Apache Iceberg 개요 및 설치, 환경설정
1. 데이터 레이크(Data Lake)
- 정의
- 정형, 반정형, 비정형 등 다양한 형태의 모든 원시 데이터(Raw Data)를 가공하지 않은 상태로 한곳에 중앙 집중식으로 저장하는 거대한 저장소
- 비유하자면
- 기존의 데이터 웨어하우스(DW)가 정제된 데이터만 담는 ‘생수 수조’라면,
- 데이터 레이크는 강물, 빗물, 지하수 등 온갖 원천 데이터가 가공 없이 그대로 흘러 들어오는 ‘거대한 호수’에 비유할 수 있음
- 주요 특징 (Core Characteristics)
- 원시 데이터 그대로 저장 (Raw Data Storage):
- 텍스트, 로그, 이미지, 비디오, JSON, RDBMS 테이블 등 출처와 형식을 가리지 않고 훼손 없이 원본 그대로 보관함
- Schema-on-Read (읽기 시점 스키마 정의):
- 데이터를 저장할 때 미리 구조(Schema)를 정의하지 않음
- 우선 저장(Write)부터 해 두고,
- 나중에 데이터를 분석하거나 AI 모델링을 위해 읽어올 때(Read) 필요한 형태로 구조를 정의하여 사용
- 뛰어난 확장성과 저렴한 비용:
- HDFS나 클라우드 오브젝트 스토리지(AWS S3, Google Cloud Storage 등)를 기반으로 구축
- 페타바이트(PB) 이상의 대용량 데이터도 저렴한 비용으로 유연하게 저장 공간을 확장할 수 있음
- 분석 및 AI/ML 유연성:
- 데이터가 가공되지 않은 상태로 유지됨
- 데이터 사이언티스트나 분석가가 목적에 맞게 가공하여 BI 리포팅, 데이터 마이닝, 머신러닝(ML) 학습 등 다각도로 활용할 수 있음
- 원시 데이터 그대로 저장 (Raw Data Storage):
- 요약
- 데이터 레이크는
- 나중에 어떻게 쓸지 모르는 대규모 원시 데이터를 저비용으로 모아두고,
- 필요할 때마다 꺼내어 다목적(분석, AI 등)으로 활용하는 데이터 인프라
- 메타데이터 관리가 부실하면 쓸모없는 데이터만 가득 찬 ‘데이터 늪(Data Swamp)’이 될 수 있음
- 최근, 이를 보완하기 위해 Apache Iceberg 같은 테이블 포맷을 도입하여 레이크하우스(Lakehouse) 형태로 발전하는 추세
2. Apache Iceberg 개요
2.1 정의 및 핵심 철학
- 정의
- 거대한 규모의 데이터 레이크(Data Lake) 환경에서 신뢰성과 성능을 제공하기 위해 설계된 오픈 소스 고성능 테이블 포맷(Table Format)
- 오브젝트 스토리지 위에서 RDBMS와 같은 ACID 트랜잭션을 구현한 추상화 계층의 위치
- 페타바이트(PB) 규모의 대형 테이블을 위한 개방형 테이블 규격
- 핵심 철학:
- 컴퓨팅 엔진(Spark, Flink, Trino 등)과 데이터 저장소(S3, Azure Blob, HDFS) 사이에서 독립적인 테이블 추상화 레이어를 제공하여 “엔진 독립성”을 유지
2.2 개발 역사
- 태동기(2017년) : 넷플릭스(Netflix) 사내 프로젝트로 출발
- 대규모 분석 데이터셋 관리를 위해 Apache Hive 테이블 포맷을 사용 중, 데이터의 규모가 페타바이트(PB) 규모로 거대화됨
- Apache Hive의 ‘디렉터리 기반 추적’ 방식의 한계
- 수천 개의 파티션을 디렉터리 리스팅(Listing)하는 데만 수분이 소요됨
- 동시 쓰기 작업 시 데이터가 깨지는 고질적인 정합성 문제
- Hive의 한계를 극복하기 위한 프로젝트로 개발 시작
- 넷플릭스의 엔지니어 라이언 블루(Ryan Blue)와 단 위크스(Dan Weeks)
- 디렉터리가 아닌 ‘파일 단위’로 스냅샷을 추적하는 새로운 테이블 포맷 사양을 설계하기 시작
- 오픈소스 전환기 (2018년 ~ 2020년) : 아파치 재단 기증 및 탑레벨 프로젝트 등극
- 2018년 11월:
- 전 세계 데이터 엔지니어링 커뮤니티의 참여와 엔진 독립성을 보장하기 위해 Iceberg 프로젝트를 오픈소스로 공개
- 아파치 소프트웨어 재단(ASF) 인큐베이터에 기증 🡲 현재는 아파치 소프트웨어 재단에서 관리 중
- 2020년 5월:
- 프로젝트의 성숙도와 커뮤니티 확장성을 인정받아 아파치 재단의 탑레벨 프로젝트(Top-Level Project, TLP)로 공식 졸업
- 이 시기를 기점으로 에어비앤비(Airbnb), 애플(Apple), 익스피디아(Expedia), 링크드인(LinkedIn) 등 글로벌 빅테크 기업들이 프로덕션 환경에 Iceberg를 대거 채택하기 시작
- 2018년 11월:
- 사양(Specification)의 진화와 생태계 확장 (2021년 ~ 2024년)
- Iceberg는 기능을 고도화하며 버전 스펙(Spec)을 점진적으로 발표
- Spec V1 (Analytic Tables):
- 대규모 분석용 불변 데이터 파일(Parquet, ORC, Avro)에 RDBMS 수준의 ACID 트랜잭션과 스키마 진화를 제공하는 기반 확림
- Spec V2 (Row-level Updates/Deletes):
- 2021~2022년경 확정된 스펙
- 데이터 레이크하우스에서 가장 까다로웠던 행 단위의 즉각적인 수정/삭제(Upsert/Delete)를 지원하기 위해 Merge-on-Read(MoR) 메커니즘 도입
- 상업적 생태계 폭발 (2024년):
- Snowflake, Google Cloud(BigQuery), AWS 등이 Iceberg를 자사 플랫폼의 핵심 외부 테이블 포맷으로 기본 지원 시작
- 2024년 6월, 데이터브릭스(Databricks)가 Iceberg 메인 관리 기업인 ‘타불러(Tabular)’를 인수 🡲 메이저 진영 간의 포맷 표준화 경쟁이 Iceberg 중심으로 크게 기울게 됨
- Spec V1 (Analytic Tables):
- Iceberg는 기능을 고도화하며 버전 스펙(Spec)을 점진적으로 발표
- 현대 및 미래 (2025년 ~ 2026년 현재) : 차세대 Spec V3 도입과 천하통일
- Spec V3 출시:
- 최근 정식 지원되기 시작
- 읽기 성능 오버헤드를 극적으로 줄여주는 바이너리 삭제 벡터(Deletion Vectors) 도입
- 반정형 JSON 데이터를 고속 파싱할 수 있는 Variant 타입 표준 도입
- 현재 상태:
- 특정 컴퓨팅 엔진이나 벤더(Vendor Lock-in)에 종속되지 않는 ‘진정한 오픈 레이크하우스의 표준 레이어’로 완벽하게 자리 잡음
- 클라우드뿐만 아니라 온프레미스 스마트팩토리 AI 인프라 등 이기종 데이터 소스를 통합해야 하는 엔터프라이즈 환경에서 필수 아키텍처로 다뤄짐
- Spec V3 출시:
- 아파치 아이스버그(Apache Iceberg)의 개발 역사는 빅데이터 생태계가
- ‘하둡(Hadoop) 중심의 파일/디렉터리 관리’에서 ‘클라우드 오브젝트 스토리지 중심의 데이터 레이크하우스(Lakehouse)’로
- 패러다임이 전환되는 과정을 그대로 담고 있음
2.3 주요 아키텍처 (3 Layer 구조)
- 메타데이터를 계층화하여 관리함으로써 성능과 안정성을 확보함
- 디렉터리 경로가 아닌 파일 중심의 트리 구조 메타데이터를 통해 스냅샷을 관리
- 이 구조 덕분에 O(1)에 가까운 속도로 쿼리 플래닝이 가능함
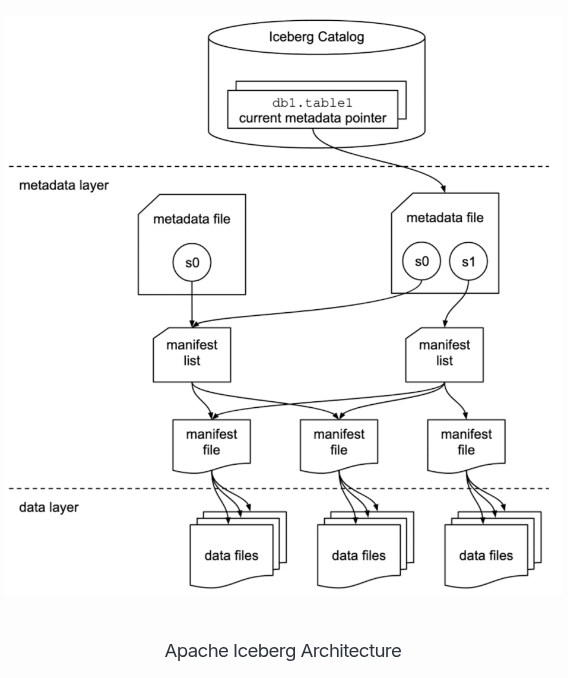
- Catalog Layer:
- 최신 메타데이터 포인터(
version-hint.text)를 관리하는 루트 계층- REST Catalog, AWS Glue, Hive Metastore 등
- 현재 테이블의 최신 상태(Current Metadata File)가 어디인지 가리키는 포인터 역할
- 최신 메타데이터 포인터(
- Metadata Layer:
- Metadata File (
.json):- 테이블의 ‘상태 변경 이력’을 기록
- 스키마, 파티션 명세, 그리고 각 시점의 스냅샷(Snapshot) ID를 포함
- Manifest List (
.avro):- 특정 스냅샷 시점에 유효한 Manifest 파일들의 목록 관리
- 각 Manifest 파일이 담고 있는 데이터의 통계 정보(파티션 범위 등)를 관리
- Manifest File (
.avro):- 실제 데이터 파일(
.parquet,.orc등)의 절대 경로와 행(Row) 개수, 컬럼별 최소/최대값(Min/Max) 등의 통계 정보 보유 - 쿼리 엔진은 이 단계를 읽고 불필요한 데이터 파일을 원천 배제(Data Skipping)함
- 쿼리 시 불필요한 파일을 건너뛰게(Pruning) 함
- 실제 데이터 파일(
- Metadata File (
- Data Layer:
- 실제 데이터가 저장되는 레이어
2.4 핵심 동작 메커니즘 및 고급 기능
- 낙관적 동시성 제어 (Optimistic Concurrency Control, OCC) 기반 ACID
- 여러 쓰기 작업(Writers)이 동시에 발생할 때 서로 충돌하지 않는다고 가정하고 각자 스냅샷을 준비함
- 여러 프로세스가 동시에 데이터를 쓰거나 읽어도 데이터의 일관성을 유지함 🡲 ACID 트랜잭션 보장
- 커밋 시점에 다른 작업이 먼저 메타데이터 포인터를 업데이트했다면,
- 내 작업을 취소하고
- 변경된 최신 상태 위에서 자동 재시도(Atomic Swap & Retry)를 수행하여
- 데이터 일관성을 유지함
- 커밋 시점에 다른 작업이 먼저 메타데이터 포인터를 업데이트했다면,
- 단순히 ACID 보장을 넘어, 낙관적 동시성 제어를 기반으로 직렬 가능성(Serializability) 또는 스냅샷 격리(Snapshot Isolation)를 제공
- 타임 트래블 및 롤백 (Time Travel):
- 특정 시점의 스냅샷으로 쿼리를 실행하거나, 잘못된 업데이트 발생 시 이전 상태로 복구할 수 있음
- 숨겨진 파티셔닝 (Hidden Partitioning) & 파티션 진화
- Hidden Partitioning:
- 사용자가 쿼리에 파티션 컬럼을 명시하지 않아도, Iceberg가 데이터의 상관관계를 파악해 필요한 파티션만 읽음
- 유저가
WHERE timestamp >= ...로 조회하면,- Iceberg가 내부에 정의된 파티션 함수(예:
days(timestamp))를 식별하여 - 알아서 해당 파티션만 읽음
- Iceberg가 내부에 정의된 파티션 함수(예:
- 유저가 쿼리에
WHERE date_col = ...을 직접 매핑해 줄 필요가 없음
- Partition Evolution:
- 파티션 구조 변경 시에도 과거 쿼리를 수정할 필요가 없음
- 컬럼 추가, 삭제, 이름 변경, 타입 변경 시 데이터 파일을 다시 쓰지 않고 메타데이터만 업데이트하여 즉각 반영
- 데이터 규모가 커져서 일별(Daily) 파티션을 월별(Monthly)로 바꾸더라도, 과거 데이터를 재배치(Rewrite)할 필요가 없음
- 메타데이터에 파티션 버전(Partition Spec)을 기록하여,
- 이전 데이터는 과거 규칙대로,
- 신규 데이터는 새 규칙대로
- 하나의 테이블 안에서 동시 조회
- 파티션 구조 변경 시에도 과거 쿼리를 수정할 필요가 없음
- Hidden Partitioning:
- 행 단위 변경 전략 (CoW vs MoR)
- Iceberg는 데이터의 특성(배치 위주 vs 스트리밍/CDC 위주)에 따라 두 가지 쓰기 모드를 지원함
- Copy-on-Write (CoW):
- 특정 행이 업데이트/삭제되면 🡲 해당 행이 속한 데이터 파일 전체를 새로 씀
- (읽기 속도 최적화)
- Merge-on-Read (MoR):
- 기존 데이터 파일은 그대로 두고,
- 변경된 행의 위치나 조건만 담은 삭제 파일(Delete File)을 따로 기록한 뒤 읽기 시점에 병합
- (쓰기 속도 최적화)
- Copy-on-Write (CoW):
- Iceberg는 데이터의 특성(배치 위주 vs 스트리밍/CDC 위주)에 따라 두 가지 쓰기 모드를 지원함
- 최신 Iceberg V3 스펙의 진화
- 바이너리 삭제 벡터 (Deletion Vectors):
- V2의 MoR 방식에서 발생하던 삭제 파일 누적 문제를 해결하기 위해,
- 비트맵 형태의 고성능 바이너리 삭제 벡터를 도입 🡲 읽기 병합 오버헤드를 극적으로 줄임
- Variant 타입 지원:
- 반정형 데이터(JSON)를 파켓(Parquet) 내부에 효율적인 바이너리 트리 구조로 저장
- 스키마 변동이 심한 데이터도 고속으로 쿼리할 수 있게 됨
- 바이너리 삭제 벡터 (Deletion Vectors):
2.5 장단점 분석
- 장점 (Pros)
- 성능 최적화:
- 파일 단위의 통계(Min/Max)를 메타데이터에 들고 있어 쿼리 실행 시 I/O를 획기적으로 줄임
- 엔진 범용성:
- Spark, Trino, Flink, Hive, Presto 등 다양한 컴퓨팅 엔진에서 동일한 테이블에 접근 가능
- 신뢰성:
- 쓰기 작업 중 장애가 발생해도 Snapshot 방식 덕분에 데이터 오염이 발생하지 않음
- 저렴한 비용:
- 비싼 데이터 웨어하우스(DW) 대신 S3 같은 저렴한 오브젝트 스토리지를 DW처럼 활용(Lakehouse)할 수 있음
- 벤더 락인(Lock-in) 해제:
- 특정 솔루션에 종속되지 않는 REST Catalog 표준 사양을 제시
- 하나의 데이터(S3)를 두고 AWS EMR(Spark), Trino, Snowflake가 동시에 읽고 쓸 수 있는 진정한 오픈 레이크하우스 인프라를 가능하게 함
- 안정적인 대규모 파일 스캔:
- 수십억 개의 파일이 있는 초거대 테이블에서도 메타데이터 수준에서 쿼리 대상을 확 줄여줌
🡲 오브젝트 스토리지의LISTAPI 호출 비용과 쿼리 플래닝 타임을 최소화
- 수십억 개의 파일이 있는 초거대 테이블에서도 메타데이터 수준에서 쿼리 대상을 확 줄여줌
- 성능 최적화:
- 단점 (Cons)
- 주기적인 메타데이터 관리(Compaction) 필수:
- 스냅샷이 쌓일수록 메타데이터 파일이 늘어남
- MoR 방식을 쓰거나 스트리밍 인프라(Flink 등) 연결 시 작은 파일과 삭제 파일이 폭발적으로 늘어남
- 주기적으로 오래된 스냅샷을 삭제하고 데이터 파일을 병합(Compaction)하는 관리 작업이 필요함
- 주기적으로 병합해주는
optimize및 오래된 스냅샷을 정리하는expire_snapshots관리 파이프라인을 필수적으로 구축·운영해야 성능 저하를 막을 수 있음
- 주기적으로 병합해주는
- 스냅샷이 쌓일수록 메타데이터 파일이 늘어남
- 작은 파일 문제:
- 실시간 스트리밍으로 데이터를 넣을 경우 작은 파일(Small Files)이 많이 생성되어 성능이 저하될 수 있음
- 별도의 튜닝이 필수적
- 쓰기 동시성 충돌 (OCC Conflict):
- 마이크로 배치나 실시간 인프라에서 수많은 컴포넌트가 한 테이블에 동시다발적으로 쓰기를 시도하면
🡲 커밋 충돌로 인한 재시도 횟수가 늘어나고, 심할 경우 쓰기 실패가 발생할 수 있음 (이 경우 Hudi가 더 유리할 수 있음)
- 마이크로 배치나 실시간 인프라에서 수많은 컴포넌트가 한 테이블에 동시다발적으로 쓰기를 시도하면
- 학습 곡선:
- 기존 Hive 방식과는 아키텍처가 다르므로 운영 조직의 이해도가 요구됨
- 기존의 데이터 레이크 방식
- 데이터를 파일 시스템(HDFS, S3 등)의 ‘디렉터리 구조’로 관리함
- 예: Hive 등
- Iceberg의 데이터 레이크 방식
- ‘파일 단위’의 스냅샷을 통해 테이블의 상태를 추적함
- 기존의 데이터 레이크 방식
- 기존 Hive 방식과는 아키텍처가 다르므로 운영 조직의 이해도가 요구됨
- 주기적인 메타데이터 관리(Compaction) 필수:
- 타 포맷(Delta Lake, Hudi) 대비 장단점 비교
| 비교 항목 | Apache Iceberg | Delta Lake | Apache Hudi |
|---|---|---|---|
| 거버넌스 | 완전 개방형 (ASF) | Linux Foundation (실질적 Databricks 주도) | 개방형 (ASF) |
| 엔진 독립성 | 최상 (Spark, Trino, Flink, Snowflake, BigQuery 등 대등하게 지원) | Spark / Databricks 최적화 (타 엔진 지연 지원 존재) | Spark / Flink 중심 |
| 파티셔닝 | 숨겨진 파티셔닝 & 진화 지원 | 컬럼 매핑 기반 제한적 지원 | 수동 관리 필요 |
| 주요 활용처 | 멀티 엔진 기반 오픈 레이크하우스 | Databricks 중심 에코시스템 | 대규모 무중단 스트리밍 및 CDC |
2.6 활용도 (Use Cases)
- 데이터 레이크하우스 구축:
- AWS S3나 Azure Data Lake Storage 위에서 DW 기능을 구현할 때 핵심 기술로 사용됨
- 실시간 및 배치 통합 처리:
- Flink를 이용한 실시간 CDC(Change Data Capture) 데이터를 Iceberg에 적재
- 동시에 Spark로 배치 분석을 수행하는 아키텍처에 적합함
- 머신러닝(ML) 데이터 관리:
- AI 연구 시 데이터 재현성(Reproducibility)이 중요함
- 타임 트래블 기능을 통해 특정 시점의 학습 데이터를 정확히 추출할 수 있음
- 규제 준수 (GDPR/CCPA):
- 특정 사용자의 데이터를 삭제해야 할 때, 기존 파일 시스템 방식보다 훨씬 정교하고 안전하게 레코드 단위 삭제를 처리할 수 있음
- Apache Iceberg는
- 스토리지 비용은 데이터 레이크 수준으로 낮추고, 데이터 관리는 RDBMS/DW 수준으로 끌어올리는 표준 프레임워크
- 특히 특정 벤더에 종속되지 않고 Spark(배치 처리), Flink(실시간 스트리밍), Trino(Ad-hoc 대화형 쿼리) 등 다양한 이기종 엔진을 융합하여 데이터 플랫폼을 설계할 때 가장 강력한 시너지를 발휘함
- 실무 도입 시에는 작은 파일 병합 전략(Compaction 튜닝)과 비즈니스 요구사항에 맞는 CoW/MoR 전략 선택이 성공의 핵심 요인
3. Apache Iceberg 환경 설정
- Iceberg는 컴퓨팅 엔진이 아니라 ‘파일을 배치하는 규격(Spec)’이자 ‘메타데이터 명세’임
- 기본 기능을 중심으로 할 때
- Python 코드 몇 줄만으로도 데이터를 읽고 쓰며 Iceberg의 메타데이터 트리 구조가 어떻게 생성되는지 완벽하게 확인할 수 있음
- 최소 아키텍처
- Client: PyIceberg (순수 파이썬 라이브러리, 가볍고 독립적임)
- Catalog: Iceberg REST Catalog (테이블의 최신 포인터만 관리)
- Storage: MinIO (실제 메타데이터
.json파일과 데이터.parquet파일이 저장되는 곳)
3.1 예제 1번 (REST Catalog 사용)
환경 구축 (Docker Compose & Python)
[1 단계]
docker-compose.yml작성 및 실행version: '3.8' services: # 1. 실제 파일들이 저장될 오브젝트 스토리지 (latest 버전으로 수정) minio: image: minio/minio:latest container_name: minio ports: - "9000:9000" # API 포트 - "9001:9001" # 웹 관리 콘솔 포트 environment: - MINIO_ROOT_USER=admin - MINIO_ROOT_PASSWORD=password command: server /data --console-address ":9001" # 2. MinIO 기동 시 'warehouse' 버킷을 자동으로 생성해주는 유틸리티 (latest 버전으로 수정) mc: image: minio/mc:latest depends_on: - minio entrypoint: > /bin/sh -c " until (/usr/bin/mc alias set myminio http://minio:9000 admin password); do echo 'Waiting for MinIO...'; sleep 1; done; /usr/bin/mc mb myminio/warehouse; exit 0;" # 3. Iceberg의 두뇌 역할을 하는 카탈로그 서버 rest-catalog: image: tabulario/iceberg-rest:0.7.0 container_name: iceberg-rest-catalog ports: - "8181:8181" environment: - CATALOG_WAREHOUSE=s3a://warehouse/ - CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO - CATALOG_S3_ENDPOINT=http://minio:9000 - CATALOG_S3_PATH_STYLE_ACCESS=true - AWS_ACCESS_KEY_ID=admin - AWS_SECRET_ACCESS_KEY=password depends_on: - minio- 터미널에서
docker-compose up -d를 실행하여 컨테이너 구동
- 터미널에서
- [2 단계] 로컬 Python 환경 설정 (PyIceberg 설치)
- 로컬 PC 또는 개발 서버의 가상환경에서 아래 명령어로 Iceberg 조작을 위한 파이썬 패키지 설치
- PyArrow 기반으로 작동하므로 매우 빠르고 가벼움
pip install "pyiceberg[s3fs,pyarrow]"
- [3 단계] Iceberg 조작 및 메타데이터 추적 (Python)
- 실제 저장소(MinIO)에 어떤 파일들이 파일 단위로 꼽히는지 확인하기
from pyiceberg.catalog import load_catalog from pyiceberg.exceptions import NamespaceAlreadyExistsError, TableAlreadyExistsError import pyarrow as pa # 1. Docker로 띄운 중앙 집중형 REST 카탈로그와 MinIO 스토리지 정보 설정 # (중앙 REST 서버인 8181 포트를 통해 메타데이터를 통합 제어하는 정석 구조) catalog = load_catalog( "default", **{ "type": "rest", "uri": "http://localhost:8181", "s3.endpoint": "http://localhost:9000", "s3.access-key-id": "admin", "s3.secret-access-key": "password", } ) # 2. 네임스페이스(RDBMS의 Database 개념) 생성 및 예외 처리 try: catalog.create_namespace("factory_db") print("네임스페이스(factory_db) 생성 완료!") except NamespaceAlreadyExistsError: print("네임스페이스가 이미 존재하여 다음 단계로 진행합니다.") except Exception as e: print(f"네임스페이스 생성 중 예상치 못한 오류 발생: {e}") # 3. PyArrow를 이용해 테이블 구조(Schema) 정의 schema = pa.schema([ ("sensor_id", pa.string()), ("reading", pa.float64()), ]) # 4. Iceberg 테이블 생성 및 멱등성 보장 try: table = catalog.create_table("factory_db.sensors", schema=schema) print("Iceberg 테이블(factory_db.sensors) 신규 생성 완료!") print(" └ [저장소 확인 포인트] MinIO 콘솔(localhost:9001)의 'warehouse/factory_db/sensors/metadata/' 경로에 'v1.metadata.json' 스펙 파일 기록됨.") except TableAlreadyExistsError: # 이미 테이블이 존재하는 경우, 기존 테이블을 로드하여 스크립트가 중단되지 않도록 조치 table = catalog.load_table("factory_db.sensors") print("기존에 생성된 Iceberg 테이블 로드 완료!") except Exception as e: print(f"테이블 생성 중 오류 발생: {e}") raise # 5. 첫 번째 삽입할 데이터 준비 (Arrow Table 형태) data_v1 = pa.Table.from_pydict({ "sensor_id": ["SNS-001", "SNS-002"], "reading": [23.5, 42.1] }) # 6. 테이블에 데이터 추가 (Append) -> 중앙 REST Catalog를 통한 ACID 트랜잭션 커밋 try: table.append(data_v1) print("첫 번째 데이터 세트 업로드 및 트랜잭션 커밋 완료!") except Exception as e: print(f"데이터 업로드 중 오류 발생: {e}") """ - **저장소 확인 포인트:** - `data/` 폴더가 새로 생기며 그 밑에 실제 데이터가 담긴 `.parquet` 파일이 생성됨 - `metadata/` 폴더에는 `v2.metadata.json`과 함께 스냅샷 정보를 담은 `manifest_list` 및 `manifest` 파일(`.avro`)이 추가됨 - **이것이 바로 Iceberg가 스냅샷 단위로 파일을 추적하는 실체** """ # 7. [보완] 두 번째 데이터 준비 및 연속 추가 (스냅샷 전진 확인용) data_v2 = pa.Table.from_pydict({ "sensor_id": ["SNS-003"], "reading": [11.8] }) table.append(data_v2) print("두 번째 데이터 세트 업로드 및 트랜잭션 커밋 완료!") # 8. [보완] 현재 최신 스냅샷 상태 조회 (SNS-001, 002, 003 총 3개 행이 나옴) print("\n=== [현재 최신 데이터 상태] ===") print(table.scan().to_arrow()) # 9. [보완] 타임 트래블: 중앙 REST 카탈로그가 기억하는 이력을 추적하여 첫 번째 시점으로 조회 try: history = table.history() if len(history) > 0: first_snapshot_id = history[0].snapshot_id print(f"\n=== [타임 트래블: 첫 번째 스냅샷({first_snapshot_id}) 시점으로 조회] ===") print(table.scan(snapshot_id=first_snapshot_id).to_arrow()) else: print("\n스냅샷 이력이 존재하지 않습니다.") except Exception as e: print(f"타임 트래블 조회 중 오류 발생: {e}")
3.2 예제 2번 (내장 SQLite 사용)
- [참고]
- tabulario/iceberg-rest 이미지는 순수한 오픈소스 정신으로 만들어진 유틸리티가 아니라,
- 로컬 무료 스토리지(MinIO) 연동을 교묘하게 방해하여 자사의 상용 인프라나 공식 AWS S3로 넘어가도록 강제 유도하는 꼼수가 박혀 있는
- 상업적 개체임이 커뮤니티의 수많은 좌절 섞인 이슈들을 통해 확인됨
docker-compose.yml를 수정하여version: '3.8' services: # 1. 실제 파일들이 저장될 오브젝트 스토리지 (latest 버전으로 수정) minio: image: minio/minio:latest container_name: minio ports: - "9000:9000" # API 포트 - "9001:9001" # 웹 관리 콘솔 포트 environment: - MINIO_ROOT_USER=admin - MINIO_ROOT_PASSWORD=password command: server /data --console-address ":9001" # 2. MinIO 기동 시 'warehouse' 버킷을 자동으로 생성해주는 유틸리티 (latest 버전으로 수정) mc: image: minio/mc:latest depends_on: - minio entrypoint: > /bin/sh -c " until (/usr/bin/mc alias set myminio http://minio:9000 admin password); do echo 'Waiting for MinIO...'; sleep 1; done; /usr/bin/mc mb myminio/warehouse; exit 0;"필요한 라이브러리 패키지 설치
pip install "pyiceberg[sql-sqlite]" pip install "pyiceberg[pyarrow]" boto3파이썬 예제
from pyiceberg.catalog import load_catalog from pyiceberg.exceptions import NamespaceAlreadyExistsError, TableAlreadyExistsError import pyarrow as pa # 1. [상대경로 정정] 자바 REST 서버 없이 파이썬 네이티브 환경에서 로컬 상대경로로 연동 설정 # (슬래시 3개 'sqlite:///' 규칙을 사용하여 스크립트를 실행하는 현재 폴더 밑에 원장을 생성합니다) catalog = load_catalog( "default", **{ "type": "sql", "uri": "sqlite:///iceberg_catalog.db", "warehouse": "s3://warehouse", "s3.endpoint": "http://localhost:9000", "s3.path-style-access": "true", "s3.access-key-id": "admin", "s3.secret-access-key": "password", "py-io-impl": "pyiceberg.io.pyarrow.PyArrowFileIO" } ) # 2. 네임스페이스(RDBMS의 Database 개념) 생성 및 예외 처리 try: catalog.create_namespace("factory_db") print("네임스페이스(factory_db) 생성 완료!") except NamespaceAlreadyExistsError: print("네임스페이스가 이미 존재하여 다음 단계로 진행합니다.") except Exception as e: print(f"네임스페이스 생성 중 예상치 못한 오류 발생: {e}") # 3. PyArrow를 이용해 테이블 구조(Schema) 정의 schema = pa.schema([ ("sensor_id", pa.string()), ("reading", pa.float64()), ]) # 4. Iceberg 테이블 생성 및 멱등성 보장 try: table = catalog.create_table("factory_db.sensors", schema=schema) print("Iceberg 테이블(factory_db.sensors) 신규 생성 완료!") print(" └ [저장소 확인 포인트] MinIO 콘솔(localhost:9001)의 'warehouse/factory_db/sensors/metadata/' 경로에 'v1.metadata.json' 스펙 파일 기록됨.") except TableAlreadyExistsError: # 이미 테이블이 존재하는 경우, 기존 테이블을 로드하여 스크립트가 중단되지 않도록 조치 table = catalog.load_table("factory_db.sensors") print("기존에 생성된 Iceberg 테이블 로드 완료!") except Exception as e: print(f"테이블 생성 중 오류 발생: {e}") raise # 5. 첫 번째 삽입할 데이터 준비 (Arrow Table 형태) data_v1 = pa.Table.from_pydict({ "sensor_id": ["SNS-001", "SNS-002"], "reading": [23.5, 42.1] }) # 6. 테이블에 데이터 추가 (Append) -> 중앙 REST Catalog를 통한 ACID 트랜잭션 커밋 try: table.append(data_v1) print("첫 번째 데이터 세트 업로드 및 트랜잭션 커밋 완료!") except Exception as e: print(f"데이터 업로드 중 오류 발생: {e}") """ - **저장소 확인 포인트:** - `data/` 폴더가 새로 생기며 그 밑에 실제 데이터가 담긴 `.parquet` 파일이 생성됨 - `metadata/` 폴더에는 `v2.metadata.json`과 함께 스냅샷 정보를 담은 `manifest_list` 및 `manifest` 파일(`.avro`)이 추가됨 - **이것이 바로 Iceberg가 스냅샷 단위로 파일을 추적하는 실체** """ # 7. [보완] 두 번째 데이터 준비 및 연속 추가 (스냅샷 전진 확인용) data_v2 = pa.Table.from_pydict({ "sensor_id": ["SNS-003"], "reading": [11.8] }) table.append(data_v2) print("두 번째 데이터 세트 업로드 및 트랜깝 커밋 완료!") # 8. [보완] 현재 최신 스냅샷 상태 조회 (SNS-001, 002, 003 총 3개 행이 나옴) print("\n=== [현재 최신 데이터 상태] ===") print(table.scan().to_arrow()) # 9. [보완] 타임 트래블: 중앙 REST 카탈로그가 기억하는 이력을 추적하여 첫 번째 시점으로 조회 try: history = table.history() if len(history) > 0: first_snapshot_id = history[0].snapshot_id print(f"\n=== [타임 트래블: 첫 번째 스냅샷({first_snapshot_id}) 시점으로 조회] ===") print(table.scan(snapshot_id=first_snapshot_id).to_arrow()) else: print("\n스냅샷 이력이 존재하지 않습니다.") except Exception as e: print(f"타임 트래블 조회 중 오류 발생: {e}")- 이 구조는 단순한 로컬 파일 저장이 아니라
- 현재 클라우드 데이터 엔지니어링 시장의 절대적 표준인 “AWS S3 + Apache Iceberg” 아키텍처시뮬레이션하기 위한 설계
SQLite와 MinIO가 조합되었을 때 완성되는 공학적 의미와 가치
- 역할의 완벽한 분리: 메타데이터 원장(SQLite) vs 실제 데이터 영토(MinIO)
- 모던 데이터 레이크하우스(Lakehouse)의 핵심은
- 컴퓨트(Compute)와 스토리지(Storage)의 분리
- 메타데이터 레이어의 독립
- SQLite가 하는 일 (논리적 카탈로그):
- “지금
factory_db.sensors라는 테이블이 있고, - 이 테이블의 스키마는 무엇이며,
- 현재 최신 스냅샷 버전의 메타데이터 파일 주소는
s3://warehouse/metadata/v1.metadata.json이다” - 라는 ‘이정표(Pointer)’만 가볍게 관리
- “지금
- MinIO가 하는 일 (물리적 오브젝트 스토리지):
- SQLite가 가리키는 그 주소에서
- 실제로 거대한 Parquet 데이터 파일들과 이력을
- 물리적으로 저장하고 S3 API 인터페이스를 제공하는 ‘영토’ 역할
- 만약 MinIO를 쓰지 않고 로컬 파일 시스템(
file:///home/...)에 직접 Parquet을 굽는다면,- 그것은 그냥 흔한 로컬 파이썬 스크립트일 뿐
- 클라우드 기반의 분산 데이터 레이크 아키텍처를 대변할 수 없음
- 모던 데이터 레이크하우스(Lakehouse)의 핵심은
- ‘AWS S3 환경’의 완전한 로컬 에뮬레이션
데이터 엔지니어링, 스마트팩토리 AI 기술의 최종 종착지는 결국 AWS, Azure, GCP 같은 글로벌 클라우드 인프라
- MinIO의 가치:
- MinIO는 AWS S3 API 표준 규격과 100% 호환
- 코드의 재사용성(Portability):
- 파이썬 코드(
pyiceberg)의 설정에서"s3.endpoint": "http://minio:9000"줄만 지우거나 실제 AWS S3 주소로 바꾸면, - 단 한 줄의 코드 수정 없이 그대로 AWS 엔터프라이즈 환경에서 100% 똑같이 동작
- 파이썬 코드(
- 즉, SQLite를 쓰더라도 백엔드 스토리지로 MinIO를 물려놓아야만
- S3 프로토콜을 이용한 대용량 파일 IO 객체 처리,
- 경로 스타일(Path-style) 접근 규격 테스트 등
- 상용 클라우드에서 일어나는 파일 핸들링 메커니즘을 로컬에서 비용 없이 무결하게 검증할 수 있음
- 현업에서의 실제 하이브리드 아키텍처 반영
- “로컬 DB인 SQLite를 카탈로그로 쓰는 게 실무적인 조합인가?”
- 이는 실제 현업에서 강력하게 쓰이는 서버리스/임베디드 데이터 플랫폼(Embedded Data Stack)의 정석 구조
- 예시
- 최근 현업에서 각광받는 가벼운 분석 엔진인 DuckDB나 파이썬의 PyIceberg를 사용할 때,
- 굳이 무거운 Hive Metastore나 AWS Glue 같은 유료 카탈로그 서버를 띄우지 않음
- 메타데이터 원장은
- 애플리케이션 내장형 SQL(SQLite)이나 로컬 메타데이터 파일로 가볍게 처리
- 실제 수십 TB~PB의 대용량 Parquet 파일 데이터는
- 비용이 저렴하고 무한히 확장되는 중앙 오브젝트 스토리지(S3 또는 온프레미스 MinIO 클러스터)에 적재하는 하이브리드 설계를 빈번하게 채택
- 최근 현업에서 각광받는 가벼운 분석 엔진인 DuckDB나 파이썬의 PyIceberg를 사용할 때,
- “로컬 DB인 SQLite를 카탈로그로 쓰는 게 실무적인 조합인가?”
- 역할의 완벽한 분리: 메타데이터 원장(SQLite) vs 실제 데이터 영토(MinIO)
- SQLite는 ‘자바 REST 카탈로그 서버의 버그와 상용 꼼수’를 피하기 위한 현명한 메타데이터 대체재일 뿐
- MinIO는 이 프로젝트가 ‘AWS S3 기반의 거대한 데이터 레이크하우스 파이프라인’임을 증명하는 핵심 물리 인프라
3.3 예제 비교
docker-compose.yml설정의 전환(1번 🡲 2번)이 가지는 의의- 단순히 “에러가 나서 설정을 바꿨다”를 넘어,
- ‘컴포넌트 중심의 마이크로서비스 아키텍처(MSA)’에서 ‘어플리케이션 내장형 서버리스 아키텍처’로의 전환을 의미
- 한눈에 보는 핵심 차이점 비교
- 두 파일은 데이터 레이크하우스 인프라를 구성하는 컴포넌트의 범위, 네트워크 격리 수준, 그리고 메타데이터의 관리 주체에서 극명한 차이를 보임
비교 항목 1번 파일 (중앙 집중형 REST) 2번 파일 (내장형 SQL/SQLite) 컨테이너 개수 3개 (`rest-catalog`, `minio`, `mc`) 1개 (`minio`) 네트워크 모드 Docker 기본 브릿지 (가상 서브넷 분리) network_mode: "host" (호스트망 공유) 카탈로그 백엔드 Java 기반 독립 REST 서버 엔진 파이썬 애플리케이션 내장형 SQLite 스토리지 연결 가상 DNS 명칭 기반 (`http://minio:9000`) 로컬 루프백 기반 (`http://localhost:9000`) 버킷 생성 주체 도커 컨테이너 유틸리티 (`minio/mc`) 파이썬 `boto3` 라이브러리 코드 - 1번에서 2번으로 바꾸며 ‘잃어버린 것’ (Trade-Off 분석)
인프라가 가벼워진 대신, 엔터프라이즈 환경에서 분산 아키텍처가 제공하는 몇 가지 핵심 가치를 포기함
- 이기종(Multi-Language/Platform) 간의 메타데이터 공유 능력
- 잃은 것: 1번 파일은
- 표준 HTTP 규격을 제공하는 REST 카탈로그
- Python 스크립트뿐만 아니라 자바(Java), 스파크(Spark), 트린코(Trino), 플링크(Flink) 등
- 사내의 모든 다양한 데이터 플랫폼이 동시에 동일한 카탈로그 서버의 스냅샷을 공유할 수 있음
- 현재 상태:
- 메타데이터가 파이썬이 실행되는 로컬 PC의
iceberg_catalog.db(SQLite)라는 파일에 갇히게 됨- 외부의 다른 데이터 분석가나 다른 분산 엔진이 이 MinIO에 접근하더라도 최신 Iceberg 테이블 스냅샷 위치를 알 수 없음
- 즉 ‘단일 독립형(Standalone)’ 파이프라인으로 고립됨
- 메타데이터가 파이썬이 실행되는 로컬 PC의
- 잃은 것: 1번 파일은
- 도커 가상 네트워크의 보안 격리성 (Network Isolation)
- 잃은 것: 1번 파일은
- 포트 포워딩(
ports: - "9000:9000")을 통해 필요한 경로만 호스트 PC로 열어두고, - 내부 통신은 도커 가상 브릿지 뒤에 꽁꽁 숨겨두는 안전한 구조
- 포트 포워딩(
- 현재 상태:
network_mode: "host"를 사용함으로써 컨테이너의 네트워크 장벽이 허물어짐- 컨테이너가 호스트 PC의 IP와 네트워크 카드 인터페이스를 그대로 점유
- 포트 충돌 위험이 커짐
- 보안상 컨테이너 간의 네트워크 격리가 무너짐
- 잃은 것: 1번 파일은
- 인프라 오케스트레이션의 자급자족성 (Self-Containment)
- 잃은 것: 1번 파일은
mc유틸리티 컨테이너를 포함docker compose up명령어 한 줄이면 스토리지 구동부터 초기 버킷(warehouse) 생성까지 인프라 내부에서 완벽하게 끝마치고 대기하는 ‘올인원 패키지’
- 현재 상태:
- 버킷 생성 의존성을 파이썬 어플리케이션 코드(
boto3.client(...))로 떠넘김 - 즉, 인프라 스스로 온전한 상태를 완성하지 못하고 클라이언트 코드에 의존하게 됨
- 버킷 생성 의존성을 파이썬 어플리케이션 코드(
- 잃은 것: 1번 파일은
- 이기종(Multi-Language/Platform) 간의 메타데이터 공유 능력
- 아키텍처 전환이 가지는 공학적 의의
- 잃어버린 것들이 있음에도 불구하고, 2번 파일로의 전환은
데이터 엔지니어링 실습 및 데이터 파이프라인 PoC(개념 증명) 단계에서 엄청난 공학적 이점과 의의를 가짐
- 불필요한 ‘네트워크 아키텍처 오버헤드’의 제거
- 리눅스/우분투 환경에서 Docker 데몬 설정이나 네임서버(
resolv.conf), 자바 런타임의 DNS 캐시 고정 정책이 복잡하게 얽히면- 자바 기반 SDK는 가상 호스트명을 해석하지 못하고
UnknownHostException을 던짐
- 자바 기반 SDK는 가상 호스트명을 해석하지 못하고
- 2번 아키텍처는 가상 네트워크 레이어를 과감히 걷어내고
localhost대역으로 통신을 단순화하여- 인프라 종속성으로 인한 불필요한 트러블슈팅 스트레스를 원천 차단
- 리눅스/우분투 환경에서 Docker 데몬 설정이나 네임서버(
- 클라이언트 주도적 ‘뚱뚱한 아키텍처(Thick Client)’의 효율성 증명
- 전통적인 대규모 엔터프라이즈 환경에서는
- 서버가 무겁고 똑똑해야 함
- AI 연구나 가벼운 스마트팩토리 에이전트 개발, 데이터 엔지니어링 교육 환경에서는
- 파이썬(PyIceberg/SQLAlchemy)이 직접 메타데이터를 통제하는 아키텍처가 인프라 비용과 관리 비용 측면에서 압도적으로 유리함
- 전통적인 대규모 엔터프라이즈 환경에서는
- 이번 트러블슈팅의 가치
- “표준 마이크로서비스(REST) 방식이 가지는 네트워크 파싱 규칙의 한계
- 이를 우회하기 위해 로컬 백엔드(SQLite)를 내장하여 오브젝트 스토리지(MinIO)와 직접 결합하는 서버리스 데이터 레이크하우스 디자인 패턴
- 을 구조적으로 비교 분석해 볼 수 있는 실전 아키텍처 비교
- 1번 파일은
- 다양한 분산 컴퓨팅 엔진들이 메타데이터를 공유해야 하는 ‘실제 프로덕션 분산 운영 환경’을 지향하는 아키텍처
- 2번 파일은
- 복잡한 자바 컨테이너 인프라의 버그를 배제하고,
- 파이썬 어플리케이션의 성능과 Iceberg 본연의 기능(ACID 트랜잭션, 타임 트래블)에만 순수하게 집중할 수 있도록 경량화된
- ‘에이전트 및 고효율 분석 최적화 환경’을 지향하는 아키텍처
- 우분투 환경과 파이썬 실습 목적에는 2번 파일 기반의 임베디드 아키텍처가 훨씬 더 통제하기 쉽고 탄탄한 구조임
- 현업에서의 프로덕트 환경에서는 어떤 방식이 요구될 것인지 판단에 의해 다방면의 대응이 필요함
예제 코드 관점에서의 비교
두 개의 파이썬 실습 예제 코드는 앞서 분석한
docker-compose.yml아키텍처의 사상이 그대로 투영되어 있음- 1번 코드: “엔터프라이즈형 표준 분산 아키텍처” 지향
- 2번 코드: “어플리케이션 내장형 서버리스 아키텍처” 지향
- 1번 예제 코드 (REST 카탈로그 기반) 분석
- 장점
- 순수한 비즈니스 로직 집중:
- 코드가 매우 간결함
- 인프라적인 사전 준비(버킷 생성 등)나 예외 처리가 코드에 섞이지 않음
- “Iceberg가 데이터를 어떻게 다루는가”라는 순수 기능에만 집중
- 프로덕션 환경과의 100% 동일성:
- 현업의 실제 대규모 인프라(AWS, 클라우드 환경)에 배포할 때
- 포트와 URI 주소만 바꾸면 스크립트를 단 한 줄도 수정하지 않고 그대로 재사용할 수 있음
- 현업의 실제 대규모 인프라(AWS, 클라우드 환경)에 배포할 때
- 역할의 명확한 분리:
- 테이블 생성 시 중복 에러 처리가 없음
- 인프라와 데이터의 생명주기를 완벽히 분리하여 관리하는 정석적인 데이터 엔지니어링 패턴을 따르고 있음을 의미
- 테이블 생성 시 중복 에러 처리가 없음
- 순수한 비즈니스 로직 집중:
- 단점
- 멱등성(Idempotency)의 부재:
- 스크립트를 두 번째 실행하는 순간,
create_namespace와create_table에서 “이미 존재한다”는 예외를 뱉으며 무조건 뻗어버림 - 매번 실행 전 도커를 완전히 밀어주어야 하는 번거로움이 있음
- 스크립트를 두 번째 실행하는 순간,
- 외부 인프라 의존성 취약:
- Docker의 REST 카탈로그 서버가 완벽하게 준비되지 않았거나,
- 내부 자바 SDK의 엔드포인트 파싱 에러가 나면
- 파이썬 코드는 아무 잘못이 없음에도 아예 구동조차 되지 않음
- 멱등성(Idempotency)의 부재:
- 장점
- 2번 예제 코드 (Local SQL/SQLite 카탈로그 기반) 분석
- 장점
- 완벽한 애플리케이션 독립성과 복탄성(Resilience):
boto3를 이용해 스토리지(MinIO)에 버킷이 없으면 코드가 직접 만들고,- 네임스페이스와 테이블이 이미 존재하면
try-except로 부드럽게 로드(load_table)하여 우회 - 몇 번을 다시 실행해도 에러 없이 똑같은 결과가 보장되는 ‘멱등성’을 가짐
- 인프라 디버깅 스트레스 전무:
- 카탈로그 서버 엔진을 파이썬 내부로 끌고 들어와 로컬 SQLite 파일(
iceberg_catalog.db)로 처리 - 도커 컨테이너 간의 네트워크 꼬임이나 자바 SDK 버그로부터 완전히 해방됨
- 카탈로그 서버 엔진을 파이썬 내부로 끌고 들어와 로컬 SQLite 파일(
- 완전한 시나리오 검증 가능:
- 1번 예제에 없는 타임 트래블(
snapshot_id기반 조회) 및 다중 데이터 추가(data_v2) 로직이 내장됨 - 코드 한 장으로 Iceberg의 핵심 가치를 모두 테스트할 수 있음
- 1번 예제에 없는 타임 트래블(
- 완벽한 애플리케이션 독립성과 복탄성(Resilience):
- 단점
- 코드의 비대화(코드 오버헤드):
- S3 클라이언트 생성, 예외 처리 블록(Try-Except) 등이 포함됨
- 순수 데이터 엔지니어링 로직 외에 인프라 방어 코드가 다수 포함됨
- 초심자에게는 코드가 다소 복잡해 보일 수 있음
- 공유 불가능한 로컬 메타데이터:
- 메타데이터 포인터가 로컬 SQLite 파일에 저장됨
- 다른 PC나 스파크(Spark) 등의 분산 엔진이 동일한 MinIO에 접속했을 때 이 테이블을 조회할 수 없음
- 코드의 비대화(코드 오버헤드):
- 장점
- 두 코드가 가진 본질적인 구조적/개념적 차이와 한계
- 구조적 차이: Decoupled vs Embedded Architecture
“데이터 관리 시스템의 구성 요소를 어떻게 배치할 것인가?”에 대한 철학이 정반대
- 1번 예제
- 철저하게 분리된 3-Tier 아키텍처 (Decoupled)
- 클라이언트(Python)가 데이터의 실체나 저장소 규칙을 직접 알지 못함
- 오직 중간에 있는 REST 카탈로그 서버라는 단일 창구(API Gateway)와만 대화함
- 구조적 메커니즘:
- Python 🡲 REST API 🡲 Metadata Engine 🡲 Storage
- 개념적 의의:
- 클라이언트와 저장소(MinIO)가 철저하게 격리(Decoupled)되어 있음
- 나중에 저장소가 MinIO에서 AWS S3나 Google Cloud Storage로 바뀌더라도,
- 파이썬 코드는 이를 알 필요가 없고 오직 카탈로그 서버 설정만 바꾸면 됨
- 철저하게 분리된 3-Tier 아키텍처 (Decoupled)
- 2번 예제
- 클라이언트가 통제권을 쥔 뚱뚱한 클라이언트 아키텍처 (Embedded)
- 중간 계층을 없애고, 카탈로그 엔진을 파이썬 프로세스 메모리 내부로 내장(Embedded)시킴
- 구조적 메커니즘:
- [Python + Local Engine] 🡲 Storage (Direct)
- 개념적 의의:
- 파이썬 어플리케이션 자체가 하나의 ‘데이터베이스 엔진’처럼 작동함
- 중간에 통신 오버헤드나 타인과의 중재자가 없기 때문에 단일 프로세스 관점에서는 속도가 가장 빠르고 단순함
- 반면, 인프라의 모든 통제권과 책임을 클라이언트가 직접 짊어짐
- 클라이언트가 통제권을 쥔 뚱뚱한 클라이언트 아키텍처 (Embedded)
- 개념적 한계: 잃어버린 ‘진정한 의미의 데이터 레이크하우스’ 사양
기술적으로 가장 치명적으로 잃어버린 개념적 가치는 ‘단일 진실 공급원(Single Source of Truth)’의 붕괴
- 메타데이터 파편화 (Split-Brain) 현상
- Apache Iceberg의 본질은 “오브젝트 스토리지 위에 RDBMS 같은 테이블을 구현하는 것”
RDBMS는 누구나 중앙 DB 서버에 접속해야 최신 데이터를 볼 수 있음
- 1번 예제 (REST):
- 모든 사용자가 하나의 REST 서버를 바라보므로, A가 데이터를 넣으면 B도 즉시 그 스냅샷을 인지함
- 2번 예제 (SQLite):
- 메타데이터 포인터가 PC 내부의 SQLite(
iceberg_catalog.db)에만 저장됨 - 실제 데이터 파일(.parquet)은 MinIO에 정상적으로 올라갔더라도
- 다른 컴퓨터에 있는 분석가가 그 MinIO를 접근해도 추가된 데이터를 절대 읽을 수 없음
- 메타데이터가 파편화되어 데이터 레이크하우스의 통합 관리 개념이 완전히 상실됨
- 메타데이터 포인터가 PC 내부의 SQLite(
- 분산 락(Distributed Lock)과 동시성 제어(Concurrency Control)의 한계
- 데이터 레이크하우스는 수많은 센서와 파이프라인이 동시에 데이터를 밀어 넣음
이때 데이터가 꼬이지 않도록 하는 핵심이 낙관적 동시성 제어(OCC)
- 1번 예제 (REST):
- 중앙 카탈로그 서버가 자바 엔진 레벨에서 “지금 A가 커밋 중이니 B는 잠시 대기해”라며 중앙 집중식 트랜잭션 락을 제어해 줌
- 2번 예제 (SQLite):
- 각자 자기 PC의 SQLite 파일만 보고 있음
- 여러 클라이언트가 동시에 MinIO에 데이터를 쓰면 서로 충돌을 감지하지 못함
- 스냅샷 파일이 덮어씌워지거나 데이터가 유실되는 정합성 붕괴가 일어남
- 구조적 차이: Decoupled vs Embedded Architecture
- MinIO-Iceberg 연동 실습을 위한 최종 평가 및 추천
- “학습 및 강의, PoC(개념 증명) 목적의 연동 실습” 환경에서는 단연 2번 예제 코드가 압도적으로 적합
평가 항목 1번 예제 (REST) 2번 예제 (SQLite) 비교 우위 실습 진행의 매끄러움 X (인프라 버그 잦음) ○ (버그 없이 즉시 실행) 2번 압승: 인프라 꼬임으로 진도가 막히는 것을 완벽히 방지 Iceberg 핵심 기능 검증 △ (단발성 등록) ○ (타임트래블까지 완비) 2번 승: 눈으로 직접 타임 트래블 결과를 확인 아키텍처 성숙도 ○ (엔터프라이즈 정석) △ (단일 독립형 구조) 1번 승: 프로덕션 아키텍처 가이드를 줄 때는 1번 개념이 정석
- 실습 목적에 따른 최종 평가
구조적/개념적 분석을 바탕으로 “MinIO-Iceberg 연동 실습”이라는 목적에 대입해 보면…
- Iceberg의 ‘개념과 아키텍처’를 배우는 실습 🡲 1번 코드
- 현대 데이터 플랫폼의 정석인 “중앙 카탈로그를 통한 메타데이터 통합 관리 및 동시성 제어”라는 아키텍처적 본질을 배우기에는 🡲 1번이 적합
- 2번은 편의를 위해 데이터 레이크하우스의 핵심 철학(중앙 제어)을 타협한 구조
- 1번 코드는 “진짜 엔터프라이즈 데이터 레이크하우스의 분산 구조”를 정석대로 설계
- ‘MinIO 스토리지 자체와의 연동과 파이썬 조작’을 배우는 실습 🡲 2번 코드
- 분산 환경의 골치 아픈 개념을 배제하고,
- 순수하게 파이썬 코드가 어떻게 화살표를 날려 MinIO에 Parquet 파일을 굽고,
- Iceberg의 타임 트래블 메커니즘이 수식적으로 어떻게 돌아가는지 ‘기능적 현상’을 빠르게 확인하기에는 🡲 2번이 적합
- 2번 코드는 장벽을 허물기 위해 “단일 로컬 어플리케이션 구조”로 개념을 축소한 것