Spark 개요와 분산 데이터 처리
1. 분산 데이터 처리의 이해
- 분산 데이터 처리
- 하나의 거대한 데이터를 단일 컴퓨터(서버)가 아닌,
- 네트워크로 연결된 여러 대의 컴퓨터(클러스터, Cluster)에 분산하여 저장하고 병렬로 연산하는 방식
1.1 등장 배경: Scale-up vs Scale-out
- 과거의 경우
- 데이터량이 늘어나면 서버의 CPU, RAM, 디스크를 더 좋은 것으로 교체하는 Scale-up(수직 확장) 방식 사용
- 한계점
- 하드웨어적 한계:
- 고성능 부품일수록 가격이 기하급수적으로 상승함
- 단일 보드에 장착할 수 있는 부품의 한계가 존재함
- 단일 장애점(SPOF):
- 고가의 서버 한 대가 고장 나면 전체 시스템이 마비됨
- 하드웨어적 한계:
- 해결 방안
- 값싼 범용 컴퓨터(Commodity Hardware) 여러 대를 묶어 하나의 컴퓨터처럼 사용하는 Scale-out(수평 확장) 체계 도입
- 이것이 분산 데이터 처리의 시초가 됨
1.2 분산 데이터 처리의 개념
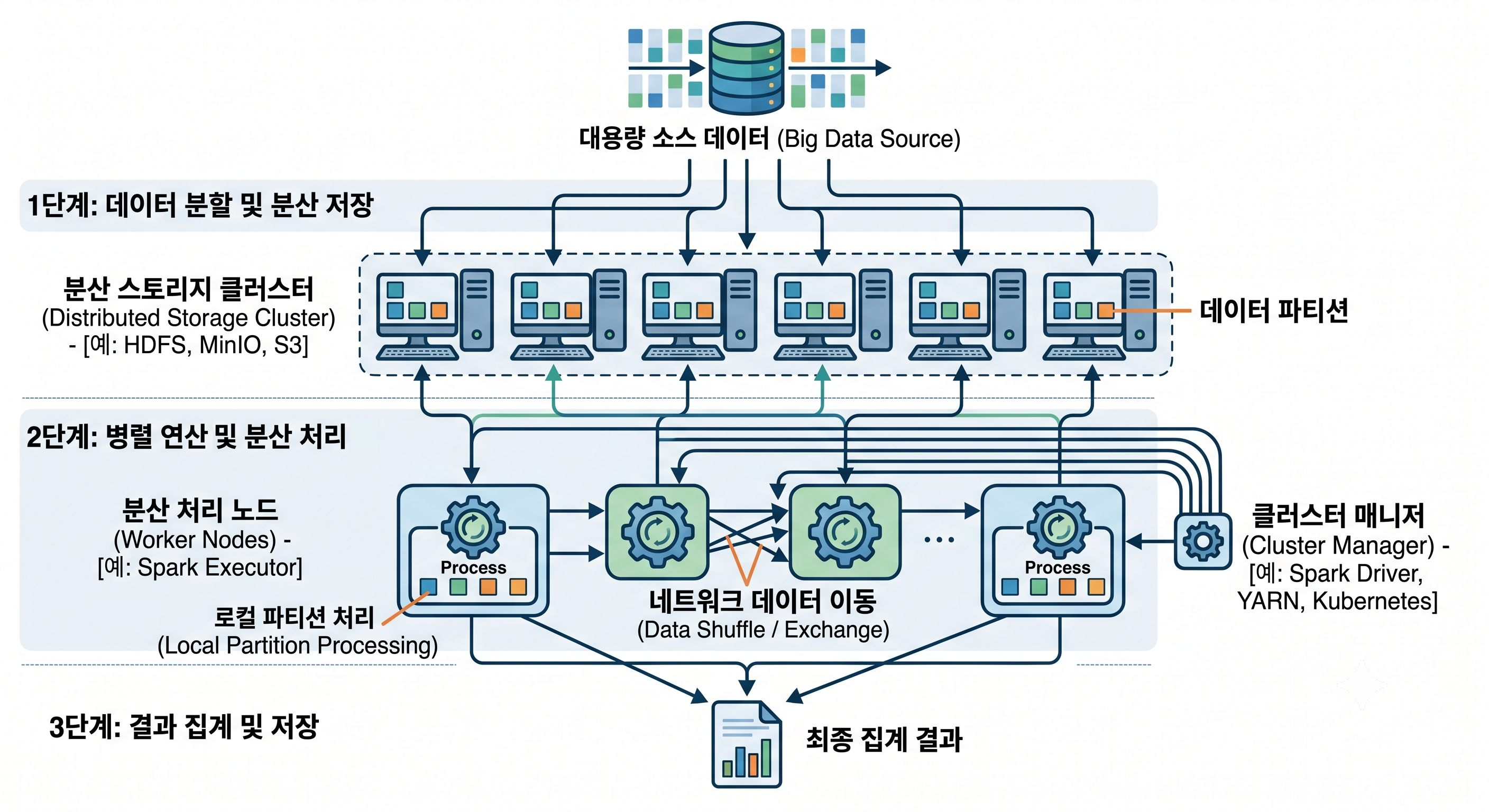
- 1단계: 데이터 분할 및 분산 저장 (Data Partitioning & Distributed Storage)
- 거대한 하나의 파일을 시스템이 처리할 수 있도록 작게 쪼개어 여러 컴퓨터에 나누어 저장하는 과정
원본 데이터를 파티션 단위로 나누고, 분산 스토리지 클러스터 내의 여러 노드에 분산하여 저장함으로써 저장 공간의 한계를 극복하고 데이터 로딩 속도를 병렬화 함
- 대용량 소스 데이터 (Big Data Source):
- 시스템으로 유입되는 원본 데이터
- 단일 서버의 하드웨어(디스크, RAM)로는 처리할 수 없을 만큼 크기가 큼
- 그림에서는 거대한 데이터베이스 아이콘으로 표현되며, 여러 가닥의 데이터 스트림으로 분리되기 시작함
- 데이터 파티션 (Data Partitions):
- 소스 데이터를 관리하고 연산할 수 있는 기본 단위(블록)로 나눈 것
- 각 컴퓨터 노드(서버)에는 전체 데이터의 일부인 이 파티션들이 저장됨
- 파티션의 크기를 어떻게 잡느냐(예: 128MB)가 전체 성능에 큰 영향을 미침
- 분산 스토리지 클러스터 (Distributed Storage Cluster):
- 여러 대의 범용 컴퓨터(서버)가 네트워크로 연결되어 하나의 거대한 저장 공간처럼 동작하는 아키텍처
- [예: HDFS, MinIO, S3] 같은 오픈 소스 또는 클라우드 스토리지 솔루션이 이 역할을 수행함
- 그림에서는 6대의 서버 노드가 하나의 점선 뭉치로 묶여 하나의 클러스터를 구성하고 있음
- 2단계: 병렬 연산 및 분산 처리 (Parallel Computation & Distributed Processing)
- 저장된 데이터를 기반으로 실제로 연산을 수행하는 핵심 단계
- 스파크(Spark)와 같은 분산 처리 엔진이 주도함
- 클러스터 매니저의 지휘 아래, 각 처리 노드는 자신이 가진 데이터를 우선 처리하며,
필요한 경우 셔플 과정을 통해 네트워크로 데이터를 교환하여 복잡한 연산을 수행함
- 클러스터 매니저 (Cluster Manager):
- 분산 환경의 ‘지휘자’
- 각 노드의 자원(CPU, RAM) 상태를 파악하고, 작업을 어느 노드에 배분할지 결정
- [예: Spark Driver, YARN, Kubernetes]가 이 역할을 수행함
- 그림에서 오른쪽에 독립적으로 존재하며, 모든 처리 노드와 제어 신호를 주고받는 모습으로 표현됨
- 분산 처리 노드 (Worker Nodes):
- 실제로 연산을 수행하는 ‘일꾼’
- [예: Spark Executor]가 각 노드에서 실행되며,
- 로컬 파티션에 대한 계산을 수행함
- 로컬 파티션 처리 (Local Partition Processing):
- 데이터 지역성(Data Locality) 원리에 따라, 각 노드는 자신이 저장하고 있는 데이터 파티션을 우선적으로 처리함
- 그림에서는 각 작업 노드 내의 ‘Process’ 톱니바퀴 아이콘이 로컬 데이터 블록을 처리하는 모습을 표현
- 네트워크 데이터 이동 (Data Shuffle / Exchange):
- 분산 처리에서 가장 중요한 개념이자 병목 구간
- 서로 다른 파티션에 흩어져 있는 데이터를 특정 기준(예:
GroupBy의 키 값)으로 모아야 할 때, 네트워크를 통해 노드 간 데이터를 주고받음 - 그림에서는 중앙의 3대 서버가 수많은 교차 화살표를 주고받는 모습 이 ‘셔플’ 과정을 명확히 보여줌
- 셔플을 최소화하는 것이 성능 튜닝의 핵심
- 3단계: 결과 집계 및 저장 (Result Aggregation & Storage)
- 분산되어 처리된 개별 연산 결과를 하나로 합치고, 최종 결과를 영구 저장하는 단계
- 2단계의 병렬 연산이 끝나면,
- 각 노드의 부분 결과를 최종적으로 집계하고,
- 이 결과를 다시 파일 시스템에 저장하거나 사용자에게 반환하여 전체 처리를 마무리함
- 결과 집계:
- 모든 처리 노드의 로컬 연산이 완료되면, 최종적으로 결과를 취합
- 예: Count, Sum, 최상위 10개 결과 등
- 그림에서 각 처리 노드에서 나온 결과 화살표가 하나의 문서 아이콘으로 모이는 모습으로 표현
- 모든 처리 노드의 로컬 연산이 완료되면, 최종적으로 결과를 취합
- 최종 집계 결과:
- 사용자가 요청한 최종 출력 데이터
- 그림에서는 차트와 문서를 포함한 하나의 ‘완성된 보고서’ 아이콘으로 표현
- 전체 흐름의 핵심
- 이 다이어그램은 분산 처리의 3가지 핵심 성공 요소를 보여줌
- 확장성 (Scalability):
- 1단계의 분산 저장과 2단계의 병렬 처리는
- 노드(컴퓨터) 수를 늘리면 성능도 그에 비례해 늘어나는 구조를 가짐
- 데이터 지역성 (Data Locality):
- 2단계에서 각 노드가 자기 데이터를 처리하는 구조는 네트워크 사용을 최소화하여 성능을 극대화하는 핵심 원리
- 결함 허용 (Fault Tolerance):
- 1단계에서 복제본을 저장하고 2단계에서 리니지(Lineage) 정보를 활용
- 노드가 고장 나더라도 데이터를 복구할 수 있는 기반이 됨
- (그림에는 명시되지 않음)
- 확장성 (Scalability):
- 이 다이어그램은 분산 처리의 3가지 핵심 성공 요소를 보여줌
1.2 분산 시스템의 핵심 배경 이론
분산 환경은 네트워크 단절, 노드 고장 등 수많은 변수가 존재함 🡲 이를 제어하기 위한 이론적 기반이 필수
- CAP 정리 (Brewer’s CAP Theorem)
- 분산 데이터 시스템은 다음 세 가지 속성 중 최대 두 가지만 만족할 수 있다는 이론
- 일관성 (Consistency):
- 어떤 노드에 접근하든 모든 사용자는 동시에 같은 데이터를 보아야 함
- 가용성 (Availability):
- 일부 노드가 다운되더라도 성공적으로 응답을 받아야 함
- 분할 관용성 (Partition Tolerance):
- 노드 간 네트워크가 단절(Partition)되어도 시스템이 정상 동작해야 함
- 일관성 (Consistency):
- 실무적 선택:
- 분산 환경에서는 네트워크 장애가 필연적 🡲 P(분할 관용성)를 기본으로 선택
- 비즈니스 성격에 따라 CP(금융권 등 정확성 중시)와 AP(소셜 미디어 등 지속 가능성 중시) 중 하나를 선택
- 분산 데이터 시스템은 다음 세 가지 속성 중 최대 두 가지만 만족할 수 있다는 이론
- PACELC 정리
- CAP 정리가 ‘네트워크 장애 상황’에만 초점을 맞춘 것을 보완
- 정상 상황(Else)에서의 지연 시간(Latency)과 일관성(Consistency)의 상충 관계까지 설명하는 이론
- 데이터 일관성 모델
- 강한 일관성 (Strong Consistency):
- 데이터 업데이트 후 모든 읽기 작업은 최신 값을 보장받음
- 최종 일관성 (Eventual Consistency):
- 일시적으로 데이터가 다를 수 있으나,
- 시간이 지나면 결국 모든 노드가 동일한 값으로 동기화됨 (예: NoSQL, Cassandra)
- 강한 일관성 (Strong Consistency):
1.3 분산 데이터 처리의 기반 기술
- 분산 처리를 실현하기 위해서는 다음의 두 체계가 맞물려야 함
- 어떻게 나누어 저장할 것인가(분산 저장)
- 어떻게 나누어 계산할 것인가(분산 컴퓨팅)
- 분산 저장 기술 (Storage Layer)
- HDFS (Hadoop Distributed File System):
- 대용량 파일을 블록(Block) 단위로 쪼개어 여러 서버에 분산 저장
- 복제본(Replica)을 생성하여 데이터 유실을 방지하는 전통적인 파일 시스템
- 오브젝트 스토리지 (AWS S3, MinIO):
- 클라우드 네이티브 환경에서 각광받는 형태
- 디렉터리 구조 없이 고유 키를 통해 비정형 데이터를 유연하게 분산 저장
- HDFS (Hadoop Distributed File System):
- 분산 컴퓨팅 기술 (Compute Layer)
- MapReduce (1세대):
- 데이터를 나누어 연산하는
Map단계와 연산 결과를 합치는Reduce단계로 구분 - 매 단계 결과를 디스크에 쓰고 읽기 때문에 디스크 I/O 병목이 발생함
- 데이터를 나누어 연산하는
- Apache Spark (2세대 - 인메모리):
- MapReduce의 디스크 병목을 해결하기 위해,
- 연산 중간 결과를 메모리(RAM)에 유지하며 처리하는 방식을 도입
- 연산 속도를 혁신적으로 끌어올림
- MapReduce (1세대):
- 클러스터 리소스 관리 (Cluster Manager)
- 여러 컴퓨터의 자원(CPU, Memory)을 효율적으로 배분하는 중재자 역할
- YARN:
- 하둡 생태계의 기본 리소스 관리자
- Kubernetes / Docker Compose:
- 최근 컨테이너 기반 환경에서 많이 활용되는 자원 격리 및 관리 기술
- YARN:
- 여러 컴퓨터의 자원(CPU, Memory)을 효율적으로 배분하는 중재자 역할
1.4 분산 처리 과정의 핵심 메커니즘과 난제
분산 처리가 실제로 수행될 때 성능과 직결되는 핵심 개념
- 파티셔닝 (Partitioning) & 샤딩 (Sharding)
- 대용량 데이터를 다룰 수 있는 작은 단위(파티션)로 나누어 저장하고 처리하는 기법
- 데이터가 특정 노드에만 몰리지 않도록(Data Skew 현상 방지) 균등하게 분배하는 전략이 중요함
- 셔플링 (Shuffling)
- 분산되어 있는 데이터들을 특정 기준(예: Group By, Join Key)에 따라 재정렬하기 위해
- 네트워크를 통해 노드 간 데이터를 주고받는 과정
- 문제점:
- 분산 처리에서 가장 많은 네트워크 비용과 지연(Latency)을 유발하는 병목 구간
- 셔플링을 최소화하는 것이 성능 최적화의 핵심
- 결함 허용 (Fault Tolerance)
- Lineage (Spark RDD):
- 데이터를 유실했을 때,
- 처음부터 데이터를 다시 만드는 것이 아니라
- 데이터가 생성된 히스토리(계보)를 기억하여
- 유실된 파티션만 똑같이 복구해내는 기술
- 데이터를 유실했을 때,
- Replication (하둡/NoSQL):
- 애초에 동일한 데이터를 3 군데 이상 복제하여 저장
- 하나의 노드가 죽어도 즉시 다른 노드가 대체하도록 만듦
- Lineage (Spark RDD):
- 분산 데이터 처리는 결국 하드웨어의 한계를 소프트웨어 아키텍처로 극복한 기술적 결실
- 오늘날의 데이터 엔지니어는 단순히 데이터를 가공하는 코드를 짜는 것을 넘어,
- “내가 작성한 코드가 네트워크 셔플을 얼마나 유발하는지”
- “데이터가 한쪽 노드로 치우치지 않고 파티셔닝이 잘 되었는지”
와 같은 분산 시스템의 생리를 깊이 이해하고 통제할 수 있어야 비로소 고성능의 파이프라인을 구축할 수 있음
2. Apache Spark 개요
- Apache Spark
- 대규모 데이터 처리를 위한 오픈 소스 분산 컴퓨팅 프레임워크
- 대용량 데이터(Big Data)를 한 대의 컴퓨터가 아닌 수십, 수백 대의 클러스터 환경에서 빠르고 안전하게 병렬 처리할 수 있도록 지원하는 현대 데이터 엔지니어링의 표준 기술
- 기존의 빅데이터 처리 표준이었던 Hadoop MapReduce의 한계를 극복하기 위해 탄생
2.1 개발 역사
- 초기 개발 및 오픈소스 전환 (2009년 ~ 2013년)
- 2009년: UC 버클리 AMPLab에서 탄생
- 마테이 자하리아(Matei Zaharia)를 비롯한 연구원들이 Hadoop MapReduce의 느린 속도와 복잡성을 해결하기 위해 연구 프로젝트로 시작
- 기존 하둡이 매 단계마다 디스크 I/O를 유발하는 점을 극복하고자, 메모리 내에서 데이터를 처리하는 RDD(Resilient Distributed Dataset) 개념을 최초로 고안
- 2010년: 오픈소스 공개
- BSD 라이선스로 소스코드가 처음 공개됨
- 2013년: Apache 인큐베이터 진입 및 Databricks 설립
- 프로젝트의 규모가 커지면서 아파치 소프트웨어 재단(ASF)의 인큐베이터 프로젝트로 채택됨
- 같은 해, Spark의 원천 개발자들이 모여 비즈니스화를 위한 기업 Databricks를 설립
- 2009년: UC 버클리 AMPLab에서 탄생
- Apache 탑레벨 프로젝트 승격 및 폭발적 성장 (2014년 ~ 2016년)
- 2014년: 아파치 탑레벨 프로젝트(Top-Level Project) 승격 및 1.0 버전 출시
- 인큐베이터 진입 후 단 8개월 만에 아파치의 최상위 프로젝트로 승격되며 빅데이터 진영의 전폭적인 지지를 받기 시작
- 전형적인 대규모 데이터 가공 분석(SQL 등)을 지원하기 위한 Spark SQL과 DataFrame API 도입
- 2015년: 하둡 MapReduce의 대체재로 급부상
- 전 세계 수많은 대기업(Yahoo, Tencent 등)이 기존 하둡 기반 인프라를 Spark로 전환하기 시작
- 머신러닝 전용 라이브러리인 MLlib와 그래프 연산 엔진 GraphX가 발전하며 단순 처리를 넘어선 종합 분석 플랫폼으로 진화
- 2014년: 아파치 탑레벨 프로젝트(Top-Level Project) 승격 및 1.0 버전 출시
- Spark 2.0 시대와 구조적 API의 정착 (2016년 ~ 2019년)
- 2016년: Spark 2.0 출시 (성능 및 표준화)
- Dataset API가 정식 도입되면서 RDD 중심의 저수준 제어에서 DataFrame/Dataset 중심의 고수준 구조적(Structured) API로 패러다임 전환
- Tungsten 엔진과 Catalyst 옵티마이저 등 내부 엔진 최적화를 통해 연산 속도가 비약적으로 상승
- 실시간 스트리밍 처리를 SQL 엔진 위에서 직관적으로 다룰 수 있게 한 Structured Streaming 도입
- 2016년: Spark 2.0 출시 (성능 및 표준화)
- Spark 3.0 시대와 클라우드 네이티브로의 진화 (2020년 ~ 현재)
- 2020년: Spark 3.0 출시 (적응형 쿼리 및 쿠버네티스 지원)
- 런타임 중에 쿼리 실행 계획을 스스로 최적화하는 AQE(Adaptive Query Execution) 기능 추가
- 개발자가 세부 설정을 일일이 튜닝하지 않아도 지능적으로 최적의 파티셔닝과 조인(Join) 방식을 찾아가게 됨
- 기존 Hadoop YARN 중심에서 벗어나 Kubernetes(K8s) 지원이 공식적으로 안정화(GA)
- 클라우드 네이티브 인프라와의 결합이 가속화됨
- 런타임 중에 쿼리 실행 계획을 스스로 최적화하는 AQE(Adaptive Query Execution) 기능 추가
- 현재 (2020년대 중반): 레이크하우스(Lakehouse) 아키텍처의 중심
- 최근 데이터 엔지니어링 생태계
- Apache Iceberg, Delta Lake 등 고성능 스토리지 테이블 포맷과 Spark를 연동
🡲 트랜잭션 처리가 가능한 레이크하우스(Lakehouse)를 구축하는 것이 대세
- Apache Iceberg, Delta Lake 등 고성능 스토리지 테이블 포맷과 Spark를 연동
- Python 생태계와의 완벽한 통합(Pandas API on Spark 등) 및 AI/ML 연산 성능 강화를 지속적으로 이어가고 있음
- 최근 데이터 엔지니어링 생태계
- 2020년: Spark 3.0 출시 (적응형 쿼리 및 쿠버네티스 지원)
[2009년] UC 버클리 탄생 (Hadoop의 디스크 병목 극복 목적)
🡳
[2014년] Apache 탑레벨 승격 & 1.0 (인메모리 분산 처리의 대중화)
🡳
[2016년] Spark 2.0 (DataFrame 및 Structured API 표준화)
🡳
[2020년] Spark 3.0 (AQE 도입 및 Kubernetes 클라우드 네이티브 최적화)
🡳
[현재] Iceberg 등과 결합하여 '현대적 데이터 레이크하우스'의 표준 엔진으로 군림
2.2 핵심 개념: RDD
- Spark의 근간이 되는 데이터 모델은 RDD (Resilient Distributed Dataset)
- Resilient (탄력적):
- 메모리 내에서 데이터가 손실될 경우 리니지(Lineage)를 통해 자동으로 복구됨
- Distributed (분산):
- 클러스터 내의 여러 노드에 데이터가 나누어 저장됨
- Dataset (데이터셋):
- 객체들의 모음
- Resilient (탄력적):
- 현재는 RDD를 기반으로 최적화된 DataFrame과 Dataset API를 주로 사용하여 데이터 분석을 수행함
2.3 사용 목적 및 활용도
- 사용 목적
- 실시간 데이터 처리:
- 대량의 데이터를 스트리밍 방식으로 즉시 분석
- 반복적 알고리즘 수행:
- 머신러닝 모델 학습과 같이 동일한 데이터를 여러 번 조회해야 하는 작업에 최적화됨
- 통합 분석 환경:
- SQL 쿼리, 스트리밍, 그래프 처리, 머신러닝을 하나의 엔진에서 처리할 수 있음
- 실시간 데이터 처리:
- 주요 활용도
- 배치 처리 (Batch Processing):
- 대규모 로그 분석 및 ETL 작업
- 머신러닝 (MLlib): -분류, 회귀, 클러스터링 등 대규모 데이터 기반 학습
- 실시간 스트리밍 (Spark Streaming): -금융 사기 탐지, 실시간 센서 데이터 모니터링
- 대화형 분석 (Spark SQL): -SQL을 사용하여 대규모 데이터셋을 빠르게 탐색
- 그래프 처리 (GraphX): -소셜 네트워크 분석이나 추천 엔진
- 배치 처리 (Batch Processing):
2.4 Apache Spark의 장단점
- 장점
- 속도 (In-memory Computing):
- 데이터를 디스크가 아닌 메모리에 유지하며 처리
- MapReduce보다 최대 100배(디스크 기준 10배) 빠름
- 사용 편의성:
- Java, Scala, Python, R 등 다양한 언어를 지원
- 80개 이상의 고수준 연산자를 제공
- 결함 허용 (Fault Tolerance):
- 작업 중 노드가 고장 나도 작업을 처음부터 다시 할 필요 없이 유실된 부분만 계산하여 복구
- 통합성:
- Hadoop(HDFS), Cassandra, HBase, S3 등 다양한 데이터 소스와 쉽게 연동됨
- 속도 (In-memory Computing):
- 단점
- 높은 메모리 비용:
- 모든 처리를 메모리 위에서 하려다 보니 RAM 사용량이 매우 많고 비용 부담이 발생할 수 있음
- 설정의 복잡성:
- 최적의 성능을 내기 위해 메모리 관리, 파티션 크기 등 세부적인 튜닝(Tuning)이 까다로움
- 실시간 응답 한계:
- ‘마이크로 배치’ 방식을 사용하기 때문에
- Apache Flink와 같은 순수 스트리밍 엔진에 비해 완전한 실시간(Millisecond 단위) 응답 속도는 미세하게 떨어질 수 있음
- 높은 메모리 비용:
2.5 기술 스택 구성 요소
- Spark는 목적에 따라 다음과 같은 라이브러리를 포함함
| 구성 요소 | 설명 |
|---|---|
| Spark SQL | 구조화된 데이터를 SQL로 처리 |
| Spark Streaming | 실시간 스트리밍 데이터 처리 |
| MLlib | 머신러닝 라이브러리 |
| GraphX | 그래프 및 병렬 그래프 계산 |
- 과거에는 하둡이 빅데이터의 전부였다면,
- 현재는 “저장은 하둡(HDFS), 처리는 스파크(Spark)”라는 공식이 보편적으로 쓰일 만큼 데이터 엔지니어링 분야에서 필수적인 도구
3. Trino와의 비교
- Trino와 Apache Spark는 둘 다 빅데이터 생태계에서 가장 널리 쓰이는 오픈소스 분산 처리 엔진
현대적인 데이터 플랫폼(Lakehouse)을 운영하는 기업들은 이 둘을 경쟁 관계로 보지 않고 동시에 함께 사용(조합)
- 아키텍처 및 데이터 처리 방식의 근본적 차이
- 두 도구가 데이터를 다루는 방식은 ‘F1 레이싱카(Trino)’와 ‘거대 화물 열차(Spark)’의 차이로 비유할 수 있음
비교 항목 Trino (트리노) Apache Spark (스파크) 핵심 패러다임 MPP (Massive Parallel Processing) MapReduce 기반 메모리 확장형 뼈대 처리 방식 인메모리 스트리밍 파이프라인
(중간 결과를 디스크에 쓰지 않고 다음 단계로 직송)스테이지(Stage) 기반 단계적 처리
(안정성을 위해 단계별로 디스크/메모리에 셔플링)인터페이스 순수 표준 ANSI SQL만 지원 다중 언어 프로그래밍 API 지원
(Python, Scala, Java, R + Spark SQL)내결함성
(Fault Tolerance)중(Medium)
기본적으로 중간 실패 시 전체 쿼리 재실행
(최근 아키텍처 개선으로 태스크 리트라이가 추가됨)최상 (Highest)**
데이터 유실 시 `RDD 계보(Lineage)`를 추적해 실패한 특정 파티션만 자동 복구 가능데이터 연합
(Data Federation)매우 강력
서로 다른 물리 DB를 SQL 한 줄로 실시간 조인제한적
코드로 구현은 가능하나 오버헤드가 크고 실시간 조인에 불리함동시성 (Concurrency) 한 클러스터에서 수백 개의 동시 쿼리 처리 가능 대규모 동시성(High Concurrency) 대응에 비효율적 - Trino와 Spark를 ‘같이’ 사용하는 이유 (조합 패턴)
- “목적이 비슷하다면 같이 사용할 이유가 없을 것이다???”
- 두 도구의 장점이 정반대에 있기 때문에, 현대적 데이터 레이크하우스(Data Lakehouse) 아키텍처에서는 두 엔진을 무조건 혼용하는 것이 표준 패턴(Best Practice)
- 두 도구는 데이터의 저장 포맷(예: Apache Iceberg, Delta Lake)과 중앙 메타스토어(예: Hive Metastore, Nessie)를 공유하며 완벽하게 공존
- 실제 기업들의 협업 시나리오 (ETL은 Spark, 조회의 Trino)
- [Spark 역할 - 거대 무쇠 가마솥]:
- 매일 새벽,
- 전날 발생한 테라바이트급의 가공되지 않은 Raw 로그(JSON, CSV 등)를 긁어모아 복잡한 비즈니스 로직을 적용하고,
- 압축률과 조회가 빠른 오픈 테이블 포맷(Parquet, Iceberg 등)으로 변환하여
- S3(데이터 레이크)에 저장
- 이 과정에서 노드가 몇 개 죽어도 Spark은 이어서 작업을 완수
- 매일 새벽,
- [Trino 역할 - 초고속 에스프레소 머신]:
- 출근한 데이터 분석가, 마케터, 혹은 사내 BI 대시보드(Tableau, Superset)가
- S3에 잘 정제되어 저장된 Iceberg 테이블을 조회
- Trino는 이 쿼리를 몇 초 만에 처리해 대시보드에 뿌려줌
- 마케터가 “어제 로그 데이터랑 마케팅 MySQL DB에 있는 유저 정보를 합쳐서 보고 싶다”고 하면,
- Trino가 그 자리에서 두 저장소를 엮어 즉시 결과를 도출
- 출근한 데이터 분석가, 마케터, 혹은 사내 BI 대시보드(Tableau, Superset)가
- [Spark 역할 - 거대 무쇠 가마솥]:
상황별 권장 가이드: 언제 무엇을 써야 할까?
- Trino가 강력히 권장되는 경우 (Query & Analytics)
- BI 대시보드 및 실시간 시각화 툴 연동:
- 사용자가 대시보드 필터를 바꿀 때마다 쿼리가 날아가므로,
- 초 단위의 빠른 반응 속도가 필수적일 때
- Ad-hoc(대화형) 데이터 탐색:
- 데이터 사이언티스트나 분석가가 “이 데이터는 어떻게 생겼지?” 하고 이것저것 쿼리를 날려보며
- 즉각적인 피드백을 원할 때
- 데이터 이동(ETL) 없는 파편화된 데이터 조회:
- 데이터가 AWS S3, 로컬 PostgreSQL, MongoDB 등에 사방으로 흩어져 있고,
- 이를 한 곳으로 복사해오는 파이프라인을 만들 시간적/비용적 여유가 없을 때
- 엔지니어가 아닌 현업 분석가 중심 환경:
- 프로그래밍 언어(Python, Scala)를 모르는 분석가들이
- 표준 SQL만으로 빅데이터를 다루어야 할 때
- BI 대시보드 및 실시간 시각화 툴 연동:
- Spark가 강력히 권장되는 경우 (Processing & Engineering)
- 무겁고 복잡한 배치 대용량 변환 (Heavy ETL):
- 몇 시간 동안 수십 TB의 데이터를 정제, 압축, 정렬하여 마트(Data Mart)를 구축해야 할 때
- 도중에 작업이 터지면 안 되는 절대 안정성이 필요한 영역
- 몇 시간 동안 수십 TB의 데이터를 정제, 압축, 정렬하여 마트(Data Mart)를 구축해야 할 때
- 머신러닝(ML) 및 데이터 사이언스 파이프라인:
- 데이터 추출에 그치지 않고,
Spark MLlib등을 활용해- 분산 환경에서 모델을 학습시키거나 대규모 예측(Prediction)을 수행해야 할 때
- 비정형 데이터 가공 및 복잡한 프로그래밍 인터페이스 필요 시:
- 단순 SQL 함수만으로는 표현하기 힘든 복잡한 알고리즘, 파이썬 라이브러리(Pandas 등) 연계,
- 혹은 문자열 파싱 로직을 UDF(사용자 정의 함수)나 코드로 촘촘하게 짜야 할 때
- 실시간 스트림 처리(Streaming):
- Kafka 등에서 쏟아지는 데이터를 실시간으로 캐치하여 가공(Spark Structured Streaming)해야 할 때
- 무겁고 복잡한 배치 대용량 변환 (Heavy ETL):
- Trino가 강력히 권장되는 경우 (Query & Analytics)
- Spark는 데이터 엔지니어가 대규모 데이터를 뚝딱거리고 가공하는 ‘생산 및 가공 전용 공장’
- Trino는 데이터 분석가와 소비자가 가공된 데이터(혹은 원천 데이터)를 막힘없이 빠르게 꺼내 먹는 ‘고속 소비 창구’
- 따라서 인프라를 설계할 때는
- 무거운 정기 배치 작업은 Spark에 맡겨 안정적으로 데이터를 정제해 두고,
- 그 데이터를 포함한 전사 데이터 조회 인터페이스는 Trino로 단일화하여
- 분석 효율을 극대화하는 것이 가장 이상적