LLM(대형 언어 모델) 개요
- 1. 대형 언어 모델(LLM)이란?
- 2. LLM의 핵심 개념 및 특징
- 3. LLM의 학습 과정
- 4. 주요 응용/활용 분야
- 5. LLM의 장점과 한계
- 6. LLM과 기존 AI 모델의 차이점
- 7. LLM 개발의 역사: 주요 이슈와 시간 순서
- 8. LLM의 미래 전망
1. 대형 언어 모델(LLM)이란?
- 대형 언어 모델(Large Language Models, LLM) 또는 거대 언어 모델이라고 지칭함
- 방대한 양의 텍스트 데이터를 학습하여 인간과 유사한 텍스트를 생성하고 이해하는 데 특화된 인공 신경망 모델
- 딥러닝 기술, 특히 트랜스포머 아키텍처의 발전과 함께 등장한 자연어 처리(Natural Language Processing, NLP) 분야의 핵심 기술
- 자연어 처리 분야에서 혁신적인 성과를 보여주며 다양한 애플리케이션에 활용되고 있음
2. LLM의 핵심 개념 및 특징
방대한 데이터 학습
- 인터넷 텍스트, 서적, 뉴스 기사, 코드 등 다양한 소스에서 수집된 수백억 개에서 수조 개에 이르는 토큰으로 구성된 방대한 데이터셋을 학습함
- Common Crawl, Wikipedia와 같은 데이터 세트가 주로 사용됨
- 이 과정을 통해 언어의 통계적 패턴, 문법 구조, 의미론적 관계, 심지어 세계 지식까지 내재화 함
- 인터넷 텍스트, 서적, 뉴스 기사, 코드 등 다양한 소스에서 수집된 수백억 개에서 수조 개에 이르는 토큰으로 구성된 방대한 데이터셋을 학습함
트랜스포머 아키텍처(Transformer Architecture)
대부분의 최신 LLM은 트랜스포머 아키텍처를 기반으로 함
- 트랜스포머는
- 순환 신경망(RNN)의 장기 의존성 문제(Long-Term Dependency Problem)를 해결하고
- 병렬 처리를 가능하게 하여(순차 처리가 아닌 병렬 처리를 통해 학습 속도를 크게 향상시킴)
- 더 긴 문맥을 효과적으로 학습하고 처리할 수 있도록 설계됨
- 트랜스포머 아키텍처의 핵심 구성 요소
- 어텐션 메커니즘(Attention Mechanism)
- 입력 시퀀스 내의 각 단어가 다른 단어와 얼마나 관련이 있는지에 따라 가중치를 부여하여 문맥을 파악하는 데 중요한 역할을 함
- 특히 셀프 어텐션(Self-Attention)은 문장 내의 단어들 간의 관계를 모델링하는 데 효과적임
- 인코더-디코더 구조 (일부 모델)
- 초기 트랜스포머 모델
- 입력 시퀀스를 인코딩하여 의미를 추출하고,
- 디코더를 통해 추출된 의미를 기반으로 새로운 시퀀스를 생성하는
- 인코더-디코더 구조를 가짐
- 트랜스포머 모델의 Full Architecture를 따름
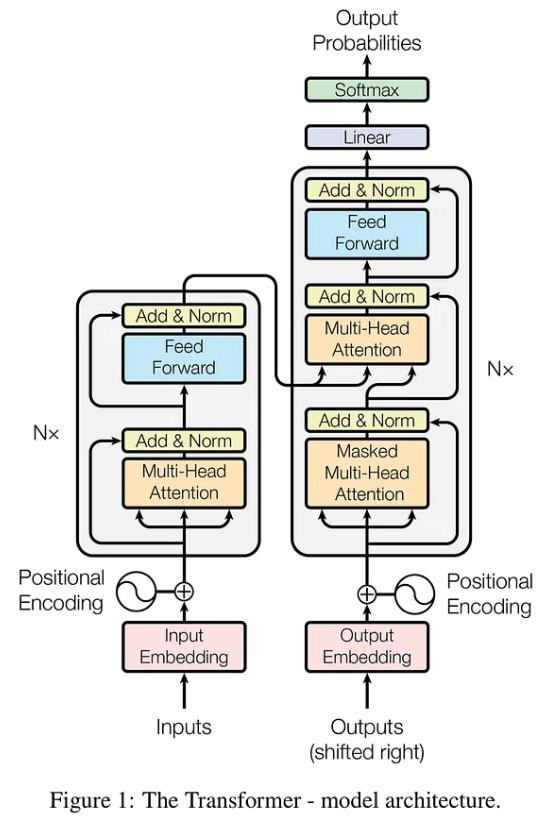
- 초기 트랜스포머 모델
- 트랜스포머 디코더 (GPT 계열)
- GPT(Generative Pre-trained Transformer) 계열 모델
- 디코더만을 사용하여
- 이전 단어들을 기반으로 다음 단어를 예측하는 생성 모델
- GPT(Generative Pre-trained Transformer) 계열 모델
- 트랜스포머 인코더 (BERT 계열)
- BERT(Bidirectional Encoder Representations from Transformers) 계열 모델
- 인코더만을 사용하여
- 문맥 속에서 단어의 의미를 양방향으로 이해하는 데 특화됨
- BERT(Bidirectional Encoder Representations from Transformers) 계열 모델
- 어텐션 메커니즘(Attention Mechanism)
- 자연어 이해 및 생성
- 문맥 이해
- 어텐션 메커니즘을 통해
- 문맥 속에서 단어의 의미를 파악하고
- 문법, 구문, 의미적 관계를 학습하여 맥락에 맞는 응답을 생성함
- 장문의 텍스트에서도 일관성을 유지하며 응답할 수 있음
- 어텐션 메커니즘을 통해
- 생성 능력
- LLM의 가장 두드러진 특징 중 하나인 새로운 텍스트를 생성하는 능력
- 인간과 매우 유사하고 문법적으로 정확하며 맥락에 맞는 텍스트를 생성할 수 있음
- 질문에 대한 답변, 에세이 작성, 시나리오 창작, 프로그래밍 코드 생성까지 가능함
- 생성 과정
- 프롬프트(Prompt) 입력: 사용자로부터 특정 지시나 질문이 담긴 텍스트(프롬프트) 입력
- 다음 단어 예측: 입력된 프롬프트와 학습된 지식을 바탕으로 다음에 올 가장 가능성 있는 단어 예측
- 반복적 생성: 예측된 단어는 다시 입력으로 사용되어 다음 단어를 예측하는 과정을 반복하며 텍스트를 생성
- 문맥 기반 추론 능력
- 주어진 문맥을 이해하고 논리적인 추론을 통해 답변하거나 텍스트를 생성하는 능력
- 다양한 자연어 처리 Task 수행
- 텍스트 분류, 감성 분석, 질의응답, 텍스트 요약, 기계 번역, 텍스트 완성 등 다양한 NLP Task를 수행
- 문맥 이해
- 전이 학습(Transfer Learning)
- 방대한 일반 텍스트 데이터로 사전 학습된 LLM은 특정 작업(예: 감성 분석, 질의응답, 텍스트 요약)에 필요한 비교적 적은 양의 데이터로 파인튜닝(Fine-tuning)될 수 있음
- 이를 통해 적은 데이터로도 높은 성능을 달성할 수 있음
- 비지도 학습 및 미세 조정 활용
- 초기에는 비지도 학습으로 언어의 일반적인 패턴을 학습
- 이후 특정 작업에 맞게 미세 조정(Fine Tuning)
- 상식 및 세계 지식 이해
- 방대한 데이터를 학습하면서 일정 수준의 상식과 세계 지식을 내재화하여 질문에 답변하거나 텍스트를 생성할 때 활용
- 지속적인 발전
- 모델 크기, 학습 데이터 양, 아키텍처 개선 등을 통해 성능이 지속적으로 향상
3. LLM의 학습 과정
- 데이터 수집 및 전처리
- 다양한 소스에서 데이터를 수집하고 이를 정리 및 표준화
- 토큰화
- 텍스트를 작은 단위(토큰)로 나누어 처리
- 모델 훈련
- 딥러닝 알고리즘을 통해 데이터에서 패턴과 관계를 학습
- 평가 및 최적화
- 모델 성능을 평가하고 수정하여 정확도 향상
- 배포
- 실제 환경에서 사용할 수 있도록 배포
4. 주요 응용/활용 분야
- 챗봇 및 가상 비서
- 고객 응대, 정보 제공, 예약 관리 등 다양한 목적으로 활용되는 지능형 챗봇 및 가상 비서 개발에 사용
- 콘텐츠 생성
- 에세이 작성, 이메일 초안 생성 등 다양한 형식의 텍스트 작성
- 블로그 게시물, 소셜 미디어 콘텐츠, 마케팅 문구, 시나리오, 심지어 뉴스 기사까지 자동으로 생성할 수 있음
- 번역 및 요약, 분석
- 높은 품질의 다국어 번역 서비스를 제공하여 언어 장벽을 허무는 데 기여
- 긴 문서를 빠르게 요약하거나 텍스트 데이터에서 중요한 정보를 추출하고 분석하는 데 활용
- 질의응답 시스템
- 사용자의 질문에 대해 관련 정보를 검색하고 정확한 답변을 제공하는 시스템 구축에 사용
- 교육
- 맞춤형 학습 콘텐츠 생성, 학생 질문 응답, 에세이 평가 등에 활용
- 소프트웨어 개발
- 코드 생성 및 디버깅, 오류 수정 등에 활용
- 코드 자동 완성, 버그 예측, 문서 생성 등에 활용되어 개발 생산성 향상
- 연구
- 논문 초록 작성, 연구 데이터 분석, 새로운 가설 생성 등 연구 활동을 지원하는 데 사용
- 멀티모달 지원
- 최근에는 LLM 뿐만 아니라 멀티 모달 지원을 통하여 이미지, 오디오, 비디오 등의 다양한 형태의 데이터를 이해, 활용 및 생성할 수 있음
- 또한 하드웨어의 제어를 목표로하는 LAM(Large Action Model)까지 확장되고 있음
5. LLM의 장점과 한계
- 장점
- 인간과 유사한 자연스러운 언어 생성
- 다양한 작업에 적응 가능한 범용성
- 한계
- 환각(Hallucination)
- 사실과 다르거나 논리적으로 맞지 않는 정보를 생성하는 경우가 있음
- 이는 학습 데이터의 편향성, 모델의 불확실성 등으로 인해 발생할 수 있음
- 편향성(Bias)
- 학습 데이터에 존재하는 사회적 편견이나 불균형이 모델의 출력에 반영될 수 있음
- 이는 차별적인 발언이나 부적절한 콘텐츠 생성으로 이어질 수 있음
- 훈련 데이터의 품질이 결과에 영향을 미침
- 이해 부족
- 겉으로는 인간과 유사한 텍스트를 생성하지만, 실제 세계에 대한 깊이 있는 이해나 추론 능력이 부족할 수 있음
- 데이터 의존성
- 성능은 학습 데이터의 양과 질에 크게 의존하며
- 특정 도메인이나 언어에 대한 데이터가 부족하면 성능이 저하될 수 있음
- 계산 비용
- 대규모 LLM을 학습하고 실행하는 데 상당한 컴퓨팅 자원과 비용이 소요됨
- 윤리적 문제
- 악의적인 콘텐츠 생성, 허위 정보 유포, 개인 정보 침해 등 윤리적인 문제가 발생할 수 있음
- 통제 및 설명 가능성 부족
- 모델의 의사 결정 과정을 완전히 이해하고 통제하기 어려울 수 있음
- 환각(Hallucination)
6. LLM과 기존 AI 모델의 차이점
6.1 학습 데이터와 범용성
- 기존 AI 모델
- 특정 작업(Task)에 맞게 설계되고 학습된 경우가 많음
- 예: 텍스트 분류나 감정 분석과 같은 단일 목적의 작업을 수행함
- 제한된 데이터셋을 사용
- 새로운 작업을 수행하려면 별도의 재학습이 필요함
- 특정 작업(Task)에 맞게 설계되고 학습된 경우가 많음
- LLM
- 방대한 양의 텍스트 데이터를 학습하여 다양한 언어 기반 작업을 수행할 수 있는 범용성을 갖춤
- 하나의 모델로 번역, 요약, 질문 응답 등 여러 작업을 처리할 수 있음
6.2 트랜스포머 기반 아키텍처
- 기존 AI 모델
- RNN(Recurrent Neural Network) 또는 CNN(Convolutional Neural Network)과 같은 전통적 신경망 구조를 사용하는 경우가 많음
- 이 구조는 긴 문맥의 처리에 한계를 가짐
- LLM
- 트랜스포머(Transformer) 아키텍처를 기반으로 함
- 셀프 어텐션(Self-Attention) 메커니즘을 통해 문맥을 효과적으로 이해
- 이를 통해 더 자연스러운 언어 생성이 가능함
6.3 처리 능력과 응답 방식
- 기존 AI 모델
- 규칙 기반 또는 제한된 데이터 패턴에 따라 동작
- 예/아니오”와 같은 단순한 답변을 제공하는 경우가 많음
- LLM
- 인간과 유사한 자연스러운 응답을 생성
- 구조화되지 않은 질문에도 적절한 대응 가능
- 예: 복잡한 문서 작성이나 창의적인 텍스트 생성 가능
6.4 사전 학습 및 전이 학습
- 기존 AI 모델
- 특정 데이터셋에서 학습된 후 다른 작업에 활용하기 어려운 경우가 많음
- LLM
- 사전 학습(Pre-training)을 통해 방대한 데이터를 학습
- 전이 학습(Transfer Learning)을 통해 특정 도메인에 쉽게 적용 가능
6.5 계산 비용 및 효율성
- 기존 AI 모델
- 상대적으로 적은 연산 자원으로 훈련 및 운영 가능
- LLM
- 수십억~수천억 개의 파라미터를 포함함
- 고성능 GPU와 대규모 분산 컴퓨팅 환경 필요
- 높은 계산 비용이 주요 한계로 지적됨
7. LLM 개발의 역사: 주요 이슈와 시간 순서
대형 언어 모델(LLM)의 발전은 자연어 처리(NLP)와 인공지능(AI) 분야의 주요 혁신을 통해 이루어짐
- 1960~1990년대: 초기 NLP와 신경망의 등장
- 1966년: Eliza
- MIT의 Joseph Weizenbaum이 개발한 최초의 챗봇
- 패턴 매칭과 규칙 기반 시스템 사용
- 심리치료사와 유사한 대화를 시뮬레이션함
- 자연어 처리 연구의 시작으로 알려짐
- 1980~1990년대: 신경망과 RNN
- 신경망 기술이 발전하면서 데이터 학습과 패턴 인식이 가능해짐
- Recurrent Neural Networks(RNN)
- 순차 데이터를 처리할 수 있는 능력 제공
- 더 복잡한 언어 모델 개발의 기초 마련
- 1966년: Eliza
- 1997~2010년: LSTM과 NLP 도구의 발전
- 1997년: Long Short-Term Memory(LSTM)
- 긴 문맥을 처리할 수 있는 능력 제공
- 이후 NLP 작업에 중요한 역할을 함
- 2010년: Stanford CoreNLP
- 감정 분석, 개체명 인식 등 복잡한 NLP 작업을 처리할 수 있는 도구 세트 제공
- 자연어 처리에 대한 연구의 가속화
- 1997년: Long Short-Term Memory(LSTM)
- 2011~2017년: 워드 임베딩과 트랜스포머
- 2013년: Word2Vec
- Google의 Tomas Mikolov 팀이 워드 임베딩 기술을 도입하여 개발
- 단어 간 의미적 관계를 효율적으로 학습할 수 있게 함
- 2017년: 트랜스포머 아키텍처
- Google Brain이 발표한 “Attention is All You Need” 논문에서 트랜스포머 모델을 소개
- LLM 개발의 전환점 마련
- 셀프 어텐션 메커니즘을 통해 대규모 데이터 학습이 가능해 짐
- 2013년: Word2Vec
- 2018~2020년: GPT 시리즈와 BERT
- 2018년: GPT(OpenAI)와 BERT(Google)
- 6월: GPT 발표(OpenAI)
- 트랜스포머 아키텍처 기반
- 자연어 처리 분야에서 새로운 가능성을 보여줌
- 대형 언어 모델 개발의 기초를 마련함
- 1.17억개 파라미터
- 10월31일: BERT 발표(Google)
- 양방향 텍스트 이해를 가능하게 함
- NLP 작업의 성능을 크게 향상시킴
- 6월: GPT 발표(OpenAI)
- 2019~2020년: GPT-2와 GPT-3
- 2019년: GPT-2(15억개 파라미터) 발표
- 인간과 유사한 텍스트 생성 능력을 보여줌
- 2020년: GPT-3(1,750억개 파라미터) 발표
- 언어 모델로서 거의 모든 NLP 작업을 다룰 수 있음
- 번역, 질문 응답 등 다양한 작업에서 뛰어난 성능 발휘
- 일반 사용자가 API를 통해 접근할 수 있는 형태로 출시됨 (OpenAI API)
- 2019년: GPT-2(15억개 파라미터) 발표
- 2018년: GPT(OpenAI)와 BERT(Google)
- 2021~2023년: 멀티모달 모델과 대중화
- 2021년: LaMDA와 CLIP
- LaMDA(Google)
- 대화형 AI에 특화된 모델로 개발됨
- CLIP(OpenAI)
- 이미지와 텍스트를 연결하는 멀티모달 모델로 주목
- LaMDA(Google)
- 2022년: ChatGPT 출시(OpenAI)
- OpenAI가 GPT-3.5 기반 ChatGPT 출시(11월30일)
- 대중에게 LLM 기술을 소개
- 상호작용형 AI 응용 프로그램의 가능성을 보여줌
- 2023년:
- 3월: GPT-4 출시(OpenAI)
- 이전 모델(GPT-3.5) 대비 약 500배 더 큰 데이터셋 활용
- 멀티모달 기능 도입
- 11월: GPT-4 Turbo 출시(OpenAI)
- GPT-4의 경량화 버전
- 비슷한 성능에 더 빠르고 비용 효율적인 처리 가능
- 3월: GPT-4 출시(OpenAI)
- 2021년: LaMDA와 CLIP
- 2024~2025년: 모델 성능 및 비용 효율화
- 2024년:
- GPT-4o(OpenAI) 발표(5월13일)
- 텍스트와 이미지 외에도 비디오 등 다양한 형태의 멀티모달 데이터를 처리하는 기능 추가
- 언어 이해 및 생성 능력을 더욱 강화
- GPT-4o(OpenAI) 발표(5월13일)
- 2025년:
- DeepSeek(Hangzhou DeepSeek AI 연구소) 발표(1월10일)
- Mixture-of-Experts(MoE) 아키텍처를 기반으로 설계
- 효율적인 연산과 높은 성능을 제공함
- 논리적 추론, 복잡한 문제 해결, 멀티모달 학습(텍스트, 이미지, 오디오 데이터 처리) 지원
- 2024년 5월, V2가 소개되었으며 공식 발표는 V3 버전임
- DeepSeek(Hangzhou DeepSeek AI 연구소) 발표(1월10일)
- 2024년:
8. LLM의 미래 전망
- 성능 향상
- 모델 크기 증가, 새로운 아키텍처 개발, 학습 방법 개선 등을 통해
- 텍스트 생성 능력, 이해 능력, 추론 능력 등이 지속적으로 향상될 것임
- 다양한 모델 등장
- 특정 작업이나 도메인에 특화된 다양한 형태의 LLM이 등장할 것으로 예상됨
- 동시에 거의 모든 영역에서 범용적으로 사용될 수 있는 AGI(Artificial General Intelligence, 인공 일반/범용 지능)의 개발을 위해 노력 중임
- 멀티모달 학습
- 텍스트뿐만 아니라 이미지, 오디오, 비디오 등 다양한 형태의 데이터를 함께 학습하여 더욱 풍부한 정보를 이해하고 생성하는 모델이 개발될 것임
- 설명 가능성 및 제어 가능성 향상
- 모델의 의사 결정 과정을 이해하고 사용자가 원하는 대로 출력을 제어할 수 있는 기술이 발전할 것임
- 사회적 영향력 증대
- LLM은 우리의 일상생활, 산업, 과학 연구 등 다양한 분야에서 더욱 중요한 역할을 수행하며 큰 변화를 가져올 것임