Spark 설치 및 환경 설정
1. Apache Spark 설치 및 환경 설정
- docker 환경(컨테이너 이미지 등 포함)을 깨끗하게 지워야 할 경우
- 일반적으로는 권장하지 않음 🡲 다양한 충돌이 해결되지 않을때 어쩔 수 없이 실행하는것
# 1. 현재 컴포즈 서비스 중지 및 오펀 컨테이너 제거 docker-compose down --remove-orphans # 2. 혹시 프로세스가 좀비 상태로 살아있다면 컨테이너 전체 강제 셧다운 및 삭제 docker stop $(docker ps -a -q) 2>/dev/null docker rm -f $(docker ps -a -q) 2>/dev/null # 3. 충돌을 유발하는 모든 유령 볼륨(MinIO 물리 데이터 포함) 완전 소거 docker volume prune -f # 4. 포트 꼬임 및 가상 IP 충돌의 주범인 도커 네트워크 브리지 일괄 초기화 docker network prune -f # 5. 도커 시스템에 남아있는 모든 잔여 빌드 캐시 및 미사용 리소스 대청소 docker system prune -a -f- 일반적인 경우에는 다음 명령으로 충분함
docker compose down
1.1 방법 A: 로컬 Standalone 설치
- 사전 필수 요구사항 (Pre-requisites)
- Spark는 JVM(Java Virtual Machine) 위에서 동작하므로 Java 설치 필수
Python API(PySpark)를 사용하기 위해 Python 환경이 준비되어야 함
- Java JDK:
- Java 11 또는 Java 17을 권장 (Spark 3.x 버전 이상 기준): 호환성이 가장 좋음
- Python: 3.8 ~ 3.11 버전 권장
- 운영체제:
- Linux 또는 macOS를 권장
- Windows의 경우
winutils.exe설정이 추가로 필요함
- Spark 다운로드 및 압축 해제
- Apache Spark 공식 다운로드 페이지에서 원하는 버전을 선택
- 예: Spark 3.5.x, Pre-built for Apache Hadoop 3.3 이상
터미널에서 다운로드 및 압축 해제
wget https://archive.apache.org/dist/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz tar -xvzf spark-3.5.1-bin-hadoop3.tgz mv spark-3.5.1-bin-hadoop3 /opt/spark
- Apache Spark 공식 다운로드 페이지에서 원하는 버전을 선택
- 환경 변수 설정 (
.bashrc또는.zshrc)어느 경로에서나 Spark 명령어를 실행할 수 있도록 환경 변수 등록
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 # 본인의 Java 경로에 맞게 수정 export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin export PYSPARK_PYTHON=python3설정 후
source ~/.bashrc(또는~/.zshrc)를 실행하여 적용
- 실행 테스트
- Spark Shell (Scala):
spark-shell명령어 입력 - PySpark (Python):
pyspark명령어 입력 - 정상 실행 시 터미널에 대형
Spark로고와 함께 대화형 콘솔이 나타남
- Spark Shell (Scala):
1.2 방법 B: Docker Compose 기반 M-W 구조
- 커리큘럼에 포함된 Master-Worker(M-W) 구조를 로컬 가상화 환경에 가장 깔끔하게 구축하는 방법
- Bitnami에서 제공하는 검증된 이미지를 사용하면 편리함
docker-compose.yml파일 작성- 프로젝트 디렉터리를 만들고 아래와 같이 작성
- 이 구조는 Master 노드 1대와 Worker 노드 2대를 띄우는 가상 클러스터
name: spark-cluster
services:
spark-master:
image: apache/spark:3.5.0
container_name: spark-master
command:
- /opt/spark/bin/spark-class
- org.apache.spark.deploy.master.Master
ports:
- "8080:8080"
- "7077:7077"
spark-worker-1:
image: apache/spark:3.5.0
container_name: spark-worker-1
command:
- /opt/spark/bin/spark-class
- org.apache.spark.deploy.worker.Worker
- spark://spark-master:7077
environment:
SPARK_WORKER_MEMORY: 2G
SPARK_WORKER_CORES: 2
ports:
- "8081:8081"
depends_on:
- spark-master
spark-worker-2:
image: apache/spark:3.5.0
container_name: spark-worker-2
command:
- /opt/spark/bin/spark-class
- org.apache.spark.deploy.worker.Worker
- spark://spark-master:7077
environment:
SPARK_WORKER_MEMORY: 2G
SPARK_WORKER_CORES: 2
ports:
- "8082:8081"
depends_on:
- spark-master
- docker-compose.yml 상세 설명
- 전체 구조: 3개의 서비스로 구성
- spark-master 🡲 클러스터 관리자
- spark-worker-1 🡲 작업 실행 노드 1
- spark-worker-2 🡲 작업 실행 노드 2
Spark Cluster ├── Master (스케줄러) ├── Worker 1 (실행 노드) └── Worker 2 (실행 노드) - name: spark-cluster
- Compose 프로젝트 이름 🡲 이 이름이 컨테이너 이름 prefix로 사용됨
- 예: spark-cluster-spark-master-1, spark-cluster-spark-worker-1-1
- Compose 프로젝트 이름 🡲 이 이름이 컨테이너 이름 prefix로 사용됨
- image: apache/spark:3.5.0
- 3.5.0과 같은 태그를 가능한 한 붙일 것을 권장함
- 태그가 없으면(또는 latest를 사용하면) 매 실행 시 마다 최신 버전으로 적용 🡲 수시로 버전 변경
- 다음과 같은 문제가 발생하기 쉬움
- 어제는 됐는데 오늘은 안 됨
- Spark 버전이 바뀜
- Python 버전 등 내부 구성요소의 버전이 바뀜
- 다음과 같은 문제가 발생하기 쉬움
- Master, Worker 모두 동일한 Spark 환경 선택
- Worker도 Spark Binary가 필요함
- container_name: 컨테이너의 이름
- 충돌 발생 가능 🡲 중복 사용 불가, 여러 프로젝트에서 동시에 실행 불가
- 여러 Spark 프로젝트를 번갈아 띄우는 경우에는 container_name 제거 권장
- container_name이 없으면 Compose가 prefix를 사용하여 자동으로 이름을 할당함
command: Docker 컨테이너가 시작될 때 실행할 명령
command: - /opt/spark/bin/spark-class - org.apache.spark.deploy.master.Master- 실제로 실행되는 형태
/opt/spark/bin/spark-class org.apache.spark.deploy.master.Master- 역할: Spark Master 프로세스 실행 🡲 클러스터 관리 시작
- 실행 명령의 차이
- /opt/spark/bin/spark-class org.apache.spark.deploy.master.Master
- Spark 프로세스가 포그라운드(foreground)에서 실행됨
- /opt/spark/sbin/start-worker.sh spark://spark-master:7077
- start-master.sh, start-worker.sh는 백그라운드 데몬 실행 후 스크립트 종료를 위한 스크립트
- 즉,
start-master.sh 실행 🡲 Master 프로세스를 백그라운드로 띄움 🡲 쉘 스크립트 종료 🡲 컨테이너 종료가 됨- 실행 후 계속 종료되는 이유임
- Exited (0): 명령을 정상적으로 수행하고 종료함
- Exited (127)가 나오는 경우
command: /opt/spark/sbin/start-master.sh에서 나왔다면 실제 이미지 내부에는/opt/spark/sbin가 존재하지 않을 수 있음
문제 발생 시 확인 방법
docker compose logs spark-master docker compose logs spark-worker-1- 예상 결과
Case 1: 백그라운드 실행 후 쉘 종료
starting org.apache.spark.deploy.master.Master ... stopping org.apache.spark.deploy.master.MasterCase 2: Exit 127
/opt/spark/sbin/start-master.sh: No such file or directoryCase 3: container_name 충돌
spark-master already exists
- 예상 결과
최근 공식 이미지에서는 다음 방식을 권장함
# Master command: - /opt/spark/bin/spark-class - org.apache.spark.deploy.master.Master # Worker: Worker 실행 + Master 연결 command: - /opt/spark/bin/spark-class - org.apache.spark.deploy.worker.Worker - spark://spark-master:7077- spark-class를 사용하는 이유
- Spark는 직접 jar 실행 대신:
- 환경 설정 자동 적용
- classpath 자동 구성
- 을 위해 spark-class 사용
- Spark는 직접 jar 실행 대신:
- spark-class를 사용하는 이유
Worker의 command에서
- spark://spark-master:7077- spark-master를 사용하는 이유
- Docker Compose 내부 DNS 때문:
- spark-master = 서비스 이름
- 자동으로 내부 IP로 해석됨
- Docker Compose 내부 DNS 때문:
- 동작의 흐름
- Worker 시작 🡲 Master 주소로 접속 🡲 등록 요청 🡲 클러스터 참여
- spark-master를 사용하는 이유
- /opt/spark/bin/spark-class org.apache.spark.deploy.master.Master
- ports
- 8080: 브라우저 접속 포트 🡲 Spark 상태 UI
- 7077: Spark 내부 통신 포트. Worker 🡲 Master 연결 및 클러스터 작업 전달
- 8081: 브라우저 접속 포트 🡲 Worker UI
- 8082: 브라우저 접속 포트 🡲 두 번째 Worker UI, 호스트 8082로 접근 🡲 포트 충돌 방지를 위함
environment: Worker의 리소스 제한
environment: SPARK_WORKER_MEMORY: 2G SPARK_WORKER_CORES: 2depends_on: 실행 순서 보장
spark-worker-1: depends_on: - spark-master- spark-master 먼저 실행, spark-worker-1는 이후 실행
- 실행 순서 만 보장함 🡲 Master 준비 완료, 7077 포트 열림 등은 보장하지 않음
- 전체 구조: 3개의 서비스로 구성
1.3 HOST 작업환경 구성
- Docker Compose 운영환경 그대로 사용할 경우
- 컨테이너 내부에 직접 들어가서 명령어를 쳐야 하므로 코드 작업이 매우 불편함
- 코드는 HOST(내 컴퓨터)에서 편하게 편집, 실행은 도커(컨테이너) 내부에서 돌아가도록 연결할 것을 권장함
- 실무에서 가장 많이 쓰는 패턴
- 볼륨 마운트 (Volume Mount)
- 코드는 HOST의 VS Code 등으로 편집
- 코드 파일이 들어있는 폴더를 도커 컨테이너 내부와 실시간으로 동기화(연결)
- 작업 방식:
- 호스트 PC의 특정 폴더(예:
~/workspace/spark_project)에app.py라는 파이썬 코드 작성 docker-compose.yml설정에서 이 폴더를 Spark 컨테이너 내부의 특정 경로와 연결(volumes옵션)- 호스트에서 코드를 수정하고 저장하면, 컨테이너 내부에도 즉시 반영됨
- 실행할 때는 도커 터미널을 통해 컨테이너 안에서
spark-submit app.py를 입력해 실행- 장점:
- 호스트의 강력한 IDE(VS Code 등) 환경을 그대로 쓰면서,
- 실행은 깨끗한 도커 환경에서 할 수 있음
- 호스트 PC의 특정 폴더(예:
- 주피터 노트북 (Jupyter Notebook) 패턴: 브라우저 활용
- 데이터 분석이나 Spark 실습 시 가장 직관적인 방법
- 작업 방식:
- Spark 도커 이미지 안에 이미 주피터 노트북(또는 주피터 랩) 서버가 내장되어 있거나 추가되어 있음
- 도커를 띄우면 컨테이너 내부에서 주피터 서버가 돌아감
- 사용자는 호스트 PC의 크롬 브라우저를 열고
http://localhost:8888에 접속 - 웹 브라우저 화면에서 파이썬 코드를 작성하고 즉시 실행(
Shift + Enter)- 장점:
- 코드 작성과 실행 결과 확인이 웹 브라우저 하나로 끝나므로 학습 및 프로토타이핑에 최적
- 생성된
.ipynb파일은 앞서 말한 볼륨 마운트를 통해 호스트 PC에 안전하게 저장됨
- 데이터 분석이나 Spark 실습 시 가장 직관적인 방법
- 고급 패턴: VS Code의 ‘Dev Containers’ 확장 기능 사용
- 최근 시니어 개발자나 엔지니어들이 가장 선호하는 깔끔한 방식
- 작업 방식:
- 호스트 PC의 VS Code에
Dev Containers라는 공식 확장 프로그램을 설치 - VS Code 자체를 도커 컨테이너 내부로 접속
- 화면은 내 컴퓨터에 떠 있지만, VS Code가 인식하는 파이썬 환경, 확장 프로그램, 터미널은 전부 도커 컨테이너 내부의 환경이 됨
- 장점:
- 호스트 PC에 파이썬을 깔지 않아도 코드 자동 완성(IntelliSense)이나 디버깅 기능이 컨테이너 내부 스택에 맞춰 완벽하게 작동함
- 호스트 PC의 VS Code에
- 최근 시니어 개발자나 엔지니어들이 가장 선호하는 깔끔한 방식
- 볼륨 마운트 (Volume Mount)
2. Spark 기본 실습
2.1 단계별 실습
실습 목적: “Spark Cluster가 실제로 동작하는지” 검증
모듈 구성 형태
Spark Master ├─ Worker 1 └─ Worker 2실습 내용
- Python(PySpark)에서 Spark 연결
- DataFrame 생성
- 분산 처리 실행
- Worker가 실제로 작업 수행
0단계 : 사전작업
python -m venv myspark cd myspark source ./bin/activate pip install pyspark==3.5.0- 간혹 가상환경 생성 문제로 pip 등이 제대로 실행되지 않는 경우가 있음
- 다음 명령을 통해 python, pip가 제대로 가상환경의 경로 안에 있는지 확인할 것
which python which pip- 정상인 경우 예상 결과 (가상환경의 위치가 workspace/myspark/ 일때)
/home/userid/workspace/myspark/bin/python /home/userid/workspace/myspark/bin/pip - Docker Compose 내부 Spark 버전이 3.5.0 🡲 작업 중인 Host에서 설치하는 pyspark도 3.5.0으로 맞추어야 버전 불일치 오류가 발생하지 않음
- 현재 시점에서 pip install pyspark를 실행하면 4.1.2 버전이 설치됨 🡲 버전 불일치 오류 발생(로그가 길어서 원인을 찾기가 어려움)
- 간혹 가상환경 생성 문제로 pip 등이 제대로 실행되지 않는 경우가 있음
1단계 : Spark Cluster 연결 확인
#//file: "test_connection.py" from pyspark.sql import SparkSession spark = ( SparkSession.builder .appName("Spark Connection Test") .master("spark://spark-master:7077") .getOrCreate() ) print("Spark Version :", spark.version) print("Master :", spark.sparkContext.master) spark.stop()실행
docker exec -it spark-master bash spark-submit /opt/spark/work/test_connection.py또는
python test_connection.py
예상 결과
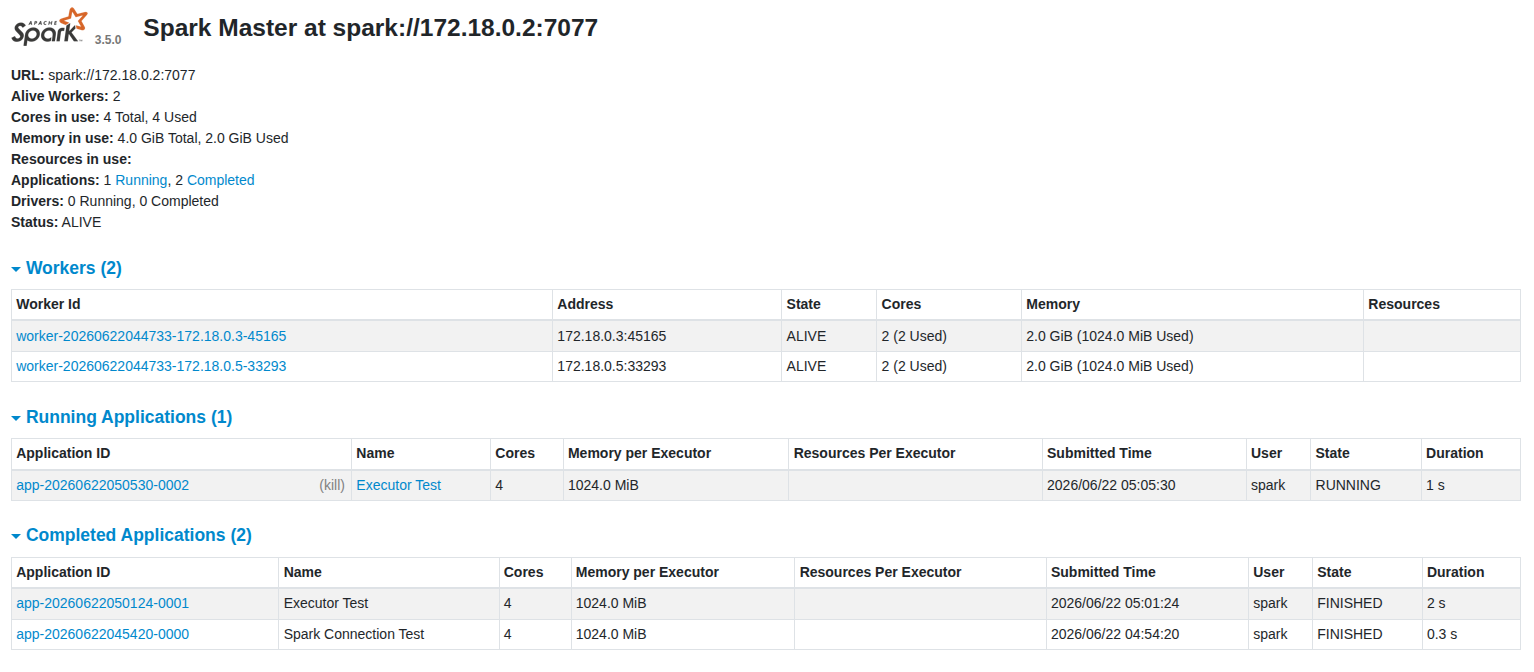
Spark Version : 3.5.0 Master : spark://spark-master:7077Spark UI (http://localhost:8080) 🡲 브라우저 화면에 다음이 표시되는지 확인
Completed Applications
2단계 : Worker가 작업을 수행하는지 확인
#//file: "test_job.py" from pyspark.sql import SparkSession spark = ( SparkSession.builder .appName("Worker Test") .master("spark://localhost:7077") .getOrCreate() ) sc = spark.sparkContext data = range(1, 1000001) result = ( sc.parallelize(data, 4) .map(lambda x: x * 2) .sum() ) print(f"Result = {result}") spark.stop()python test_job.py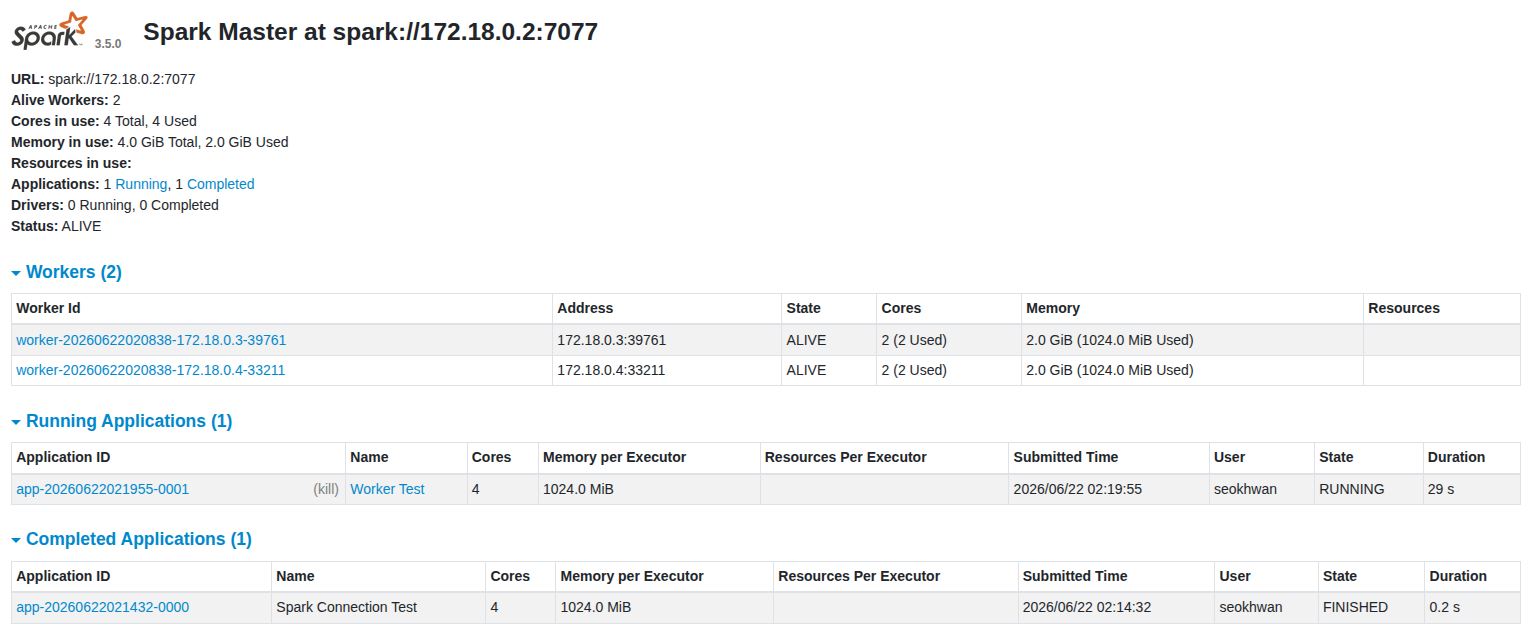
3단계 : Worker가 실제로 분산 처리하는지 확인
#//file: "test_distributed.py" from pyspark.sql import SparkSession import socket spark = ( SparkSession.builder .appName("Executor Test") .master("spark://localhost:7077") .getOrCreate() ) sc = spark.sparkContext def who_am_i(x): return socket.gethostname() hosts = ( sc.parallelize(range(1000), 8) .map(who_am_i) .distinct() .collect() ) print(hosts) spark.stop()python test_distributed.py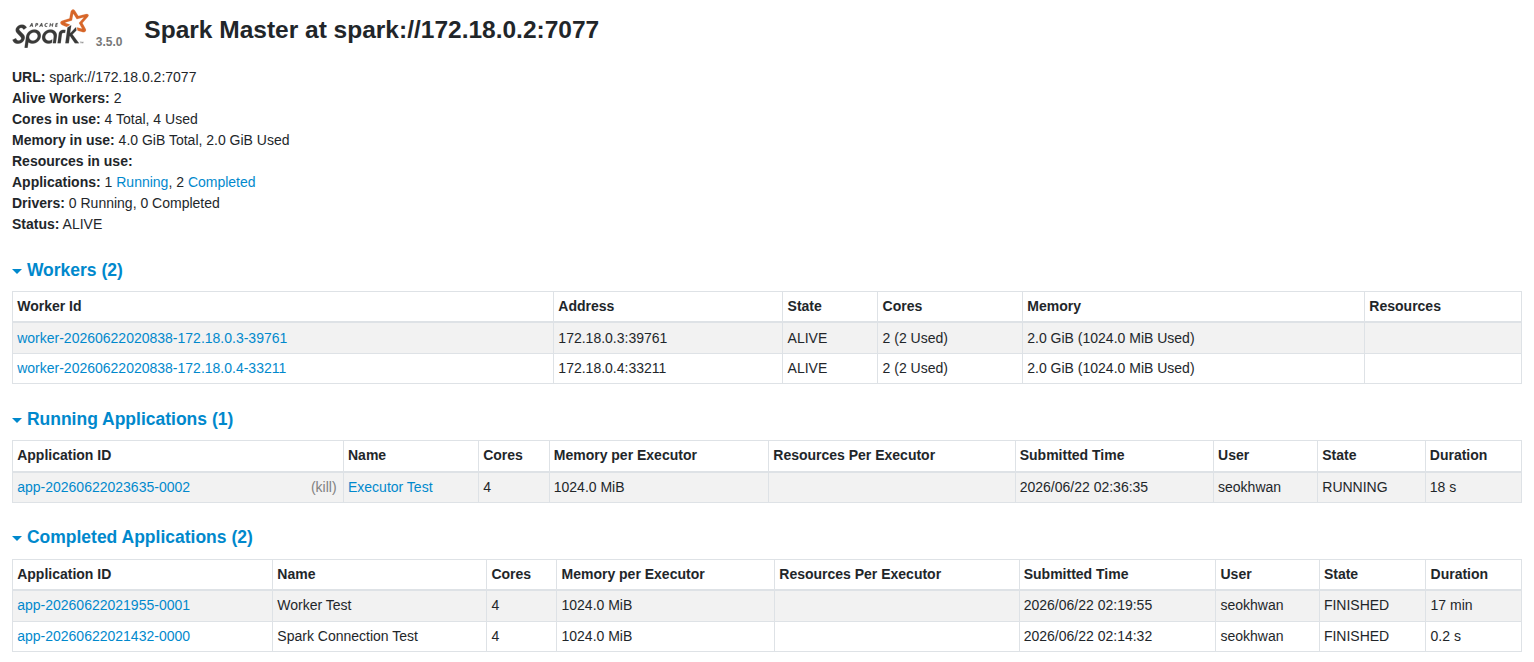
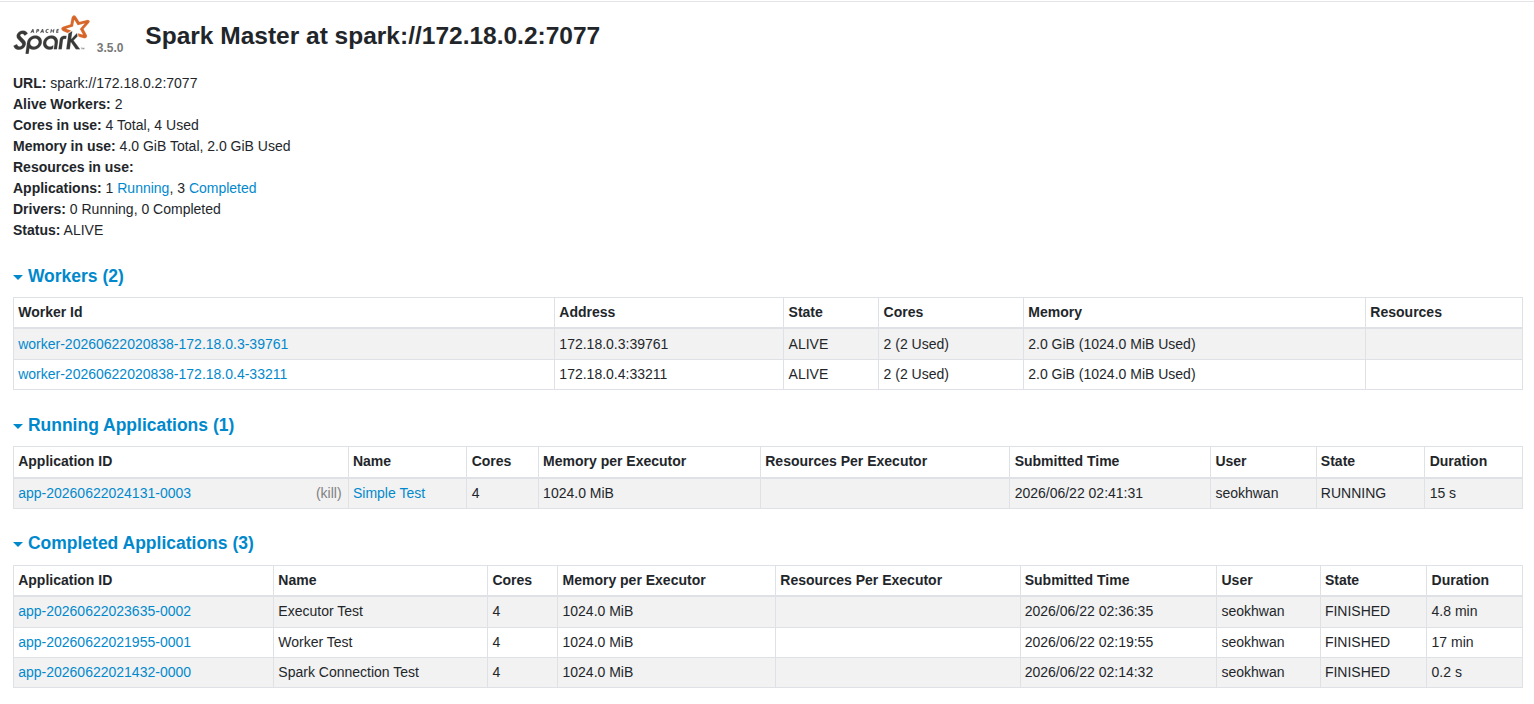
- Spark Cluster는 정상작동 중
- 그러나 Log 출력에는 정상적인 결과가 나오지 않음
- 도커내부에서 외부로 보내는 출력은 172.18.0.xx, Host의 드라이버는 192.168.0.xx 🡲 네트워크 간 소통 문제 발생
- docker-compose.yml의 내용을 다시 맞추어서 설정하거나, 파이썬 코드 내에 관련 설정을 추가하여 해결 가능
- 그러나 이런 문제가 새로운 상황마다 발생 가능 🡲 운영이 어려움
현재의 구조는 다음과 같음
호스트 Ubuntu └─ Python Driver Docker ├─ Spark Master ├─ Worker1 └─ Worker2- Driver 🡘 Executor 통신 문제가 계속 발생할 것으로 예상
추천 구조
myspark/ ├── docker-compose.yml ├── test_connection.py ├── test_simple.py ├── test_distributed.py └── data/
- 환경 설정 보완
- Host의 작업 디렉토리를 도커와 마운트, 도커 안에서 실행하는 방향으로 전환
docker-compose.yml 수정
name: spark-cluster services: spark-master: image: apache/spark:3.5.0 container_name: spark-master command: - /opt/spark/bin/spark-class - org.apache.spark.deploy.master.Master ports: - "8080:8080" - "7077:7077" spark-worker-1: image: apache/spark:3.5.0 container_name: spark-worker-1 command: - /opt/spark/bin/spark-class - org.apache.spark.deploy.worker.Worker - spark://spark-master:7077 environment: SPARK_WORKER_MEMORY: 2G SPARK_WORKER_CORES: 2 depends_on: - spark-master spark-worker-2: image: apache/spark:3.5.0 container_name: spark-worker-2 command: - /opt/spark/bin/spark-class - org.apache.spark.deploy.worker.Worker - spark://spark-master:7077 environment: SPARK_WORKER_MEMORY: 2G SPARK_WORKER_CORES: 2 depends_on: - spark-master spark-client: image: apache/spark:3.5.0 container_name: spark-client command: tail -f /dev/null volumes: - ./:/workspace working_dir: /workspace depends_on: - spark-masterdocker compose down docker compose up -d docker ps- 예상 결과
spark-master spark-worker-1 spark-worker-2 spark-client- 컨테이너 진입
docker exec -it spark-client bash- 마운트 확인
cd /workspace ls- 예상 출력: Host의 파일이 그대로 보여야 함
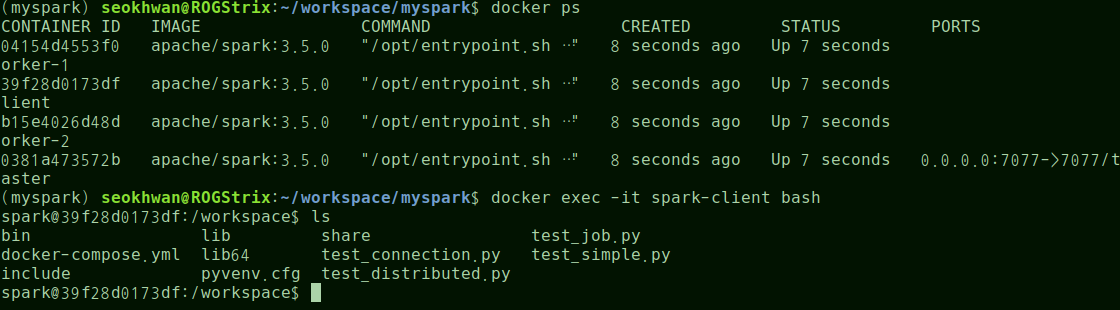
docker-compose.yml test_connection.py test_simple.py test_distributed.py- 잘 진행되었다면
Master 주소를 바꾸는 것이 좋음
from pyspark.sql import SparkSession spark = ( SparkSession.builder .appName("Simple Test") .master("spark://spark-master:7077") .getOrCreate() )앞으로 Python 코드 수정은 불필요해짐
확인
#//file: "test_simple.py" from pyspark.sql import SparkSession spark = ( SparkSession.builder .appName("Simple Test") .master("spark://spark-master:7077") .getOrCreate() ) sc = spark.sparkContext result = ( sc.parallelize(range(1000), 4) .map(lambda x: x + 1) .sum() ) print(result) spark.stop()python test_simple.py- 또는
spark-submit \ --master spark://spark-master:7077 \ test_simple.py- Python이 없다고 나올 수 있음
- 해당 Image는 필요한 최소한의 항목들만 포함되어 있음
프로젝트에 Dockerfile 생성
myspark/ ├── docker-compose.yml ├── Dockerfile.spark-client ├── test_simple.py └── ...Dockerfile.spark-client 추가
FROM apache/spark:3.5.0 USER root RUN apt-get update && \ apt-get install -y python3 python3-pip && \ ln -s /usr/bin/python3 /usr/bin/python RUN pip3 install pyspark==3.5.0 pandas pyarrow USER sparkdocker-compose.yml 수정
spark-client: build: context: . dockerfile: Dockerfile.spark-client container_name: spark-client command: tail -f /dev/null volumes: - ./:/workspace working_dir: /workspace depends_on: - spark-masterdocker compose up -d docker exec -it spark-client bash python --version python -c "import pyspark; print(pyspark.__version__)"- 결과
Python 3.8.10 3.5.0- 마운트 확인 (현재 컨테이너 내부임)
cd /workspace ls- 결과
docker-compose.yml test_connection.py test_simple.py test_distributed.py ...- 컨테이너 내부에서 파이썬 파일 실행
- client master 경로를 바꿔줘야 함
spark = ( SparkSession.builder .appName("Spark Connection Test") .master("spark://spark-master:7077") .getOrCreate() )
python test_connection.py- 결과

실제 분산 여부 확인
#//file: "test_executor.py" from pyspark.sql import SparkSession import socket spark = ( SparkSession.builder .appName("Executor Test") .master("spark://spark-master:7077") .getOrCreate() ) rdd = spark.sparkContext.parallelize(range(100), 8) hosts = ( rdd .map(lambda x: socket.gethostname()) .distinct() .collect() ) print("실행된 Executor Host:") for host in hosts: print(host) spark.stop()
- 매번 컨테이너에 들어가기 싫다면 Alias 활용
alias sparkrun='docker exec -it spark-client' sparkrun python /workspace/test_simple.py- 향후, Spark + Iceberg + MinIO 등으로 확장하려면 지금처럼 spark-client 컨테이너를 추가하는 방식이 가장 자연스러움
- 4단계 : DataFrame 생성
- Spark의 핵심 객체는 DataFrame
#//file: "test_dataframe.py" from pyspark.sql import SparkSession spark = ( SparkSession.builder .appName("DataFrame Test") .master("spark://spark-master:7077") .getOrCreate() ) data = [ (1, "Kim", 30), (2, "Lee", 25), (3, "Park", 40) ] df = spark.createDataFrame( data, ["id", "name", "age"] ) df.show() spark.stop()결과
+---+----+---+ | id|name|age| +---+----+---+ | 1| Kim| 30| | 2| Lee| 25| | 3|Park| 40| +---+----+---+각 단계의 연결 상황 확인: Python 🡲 PySpark 🡲 Spark Driver 🡲 Spark Cluster
- 5단계 : SQL 기능 확인
- Spark는 SQL 엔진도 포함함
#//file: "test_sql.py" from pyspark.sql import SparkSession spark = ( SparkSession.builder .appName("SQL Test") .master("spark://spark-master:7077") .getOrCreate() ) data = [ (1, "Kim", 30), (2, "Lee", 25), (3, "Park", 40) ] df = spark.createDataFrame( data, ["id", "name", "age"] ) df.createOrReplaceTempView("people") result = spark.sql(""" SELECT * FROM people WHERE age >= 30 """) result.show() spark.stop()결과
+---+----+---+ | id|name|age| +---+----+---+ | 1| Kim| 30| | 3|Park| 40| +---+----+---+확인할 것: 다음 모듈의 정상적인 동작여부
Spark SQL Engine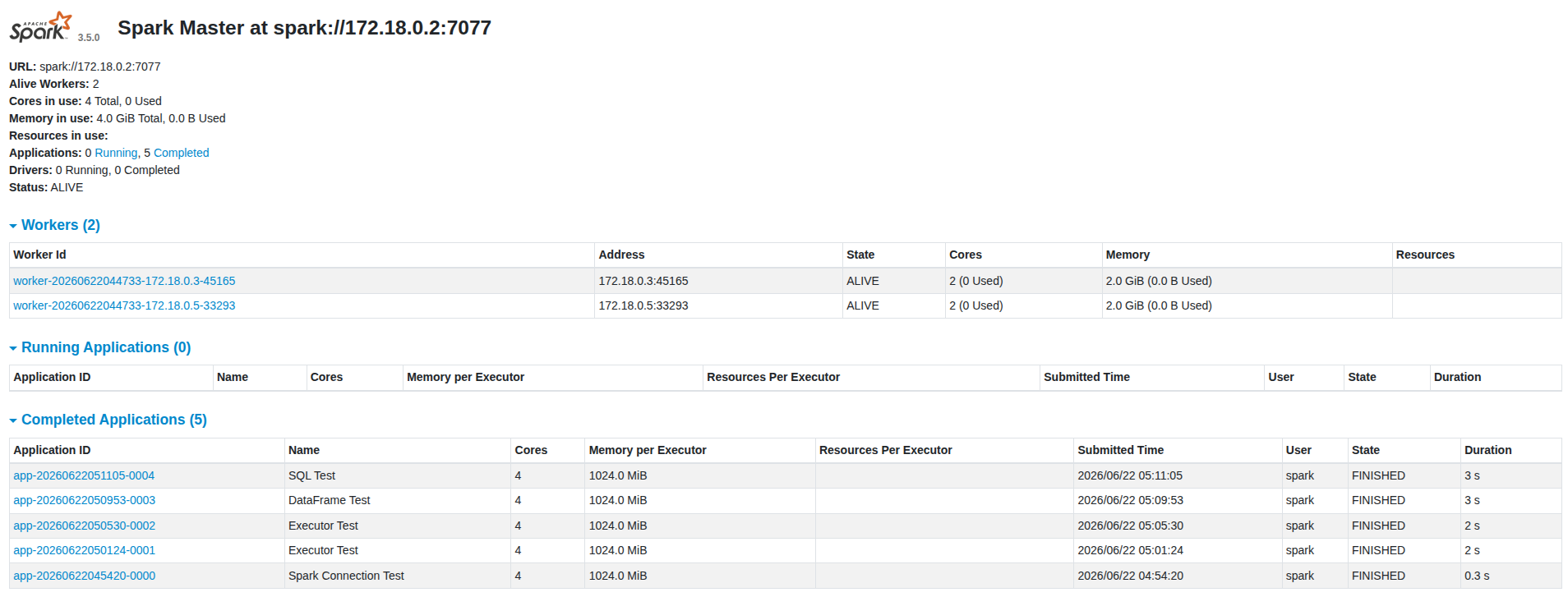
- 6단계 : Worker 분산 처리 확인
- 중요한 예제
#//file: "test_parallel.py" from pyspark.sql import SparkSession spark = ( SparkSession.builder .appName("Parallel Test") .master("spark://spark-master:7077") .getOrCreate() ) sc = spark.sparkContext rdd = sc.parallelize(range(10000000), 8) result = rdd.sum() print("SUM =", result) spark.stop()설명: 다음 코드의 의미는
1천만개 데이터, 8개 Partition의 생성rdd = sc.parallelize( range(10000000), 8 )확인할 것
- http://localhost:8080 에서 Application 클릭
평상시의 경우
Worker-1 Worker-2양쪽에 Task가 분산됨 경우
클러스터 동작 확인
- http://localhost:8080 에서 Application 클릭
- 7단계 : CSV 파일 읽기
- 실무에서 가장 많이 하는 작업
- 파일명: data/employee.csv
id,name,salary 1,Kim,5000 2,Lee,7000 3,Park,9000#//file: "test_csv.py" from pyspark.sql import SparkSession spark = ( SparkSession.builder .appName("CSV Test") .master("spark://spark-master:7077") .getOrCreate() ) df = ( spark.read .option("header", True) .csv("/workspace/data/employee.csv") ) df.show() spark.stop() - 실행하면 파일을 찾을 수 없다는 메시지가 나올 것
- 이유는 spark-client는 Host와 저장소가 마운트 되어 있으나, worker 들은 마운트 되어 있지 않아서임
docker-compose.yml 수정
spark-worker-1: image: apache/spark:3.5.0 volumes: - ./:/workspace spark-worker-1: image: apache/spark:3.5.0 volumes: - ./:/workspacedocker compose down docker compose up -d --build docker exec -it spark-worker-2 bash ls /workspace/data- 결과
employee.csv- 계속 실행
docker exec -it spark-client bash python test_csv.py- 예상 결과
+---+----+------+ | id|name|salary| +---+----+------+ | 1| Kim| 5000| | 2| Lee| 7000| | 3|Park| 9000| +---+----+------+- Spark 학습에서 매우 중요한 포인트
- 실무에서 가장 많이 하는 작업
- 8단계 : 집계(Aggregation)
- Spark를 사용하는 가장 큰 이유
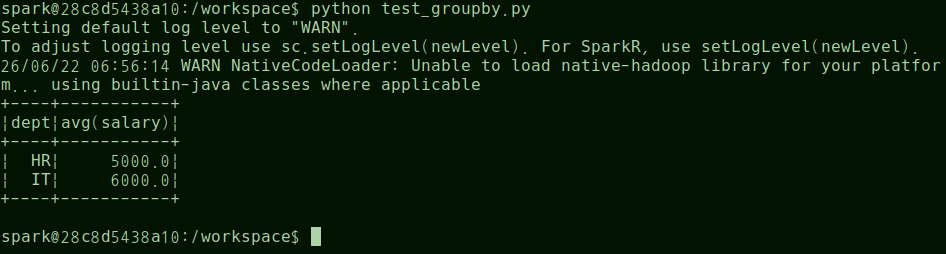
#//file: "test_groupby.py" from pyspark.sql import SparkSession from pyspark.sql.functions import avg spark = ( SparkSession.builder .appName("Group By Test") .master("spark://spark-master:7077") .getOrCreate() ) data = [ ("IT", 5000), ("IT", 7000), ("HR", 4000), ("HR", 6000) ] df = spark.createDataFrame( data, ["dept", "salary"] ) result = ( df.groupBy("dept") .agg(avg("salary")) ) result.show() spark.stop()결과
+----+-----------+ |dept|avg(salary)| +----+-----------+ | IT | 6000.0 | | HR | 5000.0 | +----+-----------+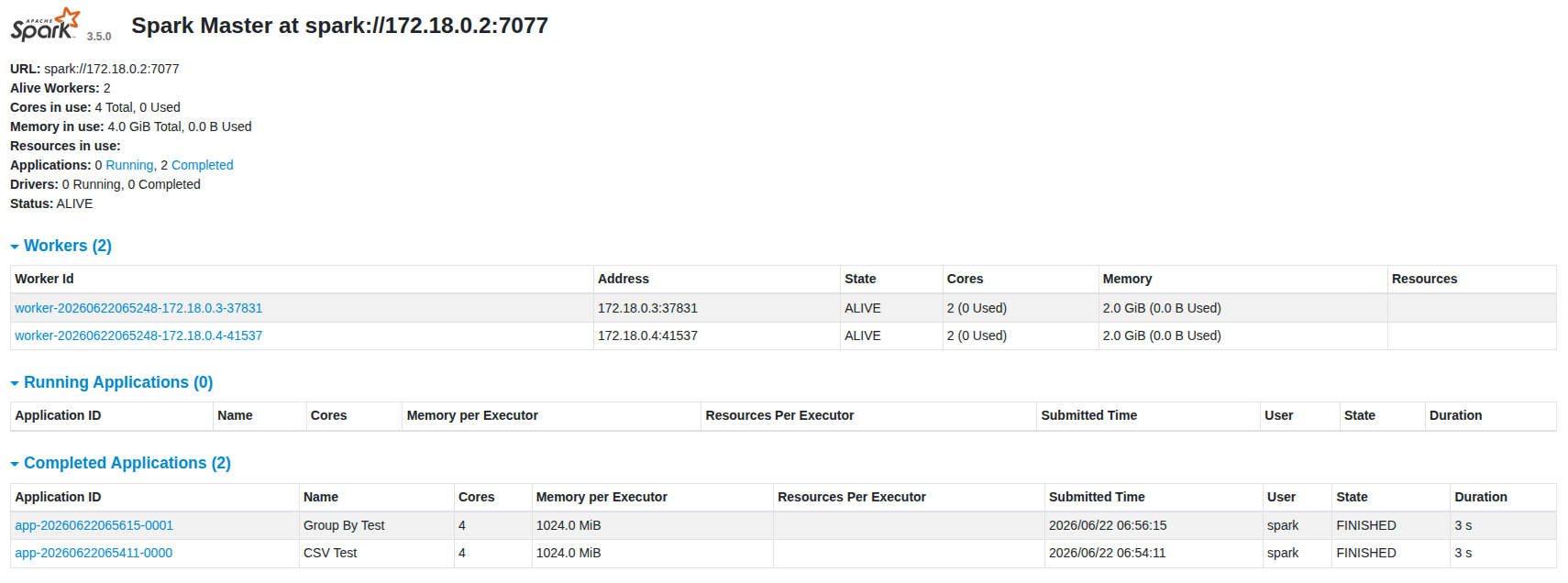
- 9단계 : Parquet 사용 예제
- Spark에서는 다음 이유로 CSV보다 Parquet을 훨씬 많이 사용함
- 컬럼형(Columnar) 저장
- 압축 효율 우수
- 필요한 컬럼만 읽음
- 스키마 저장
- Spark 최적화 지원
- 대용량 데이터 처리 속도 우수
- 실무에서는 CSV 🡲 Spark 적재 🡲 Parquet 저장 🡲 분석 흐름이 가장 일반적
#//file: "test_parquet_write.py" from pyspark.sql import SparkSession spark = ( SparkSession.builder .appName("Parquet Write") .master("spark://spark-master:7077") .getOrCreate() ) data = [ (1, "Kim", 5000), (2, "Lee", 7000), (3, "Park", 9000) ] df = spark.createDataFrame( data, ["id", "name", "salary"] ) df.show() df.write.mode("overwrite").parquet( "/workspace/data/parquet/employee" ) spark.stop()앞에서의 문제와 마찬가지로 client, worker에 ./data:/workspace/data의 경로를 추가해야 함
```yaml spark-worker-1: volumes: - ./data:/workspace/data ... spark-worker-2: volumes: - ./data:/workspace/data ... spark-client: volumes: - ./data:/workspace/data ... ``` ```bash docker exec -it spark-client bash ``` ```bash python test_parquet_write.py ```그런데 추가해 주어도 오류가 발생할 것임 🡲 client와 worker의 계정이 다름
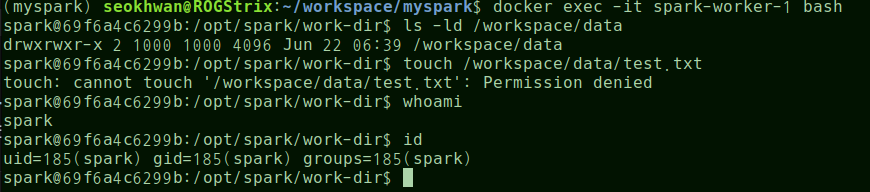
- 애초에 Local 시스템을 대상으로 만들어진 것이 아니어서 이런 권한문제가 발생함
- 대규모 운영(실제 기업 환경) 시에는 로컬 디스크 공유를 아예 하지 않음
일단, 실습을 위한 해결 방안
cd ~/workspace/myspark sudo chown -R 185:185 data- 또는
cd ~/workspace/myspark sudo chmod -R 777 data
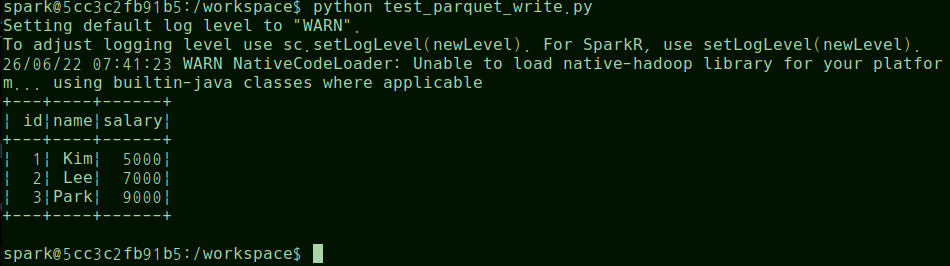
- 참고: 컨테이너의 이미지에 따라 사용자 설정방식이 모두 다름
- Bitnami Spark 인가?
- Apache Spark 공식 이미지인가? 🡲 현재의 이미지는 공식 이미지
- 직접 만든 Dockerfile 인가?
- 애초에 Local 시스템을 대상으로 만들어진 것이 아니어서 이런 권한문제가 발생함
- Spark에서는 다음 이유로 CSV보다 Parquet을 훨씬 많이 사용함
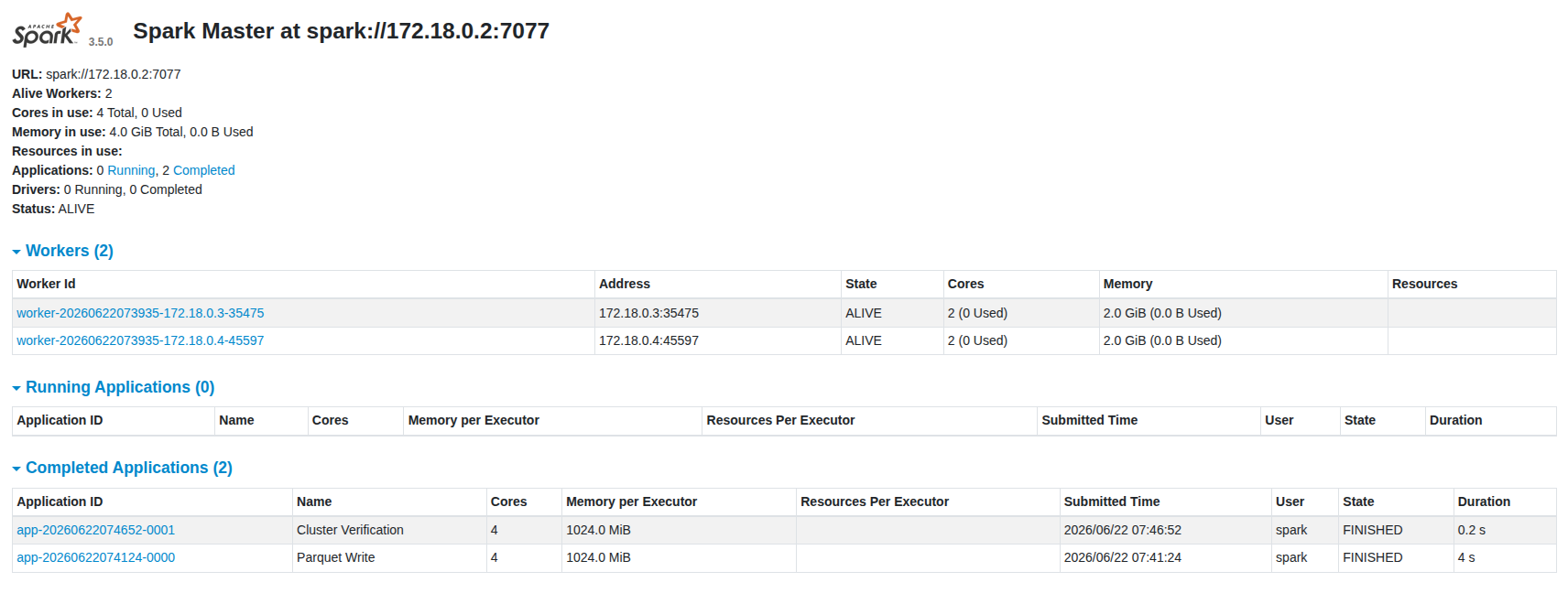
- 10단계 : 실제 클러스터 검증용 예제
- Spark가 Worker를 사용하는지 확인
from pyspark.sql import SparkSession spark = ( SparkSession.builder .appName("Cluster Verification") .master("spark://spark-master:7077") .getOrCreate() ) sc = spark.sparkContext print( "Default Parallelism =", sc.defaultParallelism ) print( "Executors =", sc._jsc.sc().getExecutorMemoryStatus().size() ) spark.stop()예상
Default Parallelism = 4 Executors = 3보통은 다음이 보임
Driver Worker1 Worker2

- Spark 학습 시 추천 순서
- Connection Test 🡲 DataFrame 생성 🡲 Spark SQL 🡲 Parallel Processing 🡲 CSV 읽기 🡲 GroupBy/Aggregation 🡲 Parquet 저장 🡲 MinIO 연결 🡲 🡲 Trino 조회
- 특히 4단계(Parallel Test) 는 꼭 실행해 볼 것을 추천
- 단순히 Spark가 실행되는 것이 아니라, 현재 구성한 Worker 2대가 실제로 분산 작업에 참여하는지 확인할 수 있기 때문
- 이 단계가 통과되면 Spark 클러스터 자체는 정상이라고 볼 수 있음
2.2 독립형 Spark 분산 클러스터 연동 실습
- PySpark 가동을 위한 사전 준비
- 호스트 PC:
myspark가상환경 생성 및 활성화 필수 라이브러리를 설치
pip install pyspark pandas
- 호스트 PC:
예제 코드
#//file: "spark_verify.py" import sys from pyspark.sql import SparkSession from pyspark.sql.functions import avg, count def create_spark_session(): """ Standalone Spark Cluster 연결 """ return ( SparkSession.builder .appName("Factory_Sensor_Verification") .master("spark://spark-master:7077") .config("spark.sql.shuffle.partitions", "4") .getOrCreate() ) def main(): print("\n[START] Spark Standalone Cluster Verification") print("=" * 70) # -------------------------------------------------- # 1. Spark 연결 # -------------------------------------------------- try: spark = create_spark_session() print("\n[SUCCESS] Spark Session Connected") print(f"Application ID : {spark.sparkContext.applicationId}") print(f"Master : {spark.sparkContext.master}") print(f"Spark Version : {spark.version}") except Exception as e: print("\n[CRITICAL ERROR] Spark 연결 실패") print(e) sys.exit(1) # -------------------------------------------------- # 2. 테스트 데이터 # -------------------------------------------------- raw_factory_data = [ (101, "Line_A", 72.5, "NORMAL"), (102, "Line_B", 88.1, "WARN"), (103, "Line_A", 69.8, "NORMAL"), (104, "Line_A", 74.2, "NORMAL"), (105, "Line_B", 82.3, "NORMAL"), (106, "Line_B", 91.0, "CRITICAL") ] column_names = [ "device_id", "location", "temperature", "status" ] # -------------------------------------------------- # 3. DataFrame 생성 # -------------------------------------------------- dist_df = spark.createDataFrame( raw_factory_data, schema=column_names ) print("\n[원본 데이터]") dist_df.show(truncate=False) print("\n[파티션 정보]") print( f"Partition Count : " f"{dist_df.rdd.getNumPartitions()}" ) # -------------------------------------------------- # 4. 분산 집계 # -------------------------------------------------- print("\n[분산 집계 수행]") analysis_df = ( dist_df .groupBy("location") .agg( avg("temperature").alias("avg_temp"), count("device_id").alias("total_sensors") ) .orderBy("location") ) # -------------------------------------------------- # 5. 결과 확인 # -------------------------------------------------- print("\n" + "-" * 70) print("[집계 결과]") print("-" * 70) analysis_df.show(truncate=False) # -------------------------------------------------- # 6. Pandas 변환 # -------------------------------------------------- pandas_df = analysis_df.toPandas() print("\n[Pandas 변환 성공]") print(type(pandas_df)) print("\nPandas DataFrame:") print(pandas_df) # -------------------------------------------------- # 7. Executor 확인 # -------------------------------------------------- print("\n[Executor 정보]") executor_infos = spark.sparkContext.statusTracker() print( f"Default Parallelism : " f"{spark.sparkContext.defaultParallelism}" ) # -------------------------------------------------- # 종료 # -------------------------------------------------- spark.stop() print("\n[FINISH] Spark Verification Completed") print("=" * 70) if __name__ == "__main__": main()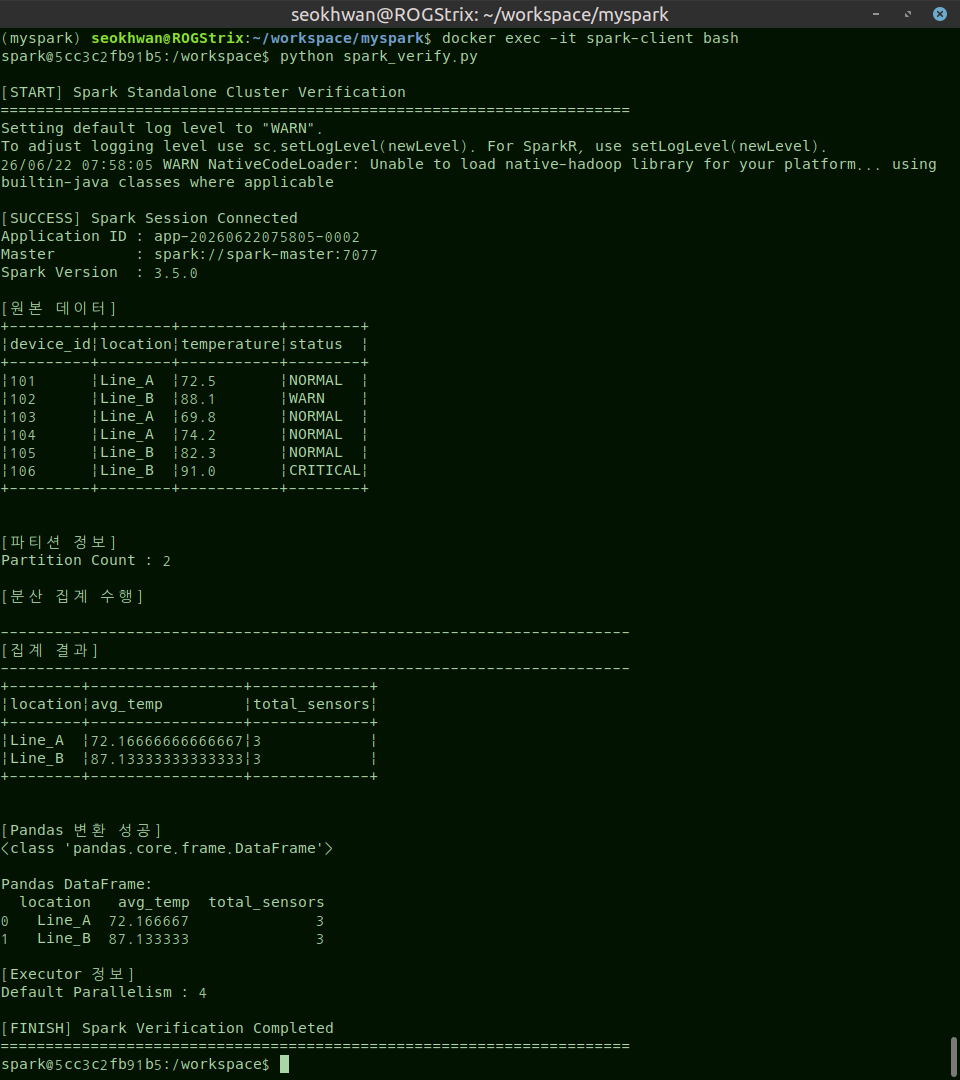
- 예제 코드 상세 설명
- Spark Standalone Cluster의 기본 동작 원리 이해하기
전체 구조
Host PC │ ├─ spark-client │ └─ spark_verify.py 실행 │ ├─ spark-master │ └─ 작업 스케줄링 │ ├─ spark-worker-1 │ └─ Executor 실행 │ └─ spark-worker-2 └─ Executor 실행1단계 : SparkSession 생성
spark = ( SparkSession.builder .appName("Factory_Sensor_Verification") .master("spark://spark-master:7077") .config("spark.sql.shuffle.partitions", "4") .getOrCreate() )- SparkSession이란?
- Spark의 진입점(Entry Point)
- 예전에는 SparkContext, SQLContext, HiveContext를 따로 만들었지만 Spark 2.x 이후부터는 SparkSession 하나만 사용함
- Spark의 진입점(Entry Point)
appName(): Master UI에 표시됨
.appName("Factory_Sensor_Verification")Running Applications Factory_Sensor_Verificationmaster(): 여기가 가장 중요
.master("spark://spark-master:7077")기존에 사용했던 코드
.master("spark://localhost:7077")- spark-client 컨테이너 내부의 localhost를 의미함
- 즉 spark-client 🡲 spark-client을 가리킴
현재의 코드는 Docker Compose 네트워크 DNS를 사용함
.master("spark://spark-master:7077")- spark-client 🡲 spark-master (정상 연결)
shuffle partition: 4개의 파티션
.config("spark.sql.shuffle.partitions", "4")
- SparkSession이란?
2단계 : 원본 데이터 생성
raw_factory_data = [ (101, "Line_A", 72.5, "NORMAL"), ... ]- 이 데이터는 현재 Python 메모리에 존재함 🡲 아직 Spark가 아님 🡲 Python List 일 뿐
3단계 : DataFrame 생성
dist_df = spark.createDataFrame( raw_factory_data, schema=column_names )- 이 순간 발생하는 일
- Python 객체 🡲 Spark DataFrame 🡲 RDD 생성 🡲 파티션 분할
Spark 입장에서는 device_id, location, temperature, status 를 가진 분산 데이터셋이 생성됨
- Lazy Evaluation
- 여기서 매우 중요한 개념
Spark는 아직 계산하지 않음
dist_df = ...- 실행 계획만 작성한 상태입니다.
예를 들어
df.filter(...) .groupBy(...) .agg(...)- 를 100개 써도 Spark는 계산 안 함
실제 계산은
show() collect() count() toPandas()- 같은 Action이 호출될 때 시작됨
- 이 순간 발생하는 일
4단계 : 원본 데이터 출력
dist_df.show()- 여기서 최초 Action 발생
- Spark 내부
- Driver 🡲 Master 🡲 Worker
- 실제 실행
- Task 생성 🡲 Worker 전송 🡲 Executor 실행 🡲 결과 반환
파티션 확인
dist_df.rdd.getNumPartitions()- 예시
Partition Count : 4 라면 실제로는 다음과 같이 데이터가 분할된 상태
Partition 1 Partition 2 Partition 3 Partition 4
- Spark의 핵심: 파티션 단위로 병렬처리
- 예시
5단계 : 집계 연산
analysis_df = ( dist_df .groupBy("location") .agg( avg("temperature").alias("avg_temp"), count("device_id").alias("total_sensors") ) )결과
Line_A Line_B- 라인 별로 집계
SQL로 표현하면
SELECT location, AVG(temperature), COUNT(device_id) FROM sensor GROUP BY location
- 내부에서 발생하는 일
- Spark는 실행계획(DAG)을 만듦: Raw Data 🡲 Group By 🡲 Aggregate
실행계획은 확인 가능
analysis_df.explain(True)실제로는 다음의 일이 발생함
Worker-1 일부 데이터 처리 Worker-2 일부 데이터 처리 🡳 Shuffle 🡳 최종 집계
- Spark는 실행계획(DAG)을 만듦: Raw Data 🡲 Group By 🡲 Aggregate
- Shuffle
- Spark에서 가장 비싼 작업
groupBy(), join(), distinct()는 모두 Shuffle을 유발함
- 예시
- Line_A 데이터, Line_B 데이터가 여러 Worker에 흩어져 있다면, 집계하려고 네트워크 이동이 발생
- 그래서 groupBy, join, orderBy는 Spark 튜닝의 핵심
6단계 : 결과 출력
analysis_df.show()- 여기서 실제 집계가 실행됨
예상 결과
+--------+--------+-------------+ |location|avg_temp|total_sensors| +--------+--------+-------------+ |Line_A |72.17 |3 | |Line_B |87.13 |3 | +--------+--------+-------------+
7단계 : Pandas 변환
pandas_df = analysis_df.toPandas()- 중요: Spark 🡲 Pandas 변환은 분산환경 🡲 단일머신으로 바꾸는 것
- 즉, Worker-1, Worker-2, Worker-3에 있던 데이터를 Driver 메모리로 모두 가져옴
- 현재 데이터는 2행이라 안전하지만 1억 행이라면 toPandas() 실행하다가 메모리 폭발 발생
실무에서는 다음을 실행한 후 사용함
limit() sample()
8단계 : Executor 확인
spark.sparkContext.defaultParallelism만약 4가 출력되었다면 현재 클러스터는
worker-1 cores=2 worker-2 cores=2- 이므로 총 4코어를 의미함
- 즉, 4개의 Task를 동시에 처리 가능
9단계 : spark.stop()
spark.stop()- 중요함
- 실행 전: Driver, Executor, Application을 생성
- 실행 후: spark.stop()을 실행하면 Application 종료, Executor 해제, 메모리 반납 발생
- Master UI에서도 “Running Applications”목 록에서 사라짐
- 중요함
이 코드가 실제로 검증하는 것
- Docker 네트워크
- spark-client 🡰🡲 spark-master
- Spark Master 등록
- spark://spark-master:7077 연결 확인
- Worker 등록
- worker-1, worker-2 사용 가능 여부 확인
- Driver 생성
- spark_verify.py가 Driver 역할 수행
- Executor 생성
- worker JVM에서 Task 수행
- Pandas 연계
- Spark 🡲 Pandas 변환 검증
- Docker 네트워크