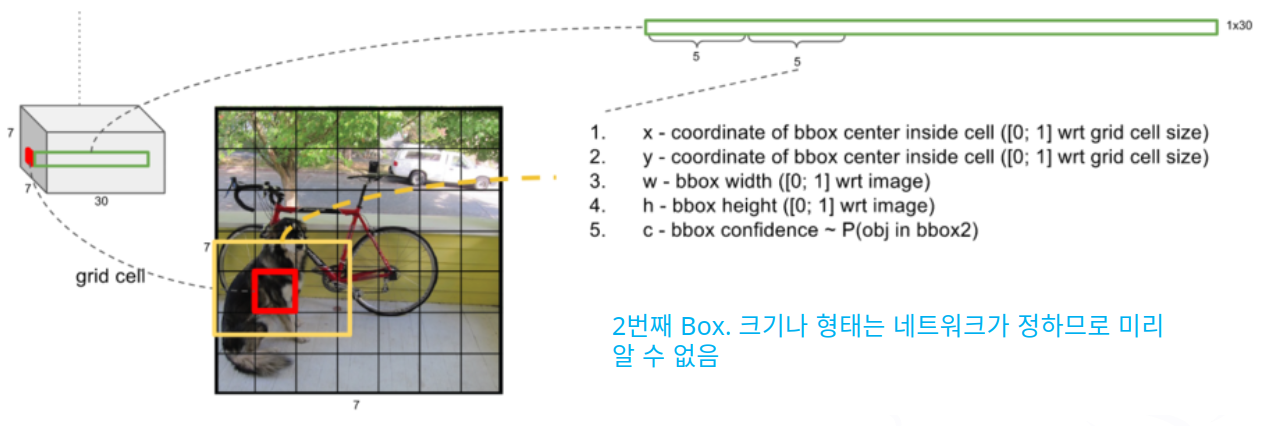
- 3단계
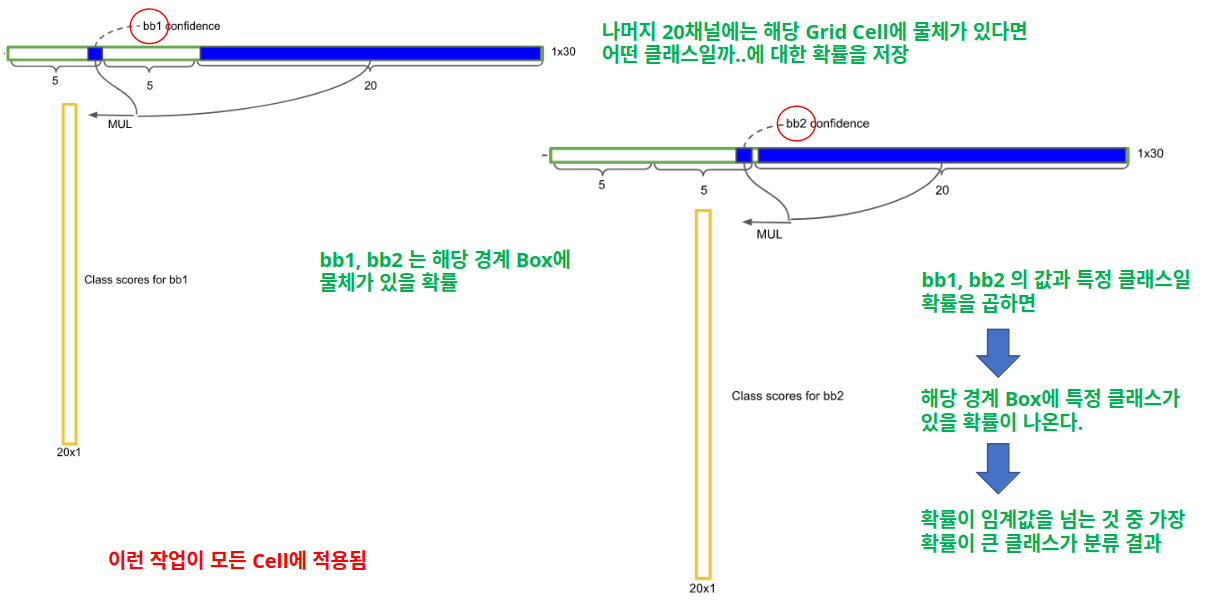
- 4단계
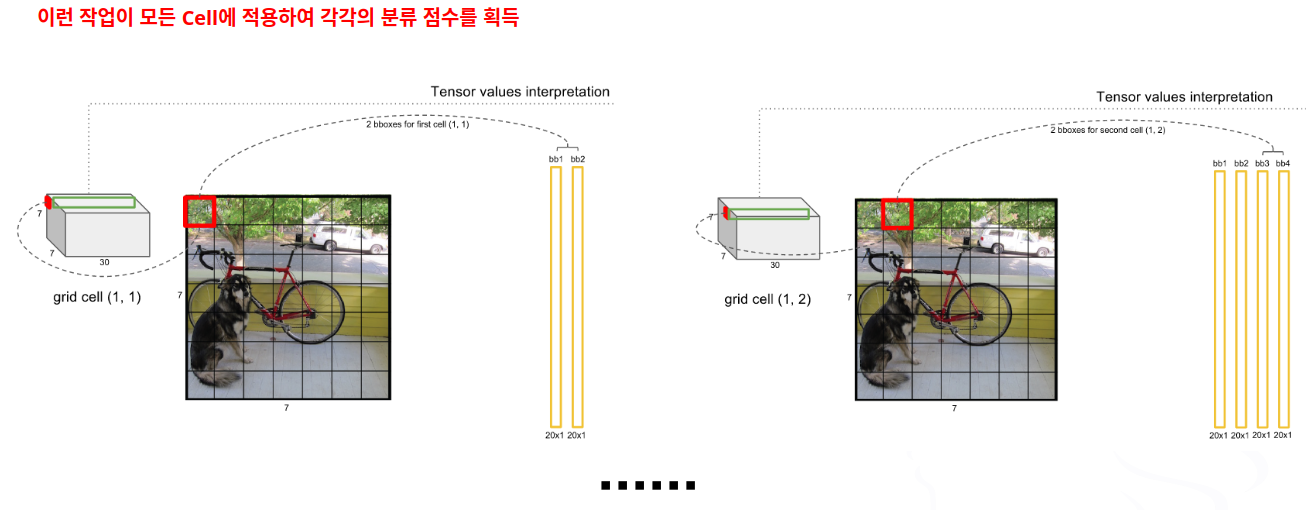
- 5단계
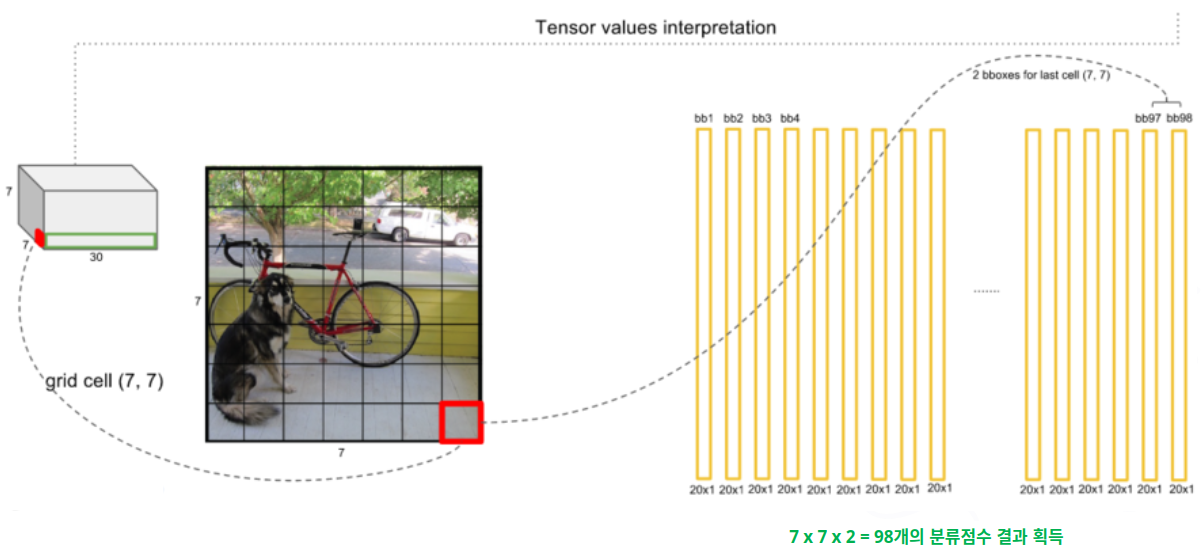
- 6단계
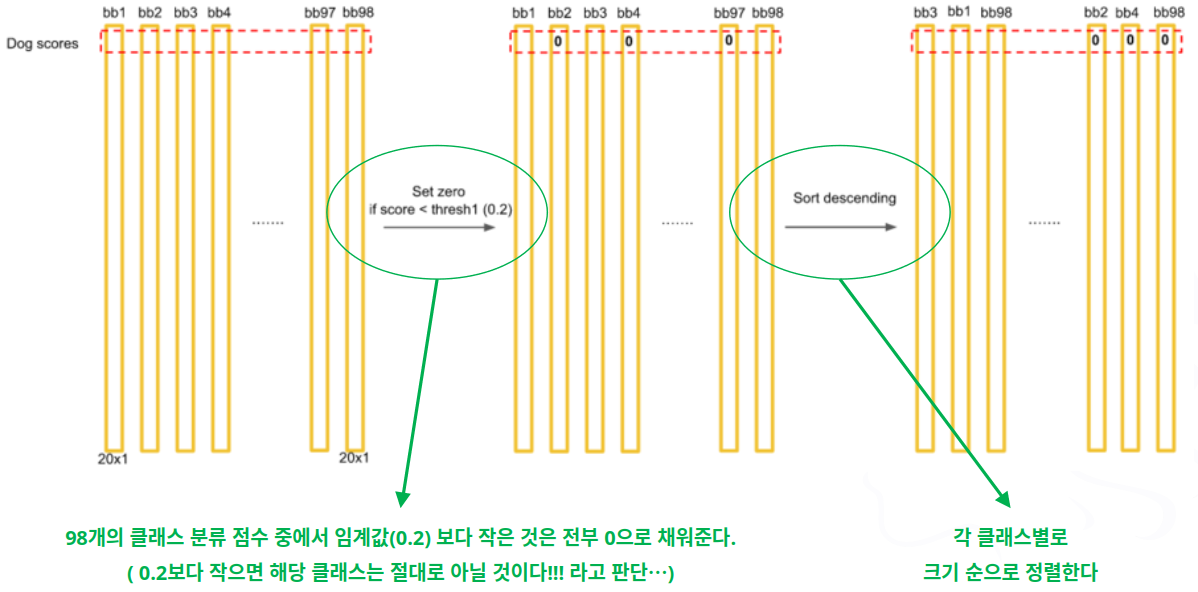
- 7단계
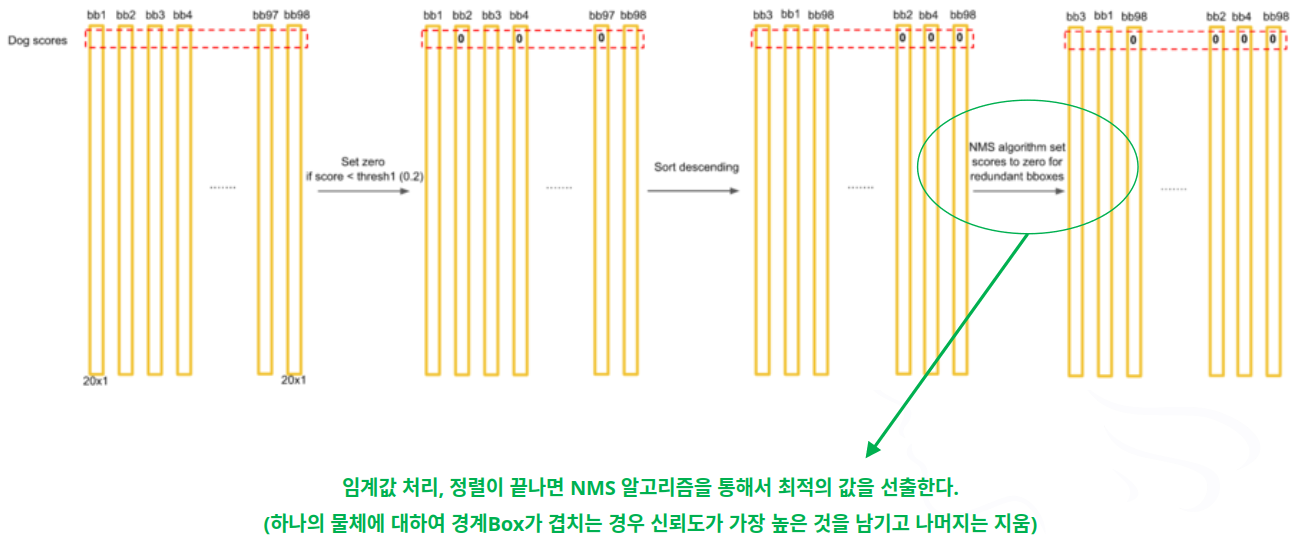
- 8단계
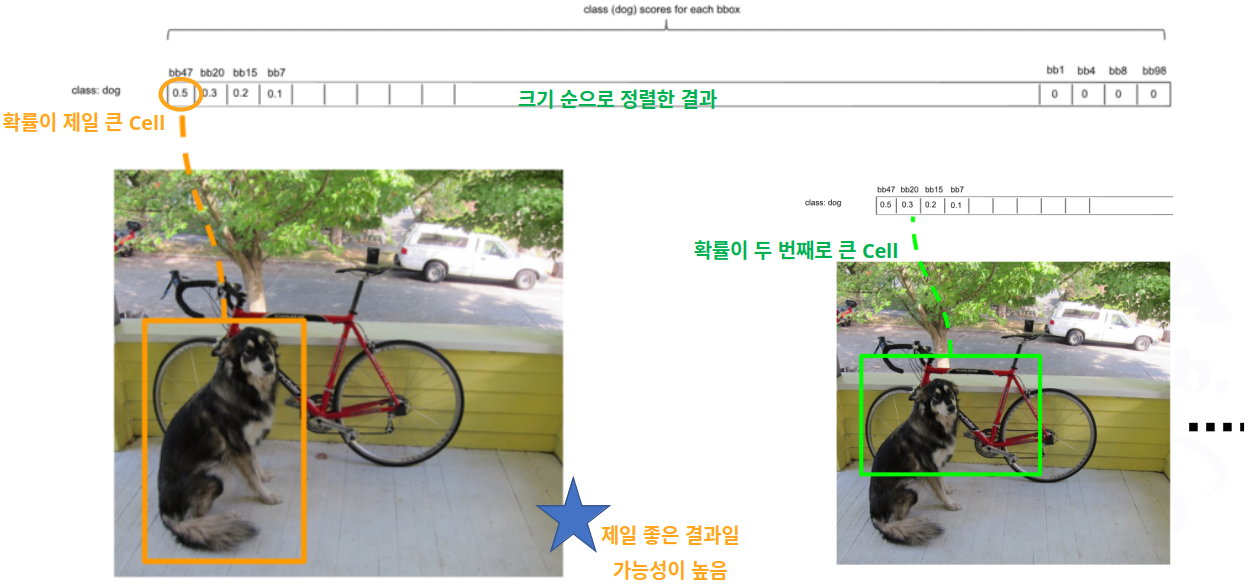
- 제일 가능성 높은 것만 남기고 지우는데…
- 개가 2마리 있으면?
- 위치가 겹치지 않고 동일한 클래스로 분류되면 큰 문제는 없음
- 그러나 비슷한 위치에서 동일한 클래스들이 모여 있다면? .. 개떼 ….
- 2마리까지만 인식함 (경계Box가 2개씩이므로)
- 단점!! ➜ 점차 개선되어 가고 있음

- 개가 2마리 있으면?
3. YOLO 모델의 아키텍처 분석(v5 기준)
3.1 기본 구성
- Backbone과 Head로 구성됨
- YOLO v5 아키텍처의 정보: ~/yolov5/models/yolov5s.yaml 파일을 통해서 확인할 수 있음
- Backbone
- 이미지로부터 Feature map을 추출하는 부분
- CSP-Darknet 사용
- YOLO v4의 Backbone과 유사
- YOLO v3의 Backbone은 Darknet53 ➜ CSP 미적용
- YOLO v5-(s / m / l / x) 까지 총 4가지 버전의 Backbone이 존재함
- 본 과정에서는 제일 작은 모델인 YOLO v5-s를 기준으로 함
- Head
- 추출된 Feature map을 바탕으로 물체의 위치를 찾는 부분
- Anchor Box(Default Box)를 처음에 설정하고 이를 이용하여 최종적인 Bounding Box를 생성함
- YOLO v3와 동일하게 3가지의 scale에서 바운딩 박스를 생성함
- 8픽셀 정보를 가진 작은 물체, 16픽셀 정보를 가진 중간 물체, 32픽셀 정보를 가진 큰 물체를 인식 가능
- 각 스케일에서 3개의 앵커 박스를 사용 ➜ 총 9개의 앵커 박스가 있음
3.2 YOLO v5-s 아키텍처 분석
3.2.1 아키텍처 정보 파일
- ~/yolov5/models/ 경로의 yolo.py, common.py 의 코드가 중심
- yolo.py
- YOLO 아키텍처에 관한 코드
- 이 코드를 통해 YOLO 아키텍처가 생성됨
- common.py
- YOLO 아키텍처를 구성하는 모듈(레이어)에 관한 코드
- 이 코드에 conv, BottleneckCSP 등등 YOLO 모듈들이 구현되어 있음
3.2.2 YOLO v5의 아키텍처 구조
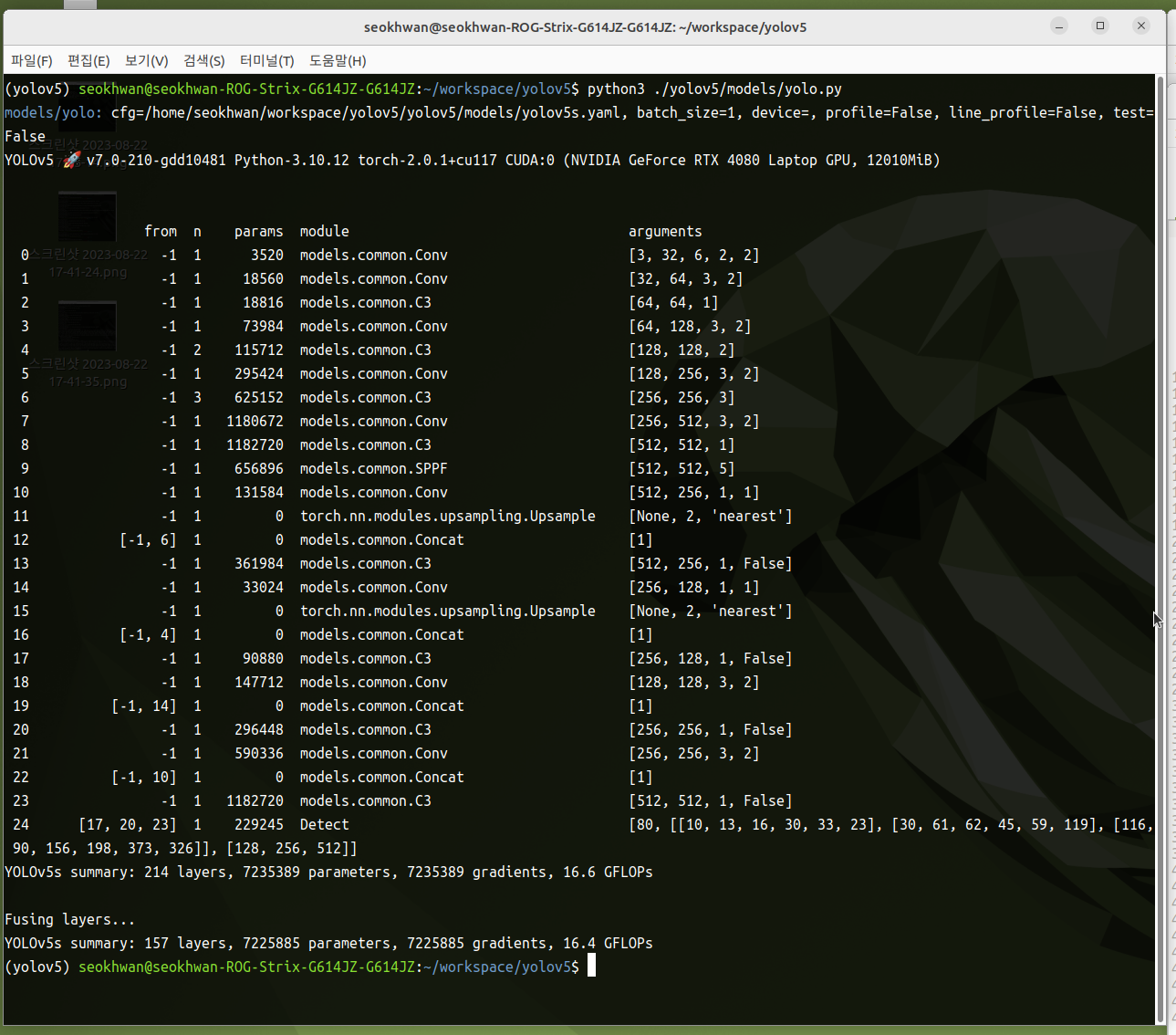
- yolo.py를 실행시키면 아키텍처의 구조를 볼 수 있음
- python ./yolov5/models/yolo.py
3.2.3 YOLO v5의 모듈
분석 초점: common.py 파일을 기반으로 하여 각 모듈 클래스의 forward 함수를 중심으로 분석함
- Focus
- 입력 데이터 x를 출력 데이터 y의 형태로 변환시킴
- x(b, c, w, h) ➜ y(b, 4c, w/2, h/2)
- b: batch_size, c: channel, w: width, h: height
- Conv
- 일반적인 Conv + Batch_Norm 레이어
- Conv 연산을 수행한 후 Batch Normalization 과정을 거침
- 활성화 함수로는 Hard Swish 함수를 사용
- Bottleneck
- ResNet에서도 사용된 Shortcut Connection이 적용된 블록
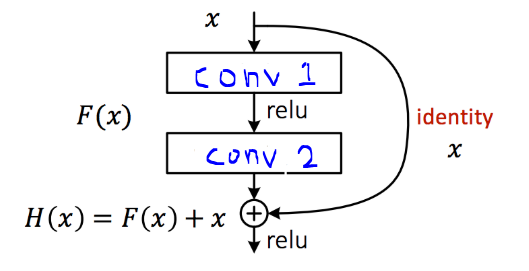
- BottleneckCSP
YOLO v5의 핵심
- 4개의 Conv 레이어가 생성됨
- conv1, conv4: conv + batch_norm 레이어
- conv2, conv3: conv 레이어 (batch_norm 미적용)
- CSP 구조에 따라 2개의 y 값을 생성함
- y1: Short-Connection으로 연결된 conv1 ➜ conv3 연산 값
- y2 : 단순히 conv2를 연산한 값
- 마지막으로 y1과 y2 값을 합치고, conv4 레이어를 통과하여 연산 수행
- SPP
- YOLO v3-SPP에서 사용했던 Spatial Pyramid Pooling Layer
- Spatial bins로 5x5, 9x9, 13x13 크기의 Feature Map을 사용
➜ 최종적으로 5 + 9 + 13 = 27의 크기로 고정된 1차원 형태의 배열을 생성
➜ Fully Connected Layer에 입력으로 들어가도록 함
- Concat
- 2개의 conv 레이어 연산 값을 결합
- touch.nn.modules.upsampling.Upsample
- 단순히 업샘플링하는 토치의 기본 라이브러리 함수
- 구조 값을 따르면 Feature Map 의 각 배열의 갯수를 2배로 올려줌
3.2.4 YOLO v5의 Backbone
- s(small), m(medium), l(large), x(extra?)의 4가지가 있음
- s가 가장 작고 빠르며, x가 가장 크고 느림
- yaml 파일에 있는 “depth_multiple” (model depth multiple)과 “width_multiple” (layer channel multiple)의 두 가지 변수로 결정됨
- YOLO v5-s의 depth&width_multiple이 가장 작고(depth_multiple : 0.33, width_multiple : 0.50)
- YOLO v5-x의 depth&width_multiple이 가장 큼 (1.33, 1.25)
- Depth_Multiple
- 모델의 구조는 depth_multi 값에 따라 변화함
- depth_multiple 값이 클수록 BottleneckCSP 모듈(레이어)이 더 많이 반복되어, 더 깊은 모델이 됨
- yaml 파일에서 읽어온 depth_multiple 값 ➜ gd 변수에 저장, number 값 ➜ n 변수
- n(depth gain) = max(round(ngd), 1) if n > 1 else n
➜ 만약 n이 1보다 크면 ngd의 값을 반올림(소수점 둘째 자리)한 후, 1과 비교하여 큰 값을 선택. 그렇지 않으면 그냥 n을 사용 - Focus, Conv, SPP 모듈은 number 값이 1 ➜ n * gd = 0.33 ➜ 반올림해서 0.3 ➜ max에 의해서 1
- BottleneckCSP 모듈은 number 값이 3, 9
- n(number) = 3일 때: n * gd = 0.99 ➜ 반올림해서 1 ➜ Focus, Conv, SPP 의 n(depth gain) = 1
- n(number) = 9일때: n * gd = 2.97 ➜ 반올림해서 3 ➜ BottleneckCSP의 n(depth gain) = 3
- 해당 모듈들은 n(depth gain)값 만큼 반복 수행
- n(number) = 3을 가지는 BottleneckCSP ➜ (0): Bottleneck 하나만 반복 ➜ 1번
- n(number) = 9를 가지는 BottleneckCSP ➜ (0): Bottleneck ~ (2): Bottleneck를 반복 ➜ 3번
- 따라서 depth_multiple 값이 큰 YOLO v5-x는 s에 비해 당연히 더 많은 layers를 가지게 되어, 더 깊은 모델이 됨
- Width_Multiple
yaml 파일의 첫번째 args 값과 width_multiple 값을 곱한 값이 해당 모듈의 채널 값으로 사용됨
➜ Width_Multiple 값이 증가할 수록 해당 레이어의 conv 필터 수가 증가함- YOLO v5-s의 width_multiple 값은 0.5 ➜ 변수 gw에 저장
- yaml 파일의 args의 첫번째 값 ➜ c2
해당 모듈의 채널 수 = c2 * gw
- 따라서 YOLO v5-x는 s에 비해 큰 width_multiple 값을 지니므로, 각 모듈의 채널 수가 가장 많음
3.2.5 YOLO v5의 Head
- yaml 파일에 따르면
- Head는 [from, number, module, args] 으로 구성
- {Conv, Upsample, Concat, BottleneckCSP}이 한 블록으로 구성 ➜ 이러한 블록들이 총 4개
- 마지막의 Detect 부분에서 모두 연결됨
- Head에서는
- BottleneckCSP 만이 number 값이 3으로, depth_multiple 값에 따라 더 많이 반복 가능
➜ 즉 YOLO v5-x가 s에 비해 Head 층도 더 깊음
- BottleneckCSP 만이 number 값이 3으로, depth_multiple 값에 따라 더 많이 반복 가능
Head에서 주의 깊게 봐야할 모듈은 Concat과 Detect
- Concat 모듈
- Concat의 의미: Concat의 바로 직전 층인 nn.Upsampel 층과 i=6인 BottleneckCSP 층의 결합을 의미
- yaml 파일에서 Concat 모듈을 보면

- 해당 블록을 가져오면

- [[-1, 6], 1, Concat, [1]]의 구성
- Concat의 정리
- 첫 번째 블록의 Concat 부분 : 백본의 P4와 결합 (yolo.py 기준 i=6인 BottleneckCSP)
- 두 번째 블록의 Concat 부분 : 백본의 P3와 결합 ➜ 작은 물체 검출 (yolo.py 기준 i=4인 BottleneckCSP)
- 세 번째 블록의 concat 부분 : 헤드의 P4와 결합 ➜ 중간 물체 검출 (yolo.py 기준 i=14인 Conv)
- 네 번째 블록의 concat 부분 : 헤드의 P5와 결합 ➜ 큰 물체 검출 (yolo.py 기준 i=10인 Conv)
- Detect 모듈
- i=17, 20, 23인 레이어를 종합하여 Detect

3.2.6 앵커 박스 분석
- 앵커 박스(Anchor Box)
- 객체 탐지 모델이 이미지 내에서 객체의 위치를 예측할 때 사용하는 ‘사전 정의된(predefined) 기준 박스’
- 객체 탐지의 핵심적인 개념 중 하나
- 특정 종횡비(aspect ratio)와 크기(scale)를 가지고 있으며, 다양한 객체들을 효과적으로 탐지하기 위한 일종의 ‘템플릿’ 역할을 수행
- 앵커 박스의 사용 이유
- 객체 탐지 모델은 이미지 내의 여러 객체를 찾아내야 하지만 하나의 그리드 셀에서 여러 객체를 탐지하거나, 같은 그리드 셀에 있더라도 객체들의 크기와 모양이 너무 다르면 예측하기가 어려움
- 앵커 박스는 이런 문제들을 해결하기 위해 도입
- 다양한 종횡비와 크기의 객체 탐지
- 세상에는 자동차, 사람, 신호등처럼 다양한 크기와 모양의 객체들이 존재
- 앵커 박스는 미리 다양한 종횡비(예: 높이가 긴 박스, 너비가 긴 박스, 정사각형 박스)와 크기를 가진 박스들을 정의해 둠으로써, 모델이 어떤 형태의 객체라도 효과적으로 ‘걸러낼’ 수 있도록 지원
- 한 셀에서 여러 객체 탐지
- YOLO는 이미지를 그리드 셀로 나누어 각 셀에서 객체를 탐지
- 앵커 박스를 사용하면 각 그리드 셀이 여러 개의 앵커 박스를 기준으로 예측을 수행하므로
- 하나의 셀 안에서도 여러 개의 객체를 탐지할 가능성이 높아짐
- 다양한 종횡비와 크기의 객체 탐지
- 앵커 박스의 작동 방식
- 그리드 셀 당 여러 앵커 박스 할당
- 입력 이미지는 일정한 크기의 그리드 셀로 나뉘고,
- 각 그리드 셀에는 미리 정의된 여러 개의 앵커 박스(예: 3~9개)가 할당됨
- 오프셋 예측
- 모델은 직접적인 바운딩 박스(Bounding Box)의 좌표(x, y, 너비, 높이)를 예측하는 대신, 이 할당된 앵커 박스를 기준으로 얼마나 떨어져 있는지(오프셋)와 얼마나 커지거나 작아져야 하는지(스케일)를 예측함
- 예: 앵커 박스의 중심에서 X, Y축으로 얼마나 이동해야 하는지, 그리고 앵커 박스의 너비와 높이에서 얼마나 변화해야 하는지를 예측하는 방식
- \(cx = i + 0.5 / 40, cy = j + 0.5 / 40\) 같은 공식으로 상대적 위치를 계산하고,
- \(w = √area × aspectratio / width of input image\) 등으로 너비와 높이를 계산하는 방식
- 모델은 직접적인 바운딩 박스(Bounding Box)의 좌표(x, y, 너비, 높이)를 예측하는 대신, 이 할당된 앵커 박스를 기준으로 얼마나 떨어져 있는지(오프셋)와 얼마나 커지거나 작아져야 하는지(스케일)를 예측함
- 객체 존재 확률 및 클래스 확률 예측
- 각 앵커 박스에 대해 해당 박스에 객체가 있는지 여부(객체성 스코어)와
- 객체가 있다면 어떤 종류의 객체인지(클래스 확률)도 함께 예측
- 최적의 앵커 박스 결정 (K-means Clustering)
- 이 앵커 박스들의 크기와 종횡비는 훈련 데이터셋에 있는 객체들의 통계적 분포(너비와 높이)를 분석하여 미리 결정됨
- 보통 K-means 클러스터링 알고리즘을 사용하여 데이터셋에 가장 잘 맞는 앵커 박스들을 탐색함
- 그리드 셀 당 여러 앵커 박스 할당
- 앵커 박스 값 계산하기
- YOLO v5에서 default로 사용하는 앵커 박스는 코코 데이터 기반의 값
➜ 커스텀 데이터에서는 앵커 박스 값이 적절하지 않을 수 있음
➜ 커스텀 데이터셋에 알맞는 앵커 박스 값을 계산을 해야 할 필요가 있음 - 앵커 박스의 값 계산은 ~/yolov5/utils/general.py의 kmean_anchors() 함수에 구현
- kmean_anchors() ➜ 앵커 박스 계산의 핵심
- path : data yaml 파일 경로
- n : 생성할 앵커박스 갯수 (우리는 9개의 앵커박스를 생성)
- img_size : 이미지 크기
- thr : 매개변수로 제어되는 Threshold(임계값)
- gen : 유전자 알고리즘의 진화적 반복 횟수(돌연변이+선택)
- verbose : 진행 내용을 어느 정도 출력할 것인지 결정하는 변수
- return k ➜ 유전자 알고리즘 진화 후 K-평균 + 앵커 ➜ model.yaml 파일의 anchor 부분에 들어감
- YOLO v5에서 default로 사용하는 앵커 박스는 코코 데이터 기반의 값
3.2.7 최적화 분석
- LOSS 함수분석
- GIoU (giou_loss)
- bounding box에 관한 loss 함수. 1 - giou 값 = giou loss
- giou loss는 utils/general.py의 compute_loss 함수에 구현
- obj (objectness loss) 및 cls (classification loss)
- BCEwithLogitsLoss 사용 (general.py에서 확인)
- BCEwithLogitsLoss는 class가 2개인 경우에 사용하는 loss function
- BCE(Binary Cross Entropy)에 sigmoid layer를 추가한 것
- classification Loss
- 객체가 탐지되었을 때, 탐지된 객체의 Class가 맞는지에 대한 Loss
- MSE와 유사하게 \((판단값 - 실제값)^2\) 으로 계산
- Objectness Loss
- Class의 구분없이 객체 탐지 자체에 대한 Loss
- 객체가 있을 경우의 Loss, 없을 경우의 Loos를 따로 계산한 후, 각 Loss에 가중치 값을 곱하여 클래스 불균형 문제를 해결
- BCEwithLogitsLoss 사용 (general.py에서 확인)
- GIoU (giou_loss)
- Optimizer 분석
- optimizer의 default 값은 SGD
- 추가 설정으로 Adam으로 변경 가능
- mAP 분석
- mAP_0.5
- mAP의 평균을 IoU Threshold = 0.5로 구한 값
- mAP_0.5:0.95
- mAP의 평균을 다음의 IoU Threshold 값으로 구한 것
- 즉 0.5~0.95 사이의 IOU threshold 값을 0.05 씩 값을 변경해서 측정한 mAP의 평균값
- IoU의 threshold 값이 mAP_0.5보다 높기 때문에, 수치는 mAP_0.5보다 낮게 나옴
- mAP_0.5
4. YOLO26 소개
4.1 YOLO26 개요
- 아직 개발 중인 버전
- 이전 버전인 v11에서 v12, v26으로 서로 다른 목적을 가지고 각각 개발이 진행 중임
- YOLO26은 실시간 객체 감지기로, 특히 엣지(Edge) 및 저전력 장치에 최적화되도록 설계되었음
- 불필요한 복잡성을 제거하고 대상 혁신을 통합하여 더 빠르고 가벼움
- 접근성이 뛰어난 배포를 제공하는 간소화된 디자인을 도입
4.2 아키텍처 설계의 세 가지 핵심 원칙
- 단순성
- YOLO26은 네이티브 엔드투엔드 모델로, 비최대 억제NMS 없이도 직접 예측을 생성함
- 이러한 후처리 단계를 제거함으로써 추론이 더 빠르고 가벼워지며 실제 시스템에 더 쉽게 배포할 수 있음
- 이러한 접근 방식은 YOLOv10 에서 처음 시도되었으며, YOLO26에서 더욱 발전되었음
- 배포 효율성
- 엔드 투 엔드 설계 방식 적용으로 파이프라인의 전체 단계를 줄임
- 통합을 획기적으로 단순화하고
- 대기 시간을 줄이며
- 다양한 환경에서 배포를 더욱 강력하게 만듦
- 엔드 투 엔드 설계 방식 적용으로 파이프라인의 전체 단계를 줄임
- 교육 혁신
- YOLO26, MuSGD 옵티마이저 출시
- SGD 와 문샷 AI의 Kimi K2에서 영감을 받아 탄생한 MLM 트레이닝 기술
- MLM 트레이닝 기술
- 자연어 처리(NLP)에서 ‘Masked Language Modeling’을 의미
- 모델이 입력 텍스트 중 일부 토큰(단어)을 가려두고 나머지 토큰을 예측하게 하여 언어 이해와 어휘력을 강화하는 훈련 방식
- GPT, BERT 등 주요 LLM의 핵심 훈련 방식으로, 문법·어휘·문장 구조 등 언어 전반을 폭넓게 학습할 수 있음
- MLM 트레이닝 기술
- 향상된 안정성과 빠른 융합을 제공
- 언어 모델에서 컴퓨터 비전으로 최적화 기술을 이전함
- SGD 와 문샷 AI의 Kimi K2에서 영감을 받아 탄생한 MLM 트레이닝 기술
- YOLO26, MuSGD 옵티마이저 출시
- 아키텍처 혁신에 따른 효과
- 소형 객체에서 더 높은 정확도를 달성하고
- 원활한 배포를 제공하며
- CPU에서 최대 43% 더 빠르게 실행되는 모델 제품군을 제공하여
- YOLO26을 리소스가 제한된 환경에서 가장 실용적이고 배포 가능한 YOLO 모델 중 하나로 만듦
4.3 주요 기능
- DFL 제거
- 기존에 사용된 분포 초점 손실(DFL) 모듈은 효과적이기는 하지만 내보내기가 복잡하고 하드웨어 호환성이 제한되는 경우가 많음
- 분포 초점 손실 (DFL, Distribution Focal Loss)
- 기존의 객체 탐지 모델들은 바운딩 박스를 예측할 때, 객체의 중심점과 너비, 높이 등 4개의 좌표 값을 직접 회귀(Regression) 방식으로 예측함
- DFL은 이러한 방식에서 벗어나, 바운딩 박스의 각 측면까지의 상대적인 오프셋(offset)을 ‘분포’ 형태로 학습하도록 설계된 손실 함수
- 특정 위치가 정답이 ‘이것이다’라고 하나의 값으로 예측하는 대신, ‘이 범위 안에 존재할 확률이 높다’는 분포를 학습함으로써 더 정교한 바운딩 박스 예측이 가능하게 하는 방식
- 분포 초점 손실 (DFL, Distribution Focal Loss)
- YOLO26은 DFL을 완전히 제거하여 추론을 간소화하고 에지 및 저전력 디바이스에 대한 지원을 확대함
- 기존에 사용된 분포 초점 손실(DFL) 모듈은 효과적이기는 하지만 내보내기가 복잡하고 하드웨어 호환성이 제한되는 경우가 많음
- 엔드투엔드 NMS 추론
- 별도의 후처리 단계로 NMS 의존하는 기존 디텍터와 달리, YOLO26은 기본적으로 엔드투엔드 방식을 적용
- 예측이 직접 생성되므로 지연 시간이 줄어들고 프로덕션 시스템에 더 빠르고, 가볍고, 안정적으로 통합할 수 있음
- ProgLoss + STAL
- 향상된 손실 기능으로 감지 정확도가 향상
- 작은 객체 인식 정확도와 학습 안정성을 크게 향상시키는 중요한 요소
- IoT, 로봇 공학, 항공 이미지 및 기타 에지 애플리케이션의 핵심 요구 사항인 작은 물체 인식이 눈에 띄게 개선됨
- ProgLoss (Progressive Loss Balancing)
- 딥러닝 모델, 특히 객체 탐지 모델은 여러 종류의 예측(바운딩 박스 회귀, 객체 분류, 객체 존재 여부 등)에 대한 손실 함수를 결합하여 사용함
- ProgLoss는 이러한 다양한 손실 항(loss term)들 간의 균형 잡힌 가중치를 보장함
- 초기 학습 단계에서는 특정 손실에 더 집중하고, 학습이 진행됨에 따라 다른 손실의 중요도를 점진적으로 높여가는 방식
- 학습이 특정 손실에 과도하게 편향되는 것을 방지함
- 이를 통해 학습 안정성을 높이고, 전반적인 성능 개선에 기여
- STAL (Stable Task Assignment Learning)
- 객체 탐지 모델에서 “어떤 예측 박스가 어떤 실제 객체(Ground Truth)를 담당할 것인가”를 결정하는 과정을 ‘할당(Assignment)’이라고 하며, 이 할당 전략은 모델의 학습에 매우 큰 영향을 미침
- STAL은 이 할당 과정을 더욱 안정적이고 효율적으로 만드는 ‘할당 모듈(assignment module)’
- 예측기와 실제 객체 간의 매칭을 더욱 정확하고 견고하게 함으로써, 특히 모호하거나 복잡한 상황에서 모델이 객체를 올바르게 학습하도록 지원
- 이는 모델이 다양한 크기의 객체, 특히 작은 객체들을 더 잘 인식하고 분류할 수 있도록 중요한 기반을 제공함
- ProgLoss + STAL의 시너지 효과
- 학습 안정성 강화
- ProgLoss의 손실 균형 조절과 STAL의 안정적인 할당을 통해 모델 학습이 더욱 견고해지고 수렴이 빨라짐
- 작은 객체 인식 능력 향상
- 손실 항들의 공평한 가중치와 정확한 할당 전략은, 상대적으로 예측하기 어려운 작은 객체들의 특징을 모델이 놓치지 않고 더 잘 학습하도록 만듦
- 정확도 개선
- 최종적으로는 모델의 전반적인 객체 탐지 정확도가 향상됨
- 학습 안정성 강화
- YOLO26이 “엣지 및 저전력 장치에 최적화”되면서도 뛰어난 성능을 보이는 데에는, 단순히 모델을 가볍게 만드는 것을 넘어 이러한 정교한 학습 및 손실 최적화 기법들이 큰 역할을 하고 있음
- MuSGD 옵티마이저
- SGD(Stochastic Gradient Descent)의 견고함과 일반화 능력에 Muon Optimizer를 결합한 새로운 하이브리드 최적화 기법
- 모델이 학습 과정에서 더욱 안정적으로 최적점에 도달할 수 있도록 지원
- LLM 훈련의 고급 최적화 방법을 컴퓨터 비전에 도입하여 보다 안정적인 훈련과 빠른 융합을 가능하게 함
- 최대 43% 빨라진 CPU 추론
- 엣지 컴퓨팅에 최적화된 YOLO26은 훨씬 빠른 CPU 추론을 제공하여 GPU가 없는 디바이스에서도 실시간 성능을 보장함
4.4 지원되는 작업 및 모드
| 모델 | 작업 | 추론 | 검증 | 훈련 | 내보내기 |
|---|---|---|---|---|---|
| YOLO26 | 객체 탐지 | ● | ● | ● | ● |
| YOLO26-seg | 인스턴스 분할 | ● | ● | ● | ● |
| YOLO26-pose | 포즈/키포인트 | ● | ● | ● | ● |
| YOLO26-obb | 방향 감지 | ● | ● | ● | ● |
| YOLO26-cls | 분류 | ● | ● | ● | ● |