Embedding 모델의 이해와 Vector DB 연동
- RAG 시스템의 엔진이라 할 수 있는 임베딩(Embedding) 모델과 그 데이터를 저장·관리하는 벡터 DB(Vector DB)의 연동은 검색의 정확도를 결정짓는 핵심 아키텍처
1. 임베딩(Embedding) 모델의 이해
1.1 임베딩과 임베딩 모델의 정의
- 임베딩
- 사람이 이해하는 자연어(비정형 데이터)를 컴퓨터가 계산할 수 있는 고정된 길이의 실수 벡터(\(Vector\))로 변환하는 과정
- 단순한 수치화가 아니라, 단어나 문장 간의 ‘의미적 유사성’을 다차원 공간상의 ‘거리’로 투영하는 것이 핵심
- 임베딩 모델
- 이산적인(Discrete) 데이터를 연속적인(Continuous) 고차원 벡터 공간으로 매핑(Mapping)하는 함수
현대 AI(LLM/RAG) 맥락에서 ‘임베딩 모델’을 정의할 때, 단순히 “변환하는 모델”이라는 ‘수행 과정’ 외에 기능적·구조적 특성이 필요함
- 임베딩 모델의 특성
- 시맨틱 추출기 (Semantic Extractor)
- 단순히 글자를 숫자로 바꾸는 것이 아니라, 문맥(Context)을 파악하여 의미적 외연을 추출함
- 동일한 단어를 서로 다른 좌표에 배치할 수 있는 능력이 임베딩 모델의 핵심 정의 중 하나
- 예: “사과를 먹다”와 “사과를 하다(사죄)”에서의 ‘사과’는 서로 다른 좌표에 배치됨
- 차원 축소 및 압축기 (Dimensionality Reduction & Compression)
- 자연어라는 무한에 가까운 희소(Sparse) 데이터를, 고정된 크기(예: 768차원, 1536차원)의 밀집(Dense) 벡터로 압축하여 표현하는 모델
- 정보의 손실을 최소화하면서 컴퓨터가 연산하기 가장 효율적인 상태로 만드는 ‘인코더(Encoder)’ 역할을 수행함
- 시맨틱 추출기 (Semantic Extractor)
- 임베딩 모델 vs 일반적 수치화의 차이
단순히 숫자로 바꾸는 것(예: ASCII 코드 변환, One-hot Encoding)과 임베딩 모델의 차이
- 일반 수치화
- 단어 간의 관계를 모름
- ‘개’와 ‘강아지’는 완전히 다른 숫자로 취급됨
- 임베딩 모델
- 학습(Training)을 통해 데이터 사이의 ‘상대적 거리’를 이미 알고 있는 모델
- 즉, “지식이 내재된 변환기”라고 정의할 수 있음
- 정리
- 임베딩 모델이란,
- 비정형 텍스트 데이터를 고차원 벡터 공간상의 좌표로 변환하여,
언어의 문맥적 의미와 상관관계를 기하학적 거리(Distance)로 치환해주는 신경망 기반의 인코더 모델- 쉽게 말해서 “학습된 지식을 바탕으로 문맥을 반영하여 좌표를 찍는 인코더“
- 참고
- 생성 모델이 “다음 단어를 예측 (Next Token Prediction)”하는 모델이라면
- 임베딩 모델은 “문장 전체를 하나의 벡터로 요약 (Sentence Representation)”하는 모델
1.2 임베딩 모델과 RAG
- 임베딩 모델과 RAG의 관계는 마치 ‘도서관의 인덱스 시스템과 사서의 답변 과정’과 같음
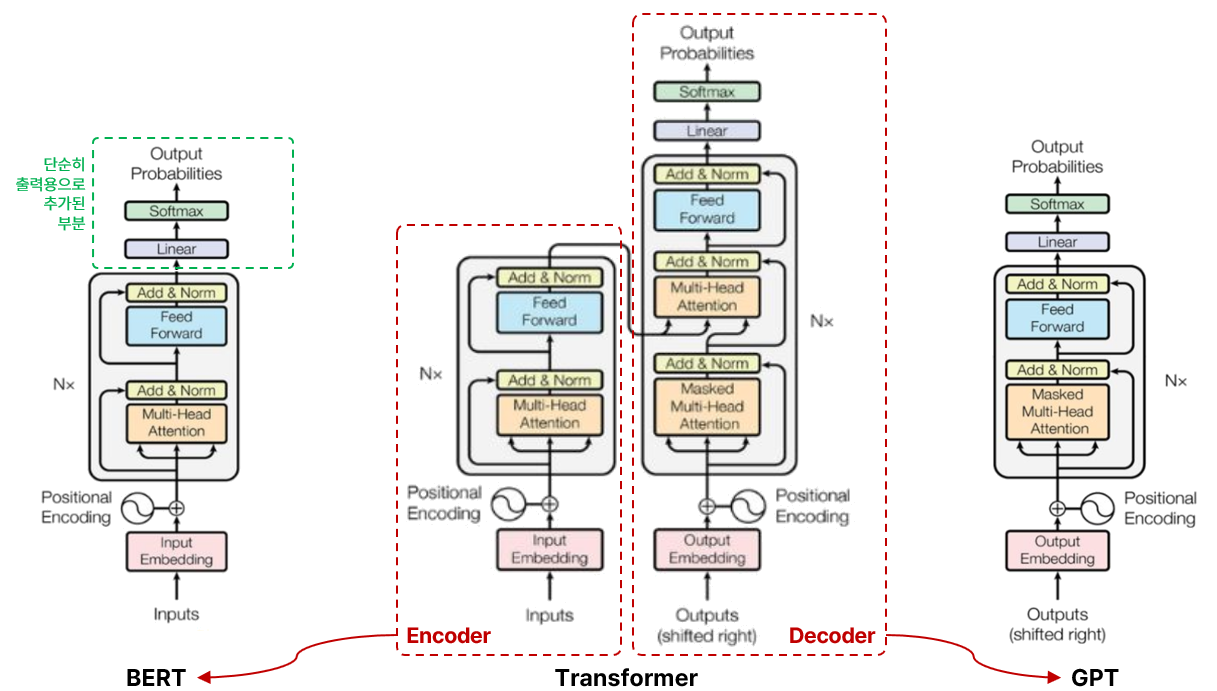
- 보통 RAG에서 말하는 임베딩 모델은 GPT와 같은 생성 모델(Decoder)이 아니라,
- 문장을 읽고 이해하는 데 특화된 BERT 계열의 인코더(Encoder) 모델을 지칭하는 경우가 많음
- 참고
- OpenAI의 GPT 발표 후, 이에 대응하기 위해 발표된 Google의 모델이 BERT
- 그러나 엄밀하게는 Google의 BERT는 생성형 모델이라고 보기는 어려움
- GPT (Decoder-only)
- “다음에 올 단어를 맞춰봐”라는 태스크(Next Token Prediction)로 학습됨
- 즉, 앞에서부터 뒤로 말을 이어 붙이는 ‘생성’에 최적화되어 있음
- BERT (Encoder-only)
- “문장 중간에 구멍(Mask)을 뚫어놓을 테니, 앞뒤 문맥을 보고 뭐가 들어갈지 맞춰봐”라는 태스크(Masked Language Model)로 학습됨
- 문장 전체를 한꺼번에 보고 ‘이해’하고 ‘분석’하는 데 몰두한 모델이지, 새로운 문장을 창조해 나가는 훈련을 받은 모델이 아님
1.3 RAG에서의 상세 역할
- 임베딩 모델과 RAG의 관계는 마치 ‘도서관의 인덱스 시스템과 사서의 답변 과정’과 같음
1.3.1 RAG 아키텍처 내에서의 역할 분담
- RAG 시스템은 크게 ‘찾는 과정(Retrieval)’과 ‘답하는 과정(Generation)’으로 나뉨
여기서 임베딩 모델과 생성 모델은 각각 전담 마크하는 영역이 다름
- 임베딩 모델 (주로 BERT 계열 / 인코더)
- 역할
- 지식 베이스(문서)를 벡터 공간에 배치하고,
- 사용자의 질문이 어떤 지식과 가까운지 ‘좌표’를 찍는 역할
- 특징
- 문맥을 양방향으로 분석하여 의미를 수치화하는 데 최적화
- 비유
- 도서관의 모든 책 내용을 수치화하여
- 어느 서가에 꽂을지 결정하는 ‘분류 전문가’
- 역할
- 생성 모델 (주로 GPT 계열 / 디코더)
- 역할
- 임베딩 모델이 찾아준 문서 조각들을 읽고,
- 사용자가 이해하기 쉬운 자연어로 ‘답변’을 재구성
- 특징
- 이전 단어를 바탕으로 다음 단어를 예측하며
- 매끄러운 문장을 만드는 데 최적화
- 비유
- 분류 전문가가 가져다준 책 정보를 읽고
- 친절하게 설명해 주는 ‘전문 상담사’
- 역할
- 참고
1.3.2 BERT와 GPT의 차이가 RAG에 주는 영향
- 두 모델의 아키텍처 차이는 RAG 시스템의 성능에 결정적인 영향을 미침
| 구분 | 임베딩 모델 (BERT 계열) | 생성 모델 (GPT 계열) |
|---|---|---|
| 방향성 | 양방향 (Bidirectional) | 단방향 (Unidirectional) |
| RAG 내 기능 | 문서 검색 (Retrieval) | 답변 생성 (Generation) |
| 핵심 역량 | 문장 간의 유사도(Distance) 계산 | 문맥에 맞는 텍스트 생성 |
| 비교 비유 | 수만 개의 후보 중 정답 후보를 추림 | 추려진 후보를 요약하여 최종 답변 작성 |
1.3.3 임베딩 모델과 RAG의 핵심 관계: ‘의미적 연결고리’
- 임베딩 모델이 RAG에서 가지는 가장 큰 의의는 비정형 데이터를 수학적 공간으로 끌어올려 GPT가 읽을 수 있게 전달한다는 점
- 단순한 데이터 전달을 넘어, 컴퓨터가 인간의 언어를 수학적인 기하학 구조로 이해하게 만드는 핵심 과정
- 지식의 구조화 (Knowledge Indexing)
- 방대한 비정형 데이터를 시스템이 즉시 탐색할 수 있는 ‘의미 지도’로 만드는 과정
- 방대한 텍스트 데이터를 BERT 계열 모델을 통해 고차원 벡터로 변환하여 벡터 DB에 저장함
- 방대한 텍스트 데이터를 BERT 계열 모델을 통해 고차원 벡터로 변환하여 벡터 DB에 저장함
- 비정형의 정형화
- PDF, 텍스트, 로그 파일 등 규칙 없는 데이터를 고정 차원(Fixed Dimension)의 실수 벡터로 변환
- 도서관의 모든 책 내용을 분석하여 특정 좌표값(\(x, y, z, ...\))을 부여하는 것과 같음
- PDF, 텍스트, 로그 파일 등 규칙 없는 데이터를 고정 차원(Fixed Dimension)의 실수 벡터로 변환
- BERT의 역할
- 문장의 앞뒤 맥락을 모두 고려하여(Bidirectional),
- 단어가 가진 다의성을 해결하고 핵심 의미를 추출
- 벡터 DB 저장
- 변환된 벡터들을 단순한 파일 시스템이 아닌, 벡터 전용 데이터베이스에 저장
- 이때 유사도 검색을 가속화하기 위한 인덱싱(HNSW 등)이 수행되어 검색 준비를 완료
- 방대한 비정형 데이터를 시스템이 즉시 탐색할 수 있는 ‘의미 지도’로 만드는 과정
- 질의의 수치화 (Query Vectorization)
- 사용자의 추상적인 질문을 시스템이 이해할 수 있는 ‘수학적 타겟’으로 변환하는 실시간 프로세스
- 사용자의 질문이 들어오면 실시간으로 동일한 임베딩 모델을 사용하여 벡터화를 수행함
- 사용자의 질문이 들어오면 실시간으로 동일한 임베딩 모델을 사용하여 벡터화를 수행함
- 실시간 변환
- 사용자가 “작년 스마트팩토리 A라인의 불량률 원인은?”이라고 묻는 순간,
- 이 문장은 지식 구조화 때와 동일한 임베딩 모델을 통과하여 벡터화됨
- 모델 일치성(Consistency)의 중요성:
- 전체 RAG 시스템의 규격(Standard) 역할을 수행
- 만약 지식 저장 시와 질문 변환 시의 모델이 다르면,
- 같은 단어라도 좌표값이 다르게 찍혀 검색이 불가능해짐
- 전체 RAG 시스템의 규격(Standard) 역할을 수행
- 의도 추출:
- 질문에 포함된 대명사나 중의적인 표현을 수치 공간상의 특정 위치로 치환
- 키워드 검색의 한계를 극복
- 질문에 포함된 대명사나 중의적인 표현을 수치 공간상의 특정 위치로 치환
- 사용자의 추상적인 질문을 시스템이 이해할 수 있는 ‘수학적 타겟’으로 변환하는 실시간 프로세스
- 수학적 매칭 (Similarity Search)
- 벡터 공간상에서 질문과 가장 가까운 지식을 찾아내는 ‘기하학적 연산’ 단계
- 질문 벡터와 DB 내 문서 벡터 간의 코사인 유사도 등을 계산하여 가장 관련 있는 컨텍스트를 추출함
- 질문 벡터와 DB 내 문서 벡터 간의 코사인 유사도 등을 계산하여 가장 관련 있는 컨텍스트를 추출함
- 코사인 유사도(Cosine Similarity):
- 두 벡터 사이의 각도를 계산하여 의미적 유사성을 판별
- 수학적으로는 두 벡터의 내적(\(A \cdot B\))을 각 크기의 곱으로 나눈 값(\(\cos \theta\))
- 이 값이 1에 가까울수록 의미가 일치함을 뜻함
- 고속 검색:
- 수만 개의 데이터 중 질문과 가장 가까운 상위 \(k\)개(Top-k)의 문서 조각을 검색
- 의의:
- “불량률 원인”이라는 질문 벡터 근처에 있는 “공정 온도 최적화 실패”, “센서 데이터 오류” 등의 문서 조각들이
- 이 수학적 매칭을 통해 수면 위로 떠오름
- 벡터 공간상에서 질문과 가장 가까운 지식을 찾아내는 ‘기하학적 연산’ 단계
- GPT로의 전달 (Context Augmentation)
- 찾아낸 지식을 생성 모델이 읽을 수 있는 형태로 재구성하여 전달하는 ‘정보 보강’ 단계
- 추출된 텍스트를 GPT의 프롬프트에 삽입(Augmentation)하여, GPT가 학습하지 않은 외부 지식을 바탕으로 말할 수 있게 함
- 추출된 텍스트를 GPT의 프롬프트에 삽입(Augmentation)하여, GPT가 학습하지 않은 외부 지식을 바탕으로 말할 수 있게 함
- 프롬프트 주입:
- 수학적 매칭으로 찾은 텍스트 조각들을 원래의 사용자 질문과 결합
- 이를 ‘컨텍스트(Context)’라고 부름
- 수학적 매칭으로 찾은 텍스트 조각들을 원래의 사용자 질문과 결합
- 할루시네이션 방지:
- GPT에게 “네 지식으로 답하지 말고, 내가 지금 준 이 문서 내용 안에서만 답해”라는 제약을 부여
- GPT는 이제 학습 데이터(내부 기억)가 아닌, 전달받은 외부 지식을 바탕으로 추론을 시작함
- 최종 생성:
- GPT(디코더)는 전달된 텍스트를 읽고
- 사용자가 이해하기 쉬운 자연스러운 문장으로 정리하여 답변을 출력
- 찾아낸 지식을 생성 모델이 읽을 수 있는 형태로 재구성하여 전달하는 ‘정보 보강’ 단계
- 공학적 관점에서의 연결고리
- 임베딩 모델은 강력한 해시 함수(하지만 의미를 보존하는)이며,
- RAG는 그 해시값을 기반으로 실시간으로 Join 연산을 수행하여 정보를 보충하는 동적 시스템
- 결국 임베딩 모델이 언어의 의미를 정확한 좌표로 찍어주어야만, GPT라는 상담사가 올바른 자료를 읽고 정확한 답변을 내놓을 수 있음
- 이 과정에서 BERT(인코더)의 ‘정교한 이해’와 GPT(디코더)의 ‘유연한 표현’이 완벽한 시너지를 이루게 됨
- 실제 RAG를 구현할 때, “임베딩 모델(BERT)이 멍청하면 GPT가 아무리 똑똑해도 소용없다”는 점이 핵심
- Garbage In, Garbage Out
- 임베딩 모델이 질문의 의도를 잘못 파악하여 엉뚱한 문서 조각을 GPT에게 전달하면,
- GPT는 그 잘못된 정보를 바탕으로 아주 그럴싸한 거짓말(할루시네이션)을 하게 됨
- 최신 트렌드
- 최근에는 GPT-4와 같은 거대 모델 자체가 임베딩 API(
text-embedding-3-large등)를 제공하기도 하지만,- 보안이나 비용이 중요한 기업용/개인용 에이전트에서는 여전히 BERT 계열의 가벼운 오픈소스 모델(BGE, RoBERTa 등)을 임베딩 전용으로 즐겨 사용함
- 결국 RAG는 BERT의 ‘정교한 검색’과 GPT의 ‘유연한 생성’이 만나, 모델의 한계를 외부 지식으로 돌파하는 협업의 산물이라고 정의할 수 있음
1.4 RAG의 메커니즘
- RAG(검색 증강 생성)의 성능을 결정짓는 핵심은 결국 ‘언어의 수학적 추상화’
- 임베딩 모델이 어떻게 비정형 데이터를 기계가 다루기 좋은 수치 체계로 변환하는지가 핵심 메커니즘
- 시맨틱 공간(Semantic Space) 생성: 의미의 기하학적 배치
- 임베딩 모델은 학습 과정을 통해 수만 개의 단어와 문장 사이의 상관관계를 학습함
- 학습을 통해 단순히 글자 모양을 비교하는 것이 아니라, 고차원 공간상에 의미에 따른 ‘좌표’를 부여
- 모델은 학습을 통해 “사과”와 “배”가 “자동차”보다 가깝다는 것을 \(n\)차원 벡터 공간 내의 좌표로 표현
- 매커니즘
- 모델은 거대한 말뭉치를 학습하며 함께 자주 등장하는 단어들은 가깝게, 그렇지 않은 단어들은 멀게 배치하는 최적화 과정을 거침
- 예시
- $n$차원 공간에서 “사과”(\(V_{apple}\))와 “배”(\(V_{pear}\))의 벡터 거리는 매우 가까움
- 반면 “자동차”(\(V_{car}\))는 과일들과는 전혀 다른 군집(Cluster)에 위치하게 됨
- 의의
- 이를 통해 RAG는 “달콤한 과일 추천해줘”라는 질문에 대해,
- ‘달콤한’, ‘과일’이라는 키워드가 문서에 직접 없더라도 그 근처 좌표에 있는 “사과”나 “배” 관련 문서를 찾아낼 수 있음
- 고정 차원(Fixed Dimension): 시스템 정합성의 규격
- 모델마다 출력하는 벡터의 차원(예: OpenAI
text-embedding-3-small은 1536차원)이 정해져 있음 - 이는 벡터 DB 설계 시 반드시 일치시켜야 하는 규격
- 모델마다 출력하는 벡터의 차원(예: OpenAI
- Contextual Representation
- 최근의 임베딩 모델(BERT 계열 등)은 문장 전체의 맥락을 파악하여 벡터를 생성함
- 이를 통해 단어의 중의성을 효과적으로 해결
2. 벡터 DB(Vector DB) 연동의 핵심 원리
▣ 일반적 설명
벡터 DB는 수만 차원의 벡터 데이터를 저장하고, 특정 벡터와 가장 ‘가까운’ 데이터를 초고속으로 찾아내기 위해 설계된 특수 데이터베이스입니다. 일반적인 RDBMS가 B-Tree 인덱스를 사용한다면, 벡터 DB는 거리 계산에 특화된 알고리즘을 사용합니다.
◈ RAG에서의 상세 연동 프로세스
실제 개발 시 임베딩 모델과 벡터 DB는 다음과 같은 유기적인 흐름으로 연동됩니다.
① 스키마 설계 및 인덱싱 (Data Ingestion)
- Vector Field: 임베딩 모델이 생성한 벡터가 담기는 필드입니다. 차원 수(Dimension)와 거리 측정법(Metric)을 설정합니다.
- Payload/Metadata: 원본 텍스트, 문서 출처, 생성일 등을 함께 저장하여 검색 후 LLM에게 전달할 컨텍스트를 확보합니다.
- 인덱스 알고리즘 선택: * HNSW (Hierarchical Navigable Small World): 그래프 기반으로 가장 많이 쓰이며, 속도와 정확도의 밸런스가 좋습니다.
- IVF (Inverted File Index): 공간을 클러스터링하여 검색 범위를 좁히는 방식으로 메모리 효율이 좋습니다.
② 거리 측정법 (Distance Metrics)
연동 시 어떤 수학적 거리 함수를 쓸지 결정해야 합니다.
- Cosine Similarity: 벡터의 방향성(각도)을 측정합니다. 텍스트 유사도 검색에서 가장 표준적으로 사용됩니다.
- L2 Distance (Euclidean): 점과 점 사이의 직선거리를 측정합니다. 이미지 유사도나 고정된 크기의 데이터에 유리합니다.
- Dot Product: 두 벡터의 내적을 계산합니다. 가중치가 포함된 추천 시스템 등에서 주로 쓰입니다.
3. 모델과 DB 연동 시 주의사항 (Engineering Point)
박사님께서 직접 시스템을 구축하실 때 고려해야 할 기술적 디테일입니다.
- 임베딩 모델의 일관성 (Model Consistency):
- 절대 주의: 데이터를 DB에 넣을 때 사용한 임베딩 모델과, 사용자의 질문을 변환하는 임베딩 모델은 반드시 동일해야 합니다. 모델이 다르면 같은 단어도 전혀 다른 좌표에 찍히게 되어 검색이 불가능합니다.
- 차원 수 정합성:
- 벡터 DB의 컬럼 크기(Dimension)는 임베딩 모델의 출력 크기와 1:1로 매칭되어야 합니다. (예: 1536차원 모델 사용 시 DB 설정도 1536)
- 처리 성능 (Throughput):
- 대규모 ERP나 스마트팩토리 로그 데이터를 실시간으로 처리할 때는 Batch Embedding을 지원하는 라이브러리를 사용하여 DB 인서트 성능을 최적화해야 합니다.
- 로컬 vs 클라우드:
- 보안이 중요한 기업 내부용이라면 HuggingFace의 오픈소스 모델(BGE, RoBERTa 등)을 로컬 GPU에서 돌리고, Milvus나 FAISS를 온프레미스로 연동하는 아키텍처가 적합합니다.
요약: 임베딩과 벡터 DB의 관계
| 단계 | 역할 | 비유 | | :— | :— | :— | | Embedding | 자연어를 좌표(수치)로 변환 | 주소를 위도/경도로 변환하는 과정 | | Vector DB | 좌표 기반의 고속 검색 저장소 | 위도/경도 데이터가 저장된 내비게이션 지도 | | 연동 핵심 | 모델 규격 일치 및 인덱싱 최적화 | 정확한 지도 데이터와 GPS 수신기의 규격을 맞추는 것 |
이 매커니즘을 이해하고 나면, 단순한 검색을 넘어 박사님의 전문 분야인 주식 투자 분석에서 차트 패턴의 유사성을 벡터화하여 검색하거나, 스마트팩토리의 이상 징후 로그를 벡터 공간상에서 탐지하는 응용도 가능해집니다.