Trino 개요
1. Trino의 개념 및 개요
1.1 개요
- Trino(과거 PrestoSQL)
- 여러 데이터 소스에 분산 저장된 빅데이터를
- 데이터 이동(ETL) 없이, 표준 SQL을 사용하여 실시간으로 조회하고 분석할 수 있도록 설계된 분산 SQL 엔진
- 데이터가 어디에 있든 상관없이 처리 가능
- 스토리지 분리형 엔진 (Compute-only):
- 자체 스토리지 엔진을 보유하지 않음
- 데이터를 직접 저장하지 않고 오직 쿼리 ‘연산(Compute)’만 수행
- 데이터는 하둡(HDFS), AWS S3, MySQL, Kafka, NoSQL 등 원천 스토리지에서 직접 읽어옴(쿼리 실행)
- MPP(Massive Parallel Processing) 아키텍처:
- 여러 노드에서 작업을 병렬로 처리하여 수 테라바이트에서 페타바이트급 데이터를 빠르게 처리
- 하나의 쿼리를 여러 워커 노드(Worker Node)에 분산하여 병렬로 실행하는 방식으로, 페타바이트(PB) 단위의 초대형 데이터도 가볍게 처리
- 인메모리 파이프라인 처리:
- 디스크 I/O를 최소화하고 메모리 상에서 연산을 수행하여 지연 시간을 극적으로 줄임
- 중간 연산 결과를 디스크에 쓰지 않고 메모리상에서 파이프라인 형태로 다음 단계로 넘겨주기 때문에 쿼리 응답 속도가 매우 빠름
Trino Architecture
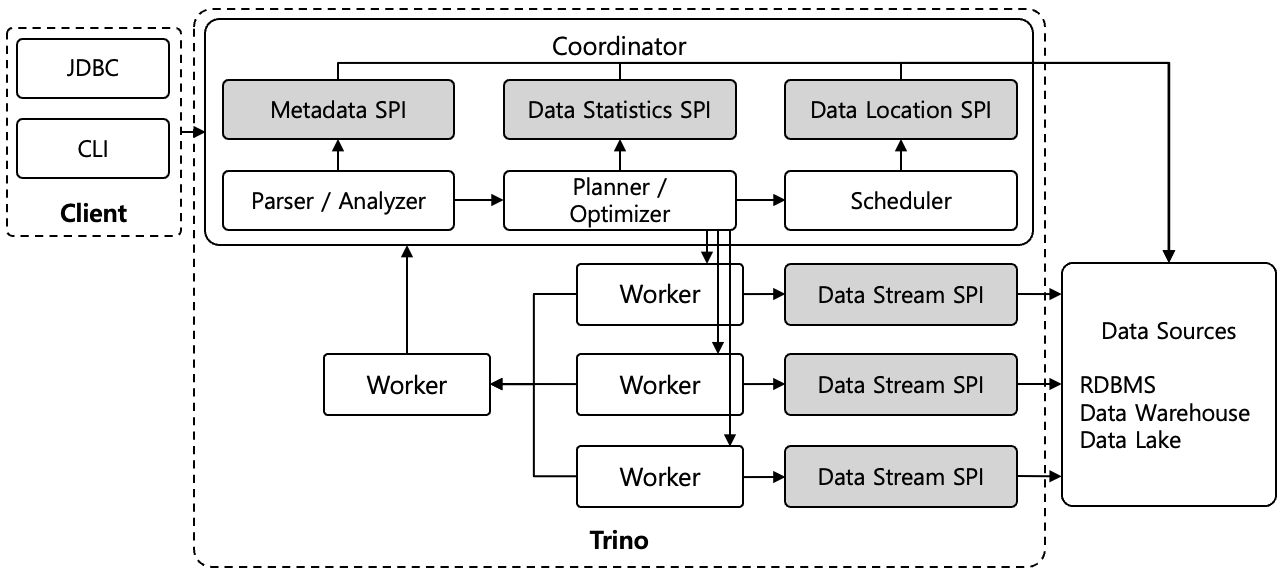
1.2 개발 역사와 명칭의 유래
Trino의 역사는 오픈소스 빅데이터 생태계에서 가장 유명한 소프트웨어 포크(Fork) 일화 중 하나
[2012] 페이스북에서 Presto 개발 시작 페이스북 내부에서 기존에 쓰던 Apache Hive의 느린 쿼리 속도(MapReduce 기반)를 해결하기 위해 🡲 대화형 분석용 엔진으로 Presto 개발 🡳 [2013] 오픈소스화 (PrestoDB) 🡳 [2019] 페이스북의 프로젝트 조직 통제 시도 🡲 원년 개발자 및 커뮤니티의 반발 🡲 창립자들(Martin, Dain, David)이 오픈소스 포크 진행 🡲 'PrestoSQL' 명명 🡳 [2020] 페이스북의 상표권 행사 🡲 'Trino' 로 프로젝트명 변경 🡲 비영리 단체 'Trino Software Foundation' 설립 현재 대다수의 오픈소스 기여자와 스타버스트(Starburst) 등 대형 벤더들이 Trino 생태계 주도
1.3 사용 목적과 의의
- 사용 목적
- 데이터 가상화 및 연합(Data Federation):
- 데이터 분석을 위해
- 서로 다른 저장소(RDBMS, NoSQL, Object Storage 등)에 있는 데이터를 한 곳으로 모으는 대규모 ETL 파이프라인을 구축할 필요 없이,
- SQL 질의문 하나로 서로 다른 스토리지를 조인(Join) 분석하기 위함
- 대화형 분석(Interactive/Ad-hoc Query):
- 데이터 사이언티스트나 분석가가 수초 내에 결과를 확인해야 하는 즉각적인 질의를 수행하기 위해 사용
- 직관적으로 데이터를 탐색할 수 있는 환경을 제공함
- 데이터 레이크 쿼리:
- S3나 HDFS 같은 거대한 데이터 저장소에서 필요한 데이터만 빠르게 추출하는 관문 역할 수행
- 데이터 가상화 및 연합(Data Federation):
- 기술적 의의
- 빅데이터 패러다임의 전환(Data Lakehouse 및 데이터 메시 구조의 핵심)을 이끌어 냄
- 분석을 하려면 데이터를 먼저 하둡이나 DW로 옮겨야 한다 (과거) 🡲 데이터가 어디에 있든 상관없이 쿼리 엔진이 찾아가서 연산한다 (Trino)
- 빅데이터 패러다임의 전환(Data Lakehouse 및 데이터 메시 구조의 핵심)을 이끌어 냄
1.4 장점과 단점
- 장점
- 압도적인 대화형 쿼리 속도: 하이브, 전통 하둡 쿼리 엔진 대비 수십 배 이상 빠름
- 순수 인메모리 파이프라인
- MPP(Massive Parallel Processing, 대규모 병렬 처리) 아키텍처
- 효율적인 비용 기반 옵티마이저(CBO) 적용
- 유연한 확장성: 다양한 커넥터(Connector) 지원
- 커넥터(Connector) 구조를 통해 관계형 DB, NoSQL, 객체 스토리지 등 수십 개의 데이터 소스 지원
- 단 한 번의 Trino 클러스터 접속으로 Hive, Iceberg, Delta Lake, MySQL, PostgreSQL, MongoDB, Elasticsearch, Kafka 등을 동시에 엮어 쿼리할 수 있음
- 커넥터(Connector) 구조를 통해 관계형 DB, NoSQL, 객체 스토리지 등 수십 개의 데이터 소스 지원
- 표준 SQL 준수: 높은 ANSI SQL 호환성
- ANSI SQL을 지원하므로 학습 곡선이 낮고 기존 쿼리를 재사용하기 좋음 🡲 분석가들의 진입 장벽이 낮음
- 복잡한 Window 함수, Join, 서브쿼리 등을 표준 SQL로 온전히 지원
- ANSI SQL을 지원하므로 학습 곡선이 낮고 기존 쿼리를 재사용하기 좋음 🡲 분석가들의 진입 장벽이 낮음
- 안정적인 태스크 수준 내결함성(Fault-Tolerant Execution):
- 과거 버전: 쿼리 실행 중 노드 하나만 죽어도 전체 쿼리 실패
- 최근 버전(Project Tariq 및 내결함성 아키텍처 도입):
- 대규모 배치 작업 시 태스크 단위 리트라이(Retry)가 가능해짐 🡲 대규모 배치 처리 안정성의 극적 향상
- 실시간성:
- ETL 과정 없이 데이터 소스에 직접 접근 🡲 가장 최신 데이터를 즉시 조회할 수 있음
- 압도적인 대화형 쿼리 속도: 하이브, 전통 하둡 쿼리 엔진 대비 수십 배 이상 빠름
- 단점
- 높은 메모리 의존도:
- 인메모리 아키텍처 특성상, 대규모 조인 연산 시 클러스터의 전체 메모리가 부족하면
Out of Memory (OOM)에러와 함께 쿼리가 실패하기 쉬움- 최근 Spilling 기능을 지원하나 성능 저하가 동반됨
- 인메모리 아키텍처 특성상, 대규모 조인 연산 시 클러스터의 전체 메모리가 부족하면
- 내결함성(Fault Tolerance) 부족:
- 기본적으로 쿼리 실행 중 한 노드만 장애가 나도 전체 쿼리를 처음부터 다시 실행해야 함
- 최근 ‘Project旁’ 등을 통해 개선되고 있으나 아직 부족함
- 기본적으로 쿼리 실행 중 한 노드만 장애가 나도 전체 쿼리를 처음부터 다시 실행해야 함
- 스토리지 관리 기능 부재:
- Trino 자체는 데이터를 저장하지 않음
- 트랜잭션 관리(ACID), 데이터 정합성 보장, 인덱싱 등은 원천 데이터 소스(e.g. Apache Iceberg, RDBMS)의 역량에 의존해야 함
- 복잡한 리소스 튜닝:
- 대규모 클러스터 운영 시 메모리 관리 및 리소스 튜닝이 까다로울 수 있음
- 동시 사용자가 많고 다양한 데이터 소스를 결합할 때, 메모리 분배 및 워커 할당 등 클러스터 최적화(Tuning) 난이도가 높음
- 대규모 클러스터 운영 시 메모리 관리 및 리소스 튜닝이 까다로울 수 있음
- 높은 메모리 의존도:
1.5 도구의 활용 방향 및 활용 사례
- 활용 방향 (Modern Data Architecture)
- 데이터 레이크하우스(Data Lakehouse)의 관문:
- S3, MinIO 등에 저장된 패러독스 포맷(Parquet, ORC) 데이터를 Apache Iceberg나 Delta Lake 오픈 테이블 포맷과 결합하여 DW 수준의 성능을 내는 레이크하우스 쿼리 엔진으로 활용
- 데이터 웨어하우스(DW) 보완:
- 기존 DW의 비용 부담을 줄이기 위해, 자주 쓰지 않는 대용량 데이터는 저렴한 스토리지에 두고 Trino로 조회하는 구조를 취함
- 데이터 메시(Data Mesh) 구현:
- 조직 내 각 부서가 관리하는 서로 다른 데이터베이스들을 하나의 가상 뷰(View) 형태로 묶어 전사 데이터 카탈로그처럼 활용할 수 있음
- BI 및 시각화 인프라:
- BI 툴 뒤단에서 복잡한 이기종 쿼리를 통합 흡수하여 대시보드에 고속으로 데이터를 피딩(Feeding)
- Tableau, Power BI, Superset 등과 연결하여 실시간 시각화 지표 생성
- BI 툴 뒤단에서 복잡한 이기종 쿼리를 통합 흡수하여 대시보드에 고속으로 데이터를 피딩(Feeding)
- 이기종 데이터 통합 분석:
- 예를 들어, 서비스 DB인 MySQL의 유저 정보와 S3 로그 데이터를 조인하여 사용자 행동 패턴을 분석함
- 데이터 레이크하우스(Data Lakehouse)의 관문:
- 대표적인 활용 사례
- Netflix:
- 수십 PB 가 넘는 S3 데이터 레이크 위의 데이터를 Trino를 통해 분석함
- 특히 Apache Iceberg 테이블 포맷의 메인 쿼리 엔진으로 Trino를 채택하여 대화형 분석의 표준으로 삼고 있음
- Uber & LinkedIn:
- 기존 하둡/하이브 기반의 느린 분석 환경을 Trino 클러스터 체제로 전환
- 수천 명의 데이터 분석가와 엔지니어가 실시간 대시보드 및 지표 분석을 안정적으로 수행하도록 지원
- 국내 이커머스 및 테크 기업 (배달의민족, 쿠팡, 당근 등):
- 다양한 마이크로서비스(MSA) 아키텍처 분산으로 인해 분산된 AWS RDS(MySQL/PostgreSQL) 데이터와 S3 로그 데이터를 단 한 번의 쿼리로 결합
- 마케팅 지표 분석 및 유저 행동 분석에 적극 활용
- Netflix:
1.6 비슷한 다른 도구와의 비교
- Trino는 주로 Apache Spark, PrestoDB(Meta 주도), ClickHouse/StarRocks 등과 비교됨
| 비교 항목 | Trino | Apache Spark (Spark SQL) | PrestoDB | ClickHouse / StarRocks |
|---|---|---|---|---|
| 주요 용도 | 대화형 분산 SQL 분석, 데이터 연합 | 대규모 배치 ETL, ML 머신러닝, 스트리밍 | 메타 인프라 종속형 대화형 분석 | 실시간 OLAP 대시보드, 시계열 분석 |
| 스토리지 포맷 | 없음 (외부 소스 연동) | 없음 (DataFrame/외부 소스 연동) | 없음 (외부 소스 연동) | 자체 고성능 칼럼너 스토리지 포함 |
| 데이터 연합 (Federation) | 숨겨진 파티셔닝 & 진화 지원 | 상 (코드로 연동 가능하나 무거움) | 중상 | 하 (자체 테이블 분석에 최적화) |
| 내결함성 (Fault Tolerance) | 중상 (태스크 단위 리트라이 추가) | 최상 (RDD 기반 자동 복구) | 중 (쿼리 수준 리트라이 위주) | 상 (복제본 기반) |
| 적합한 워크로드 | 데이터 레이크 조회, BI 대시보드 연계 | 무거운 배치 원천 데이터 가공 | Meta 에코시스템 중심의 인프라 | 초고속 실시간 대시보드, Concurrency 대응 |
- Trino vs Spark:
- Spark: 복잡한 데이터 변환(ETL)이나 머신러닝 파이프라인처럼 “한 번 돌면 절대 죽지 않고 돌아가야 하는 무거운 작업”에 적합
- Trino: “여러 저장소의 데이터를 빠르게 SQL로 묶어서 보고 싶을 때”, 즉 ad-hoc 조회에 훨씬 가볍고 빠름
- Trino vs ClickHouse:
- ClickHouse: 데이터를 ‘자체 저장’하여 가공해두고 고도의 동시성(High Concurrency) 조회를 처리
- Trino: 스토리지가 파편화되어 있는 환경에서 뛰어난 유연성을 보여줌
- Trino는
- 데이터 이동 없는 초고속 분석이 필요할 때 가장 강력한 도구
- 데이터 가상화 계층으로서 여러 파편화된 데이터들을 하나로 묶어주는 역할을 수행
- 대규모 데이터 환경에서 분산 SQL 쿼리 엔진의 표준, 현대적인 데이터 플랫폼(Modern Data Stack)의 핵심 구성 요소로 자리 잡고 있음