Spark 분산 아키텍처 구조
1. Apache Spark의 분산 아키텍처 구조
- Apache Spark는
- 클러스터라는 거대한 하나의 컴퓨터 자원을 효율적으로 쪼개어 대규모 데이터를 병렬로 처리하기 위한 핵심 메커니즘이자 솔루션
- 기본적으로 Master-Worker(마스터-워커) 형태의 마스터 슬레이브 구조를 따름
1.1 Master-Worker (M-W) 구조
- 대규모 데이터 처리를 효율적으로 분담하기 위해 역할을
- 지휘 및 자원 관리(Master)와 실제 연산 수행(Worker)으로 이원화한
분산 시스템의 전형적인 주종(Master-Slave) 아키텍처
- 마스터 노드 (Master Node / Cluster Manager)
- 클러스터 전체의 자원을 관리하고 모니터링하는 ‘총괄 관리자’
- Spark Standalone 모드의 경우
- Spark 자체 마스터 프로세스가 이 역할을 수행
- Kubernetes나 YARN 환경의 경우
- 각 시스템의 자원 스케줄러가 역할을 대신함
- Spark Standalone 모드의 경우
- 역할
- 자원 상태 모니터링:
- 어떤 워커 노드가 살아있는지, 각 워커의 남은 CPU 코어와 메모리(RAM)가 얼마인지 실시간으로 체크
- 익스큐터 할당:
- 새로운 Spark 애플리케이션(작업)이 제출되면,
- 마스터는 사용 가능한 워커 노드를 선별하여
- 연산을 수행할 컨테이너(익스큐터)를 띄우도록 명령
- 주의점:
- 마스터 노드는 자원 분배와 스케줄링만 담당
- 사용자가 작성한 실제 연산 코드(소스코드)를 실행하거나 데이터 파티션을 가공하는 일은 하지 않음
- 자원 상태 모니터링:
- 클러스터 전체의 자원을 관리하고 모니터링하는 ‘총괄 관리자’
- 워커 노드 (Worker Node)
- 실제 데이터 연산 능력을 가진 물리 서버 또는 가상 머신(컨테이너)인 ‘물리적/논리적 공간’
- 마스터의 명령을 받아 자신의 자원(CPU, RAM)을 제공
- 내부에서 하나 이상의 익스큐터(Executor) 프로세스를 구동함
- 실제 데이터 연산 능력을 가진 물리 서버 또는 가상 머신(컨테이너)인 ‘물리적/논리적 공간’
- 익스큐터 (Executor)
- 워커 노드 내부에서 격리되어 실행되는 실제 ‘연산 프로세스’
- 태스크(Task) 실행:
- 드라이버(Driver) 프로그램으로부터 전달받은 실제 연산 단위(태스크)를 스레드 방식으로 병렬 실행
- 인메모리 저장소:
- 연산 도중 생성되는 중간 데이터나 캐시(Cache) 데이터를 메모리에 보관하여 디스크 I/O를 최소화
- 태스크(Task) 실행:
- 워커 노드 내부에서 격리되어 실행되는 실제 ‘연산 프로세스’
1.2 작업의 전체 흐름 (Lifecycle)
- 마스터-워커 구조를 온전히 이해하려면 사용자의 애플리케이션이 실행되는 과정에서의 상호작용을 보아야 함
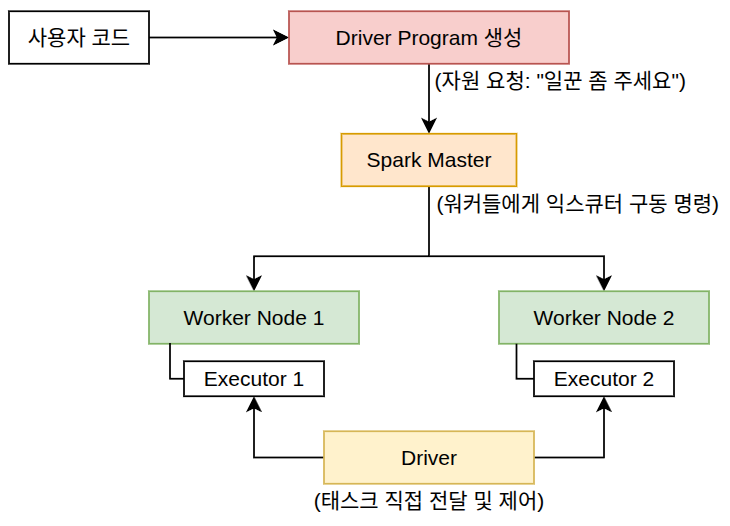
프로세스 순서에 따른 작동 흐름 (Lifecycle)
- [1단계] 애플리케이션 시작 및 자원 할당 (초기화 단계)
- 작업 제출:
- 개발자가 코드 실행 🡲 드라이버 프로그램 구동 🡲 내부에서
SparkContext활성화
- 개발자가 코드 실행 🡲 드라이버 프로그램 구동 🡲 내부에서
- 자원 요청 (작업 제출 화살표):
- 드라이버는 클러스터 매니저에게 “이 프로그램을 돌려야 하니 연산을 수행할 일꾼(익스큐터) 자원을 달라”고 요청
- 익스큐터 구동:
- 클러스터 매니저는 워커 노드들의 상태 확인 🡲 워커 노드들에게 명령하여 실제 연산 수행 익스큐터 프로세스들 구동
- 작업 제출:
- [2단계] 최적화 및 태스크 분배 (스케줄링 단계)
- DAG 및 태스크 생성:
- 코드가 실행되다가 최종 결과 출력 명령(Action)을 만나면 🡲 드라이버 내의 DAG 생성기가 최적의 실행 계획 그래프를 그림
- 태스크 생성기는 이 그래프를 바탕으로 분산 처리할 수 있는 수많은 태스크(Task)로 분할
- 태스크 배분 (태스크 분배 화살표):
- 드라이버는 익스큐터들에게 태스크를 직접 분배
- 데이터 지역성(Data Locality) 원리에 따라 🡲 데이터 파티션이 위치한 곳과 가장 가까운 워커 노드의 익스큐터에게 태스크 우선 배정
- DAG 및 태스크 생성:
- [3단계] 병렬 연산 및 데이터 셔플 (실행 단계)
- 로컬 연산:
- 각 워커 노드의 익스큐터들은 배정받은 태스크를 내부 병렬 스레드를 통해 빠르게 처리
- 필요한 데이터는 외부 분산 스토리지에서 파티션 단위로 읽어와 메모리 저장소에 올린 뒤 연산
- 데이터 셔플 및 네트워크 통신:
- 그림 중앙에 표현된 워커 노드 간의 좌우 화살표
GroupBy나Join처럼 데이터를 재정렬해야 하는 연산이 발생하면,- 워커 노드들은 서로의 데이터를 네트워크를 통해 교환하는 데이터 셔플(Shuffle)을 수행
- 이 과정에서 필요한 경우 로컬 디스크를 임시 활용함
- 로컬 연산:
- [4단계] 결과 보고 및 취합 (종료 단계)
- 결과 보고:
- 모든 태스크 연산 완료 🡲 익스큐터들은 최종 계산된 부분 결과물들을 드라이버 프로그램에게 전송 (실행 결과 보고 화살표)
- 최종 집계 및 자원 반납:
- 드라이버는 워커들이 보내온 결과를 하나로 합쳐서 사용자 화면에 띄우거나 외부 분산 스토리지에 최종 저장
- 작업이 모두 완료되면 클러스터 매니저는 가동했던 익스큐터들을 종료하고 자원을 다시 회수함
- 결과 보고:
- [1단계] 애플리케이션 시작 및 자원 할당 (초기화 단계)
1.3 각 핵심 모듈별 상세 역할
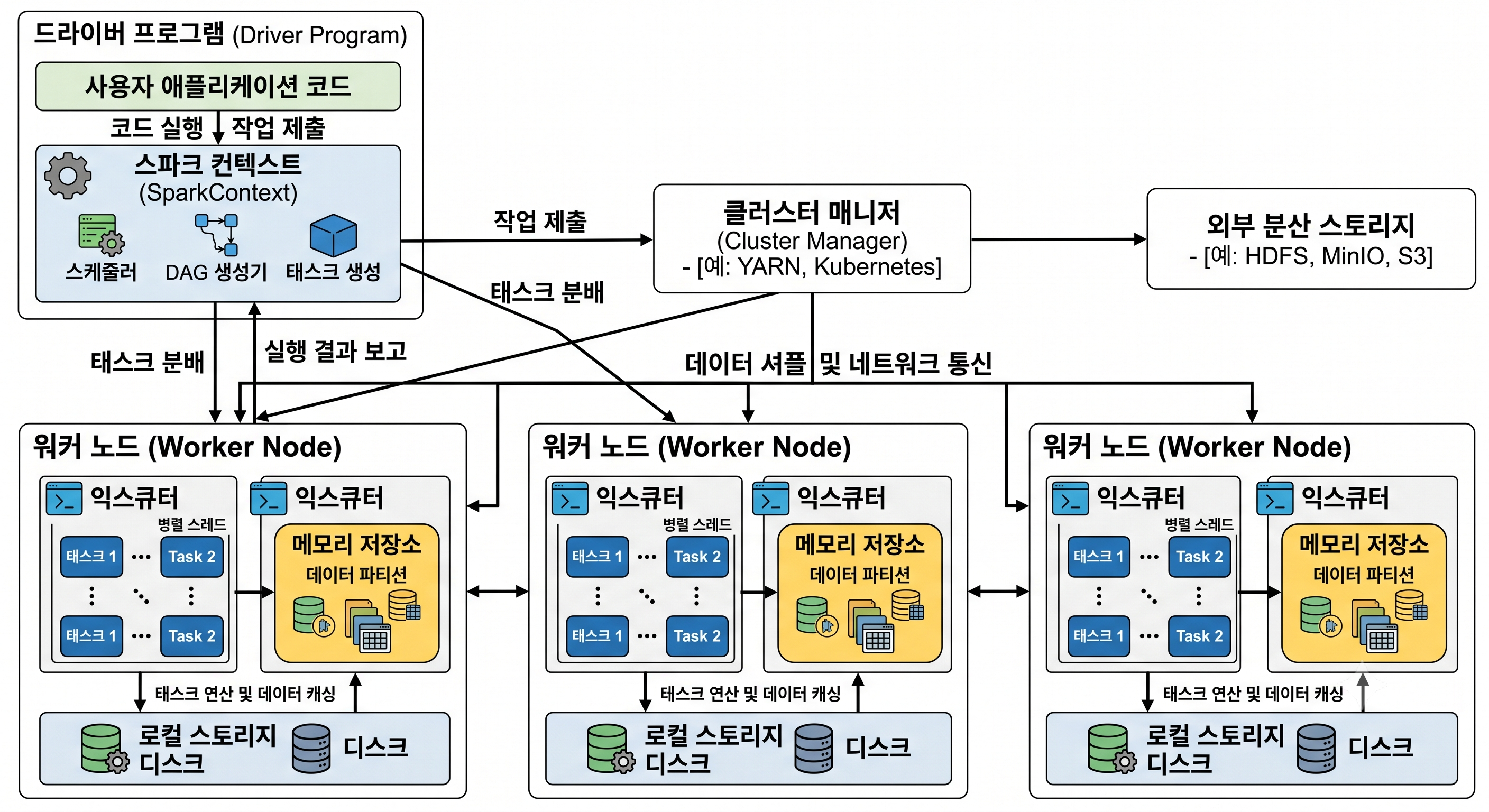
- 드라이버 프로그램 (Driver Program)
- 그림 좌측 상단에 위치한 영역
- 주요 역할
- 사용자가 작성한 Spark 애플리케이션 코드가 실행되는 중앙 컨트롤러이자 클러스터 전체의 ‘두뇌(Brain)’
- 코드 실행 및 분석:
- 개발자가 작성한 고수준 코드(SQL, DataFrame API 등)를 읽어 분산 실행이 가능한 물리적 연산 형태로 해석
- 중앙 집중식 스케줄링:
- 전체 작업의 흐름을 통제하고, 작업을 쪼개어 클러스터 매니저를 통해 워커 노드로 분배
- 결과 수집 및 반환:
- 각 워커 노드에서 연산된 부분 결과물들을 최종적으로 모아서(Action 연산 시) 사용자에게 보여주거나 파일로 저장
- 코드 실행 및 분석:
- 사용자가 작성한 Spark 애플리케이션 코드가 실행되는 중앙 컨트롤러이자 클러스터 전체의 ‘두뇌(Brain)’
- 내부 핵심 구성 요소
- 드라이버 프로그램 내부는 크게 SparkSession(과거의 SparkContext)을 중심으로 다음 3가지 핵심 모듈이 맞물려 작동
- DAG 스케줄러 (DAGScheduler):
- 사용자의 코드가 실행 경로를 구성할 때,
- 데이터의 흐름과 의존성 관계를 논리적인 그래프인 DAG(Directed Acyclic Graph) 형태로 변환
- 이 DAG를 바탕으로 계산한 셔플(Shuffle) 발생 여부를 기준으로 삼아
- 작업을 몇 개의 큰 단계인 스테이지(Stage)로 분할
- 태스크 스케줄러 (TaskScheduler):
- DAG 스케줄러가 쪼개놓은 스테이지(Stage)를 받아,
- 데이터 파티션 수만큼의 실제 최소 실행 단위인 태스크(Task)들을 생성
- 이 태스크들을 어떤 워커 노드에 던질지 최종 결정하는 실무 스케줄링을 담당
- 스케줄러 백엔드 (SchedulerBackend):
- 클러스터 매니저(YARN, Kubernetes 등)와 직접 통신
- 워커 노드의 자원(익스큐터) 상태를 실시간으로 확인
- 태스크를 실제로 전송하는 통신 창구 역할 수행
- DAG 스케줄러 (DAGScheduler):
- Spark 아키텍처가 효율적인 이유는 코드가 실행되는 방식에 있음
- DAG (Directed Acyclic Graph):
- 드라이버는 코드를 만날 때마다 즉시 실행하지 않고,
- 데이터가 어떻게 변환되어 가는지에 대한 연산 계보(Lineage) 그래프를 그림
- 이를 통해 쿼리를 최적화할 공간을 확보함
- 지연 연산 (Lazy Evaluation):
- 데이터를 변환하는 작업(
map,filter등 / Transformation)은 기록만 해두고 실행을 미룸 - 최종 결과를 출력하거나 저장하라는 명령(
count,collect,save등 / Action)을 만나는 순간, - 쌓아둔 DAG를 바탕으로 최적의 경로를 계산해 한 번에 실행
- 데이터를 변환하는 작업(
- DAG (Directed Acyclic Graph):
- 드라이버 프로그램 내부는 크게 SparkSession(과거의 SparkContext)을 중심으로 다음 3가지 핵심 모듈이 맞물려 작동
- 작업 프로세스
사용자가 코드를 제출한 순간부터 종료될 때까지 드라이버 프로그램이 수행하는 단계별 흐름
- 1단계: 애플리케이션 초기화 (Initialization)
- 드라이버가 구동되면서 SparkSession 객체를 생성
- 클러스터 매니저에게 연락
- “이 작업을 수행할 일꾼(Executor)들을 워커 노드에 띄워달라”고 요청 🡲 연산 공간을 확보
- 2단계: DAG 빌드 (Logical Planning)
- map, filter 같은 변환(Transformation) 명령들이 실행될 때,
- 드라이버는 데이터를 즉시 계산하지 않고 DAG 스케줄러를 통해 논리적인 연산 계보(Lineage) 그래프만 그리며 대기 (지연 연산)
- 3단계: 스테이지 분할 (Physical Planning)
- count, collect, save 같은 최종 결과 출력 명령(Action)을 만나는 순간 연산이 트리거됨
- DAG 스케줄러가 작동하여 전체 그래프를 분석
- 네트워크 데이터 교환(Shuffle)이 필요한 지점을 기준으로 스테이지(Stage)들을 분할
- 4단계: 태스크 스케줄링 및 분배 (Task Scheduling)
- 태스크 스케줄러가 각 스테이지를 파티션 단위의 개별 태스크(Task)로 분할
- 데이터가 위치한 워커 노드로 태스크 전달
- 네트워크 비용을 최소화하는 데이터 지역성(Data Locality) 전략 적용
- 스케줄러 백엔드를 통해 각 워커의 익스큐터로 태스크 전달
- 5단계: 결과 수집 및 정리 (Result Collection & Shutdown)
- 워커 노드들로부터 각 태스크의 실행 결과를 실시간으로 보고받음
- 모든 결과가 수집되면 드라이버가 이를 최종 취합
- 사용자에게 반환하거나 외부 스토리지(MinIO, S3 등)에 저장
- 할당받았던 클러스터 자원을 반납
- 프로세스를 안전하게 종료
- 클러스터 매니저 (Cluster Manager)
- 그림 중앙 상단에 위치
- 주요 역할
- 수많은 워커 노드(서버)들로 구성된 클러스터 환경에서 하드웨어 자원(CPU Cores, Memory)을 중앙 집중식으로 관리하고 분배하는 자원 관리 시스템
- 자원 추상화 및 모니터링:
- 여러 대의 서버 자원을 하나의 거대한 자원 풀(Pool)로 묶어서 관리
- 어떤 워커 노드가 살아있고 자원 여유가 얼마나 있는지 실시간으로 감시
- 익스큐터 할당 및 구동:
- 드라이버 프로그램이 자원을 요청하면,
- 클러스터 내 최적의 워커 노드를 선정 🡲 실제 연산 프로세스인 익스큐터(Executor)를 실행시킴
- 다중 사용자(Multi-tenant) 지원:
- 한 클러스터 내에서 여러 명의 개발자나 여러 개의 Spark 애플리케이션이 동시에 실행될 때,
- 자원이 충돌하지 않도록 격리, 배분
- 자원 추상화 및 모니터링:
- 수많은 워커 노드(서버)들로 구성된 클러스터 환경에서 하드웨어 자원(CPU Cores, Memory)을 중앙 집중식으로 관리하고 분배하는 자원 관리 시스템
- 주요 종류 및 구성 요소
- Spark는 플러그인 형태로 다양한 클러스터 매니저를 지원함
- 실무에서 사용하는 종류에 따라 내부 구성 요소가 조금씩 다름
- Spark Standalone (기본 내장 매니저):
- Spark에 기본 내장된 매니저
- 외부 시스템 없이 바로 클러스터를 구성할 때 사용
- 구성 요소:
- 중앙의 Master 프로세스
- 각 서버의 자원을 대변하는 Worker 프로세스
- Hadoop YARN (전통적 기업 환경):
- 하둡 생태계에서 가장 널리 쓰이는 자원 관리자
- 구성 요소:
- 클러스터 전체 자원을 관리하는 리소스 매니저(ResourceManager)
- 각 서버의 자원을 관리하는 노드 매니저(NodeManager)
- Kubernetes (현대적 클라우드 네이티브):
- 최근 가장 대세인 컨테이너 기반 자원 관리자
- 구성 요소:
- Kubernetes(=K8s) 핵심인 마스터 API 서버
- 자원 제어 도구인 오퍼레이터(Operator)
- 두 요소를 통해 Spark 익스큐터들을 도커 컨테이너(Pod) 형태로 동적으로 띄우고 내림
- Spark Standalone (기본 내장 매니저):
- 작업 프로세스
드라이버 프로그램과 워커 노드 사이에서 클러스터 매니저가 자원을 조율하는 단계별 흐름
- 1단계: 상시 자원 모니터링 (Resource Monitoring)
- 평상시 각 워커 노드들로부터 주기적인 신호(Heartbeat)를 받으며
- 가동 상태와 잔여 CPU, 메모리 용량을 실시간으로 집계함
- 2단계: 자원 요청 접수 (Resource Request)
- 사용자가 제출한 Spark 드라이버 프로그램이 켜지면서
- 클러스터 매니저에게 정해진 스펙(예: 익스큐터당 CPU 2개, 메모리 4GB씩 총 4대 필요)으로 자원을 요청
- 3단계: 스케줄링 및 노드 선정 (Scheduling)
- 요청받은 스펙을 충족할 수 있는 워커 노드들을
- 내부 알고리즘(FIFO, Fair, Capacity 스케줄링 등)에 따라 선별하고 배치 계획을 세움
- 4단계: 익스큐터 구동 (Executor Launching)
- 선별된 워커 노드의 관리 프로세스(Standalone의 Worker 데몬, YARN의 NodeManager 등)에게 명령을 내려,
- 지정된 자원 크기만큼의 익스큐터(Executor) 프로세스를 즉시 구동시킴
- 익스큐터가 정상 작동하면
- 클러스터 매니저의 개입은 잠시 줄어들고,
- 드라이버와 익스큐터가 직접 소통하기 시작
- 선별된 워커 노드의 관리 프로세스(Standalone의 Worker 데몬, YARN의 NodeManager 등)에게 명령을 내려,
- 5단계: 자원 복구 및 회수 (Resource Reclamation)
- 연산 도중 특정 워커 노드가 고장 나면
- 클러스터 매니저가 이를 감지하여 드라이버에게 알리고 새로운 대체 자원을 할당
- 모든 작업이 정상 종료(spark.stop())되면
- 기동했던 익스큐터들을 전부 죽이고,
- 묶여 있던 CPU와 메모리를 다시 자원 풀로 회수
- 다음 작업을 위해 대기
- 연산 도중 특정 워커 노드가 고장 나면
- 워커 노드 (Worker Node) 🡲 실제 일꾼 서버
그림 하단에 나열된 3개의 큰 박스들
- 주요 역할
- 클러스터 환경에서 실제 연산 자원(CPU, RAM, 디스크)을 제공하고 물리적/논리적 연산을 담당하는 컴퓨팅 서버(노드)
- 연산 공간 및 자원 제공:
- 마스터(클러스터 매니저)의 제어에 따라 자신의 하드웨어 자원을 격리된 연산 프로세스 공간으로 제공
- 실제 태스크 병렬 실행:
- 드라이버 프로그램이 전달한 분산 작업의 최소 단위인 태스크(Task)들을 CPU 스레드를 활용해 실제로 실행
- 인메모리 데이터 유지 및 관리:
- 외부 스토리지(MinIO, S3 등)에서 데이터를 읽어와 메모리에 파티션 단위로 적재
- 연산 중 발생하는 중간 데이터를 RAM에 유지하여 처리 속도를 극복
- 내부 핵심 구성 요소
하나의 물리적/가상화된 워커 노드 서버 내부에는 Spark 작업을 수행하기 위해 다음과 같은 컴포넌트들이 유기적으로 실행됨
- 워커 데몬 (Worker Daemon):
- 클러스터 매니저와 직접 소통하는 워커 노드의 ‘관리자 프로세스’
- Standalone 모드의 Worker 프로세스, YARN의 NodeManager 등
- 자신의 서버가 살아있음을 마스터에게 알리고(Heartbeat),
- 마스터의 명령을 받아 익스큐터를 띄우거나 죽이는 제어 역할 수행
- 클러스터 매니저와 직접 소통하는 워커 노드의 ‘관리자 프로세스’
- 익스큐터 (Executor):
- 워커 데몬이 실행시킨 실제 Spark 애플리케이션 전용 연산 프로세스
- 하나의 워커 노드 안에 여러 개의 익스큐터가 뜰 수 있음
- 내부적으로 2가지 핵심 자원을 관리
- 병렬 스레드 풀 (Thread Pool):
- 드라이버가 보낸 태스크들을 여러 개의 스레드가 나누어 잡고 CPU 연산을 수행
- 메모리 저장소 (BlockManager / Memory Store):
- 연산 중인 데이터 파티션이나 개발자가 캐싱(cache()) 지정한 데이터를 RAM에 상주시키는 블록 관리자
- 병렬 스레드 풀 (Thread Pool):
- 로컬 스토리지 (Local Disk):
- 워커 노드가 가진 물리 디스크 영역
- 메모리가 부족하여 넘치는 데이터(Spill)를 임시 저장하거나, 다른 워커 노드로 데이터를 보내기 전 셔플(Shuffle) 중간 결과물을 파일로 저장하는 공간
- 작업 프로세스
전체 클러스터가 움직일 때, 개별 워커 노드 내부에서 일어나는 핵심 작업 흐름
- 1단계: 데몬 기동 및 자원 보고 (Registration)
- 인프라가 켜지면 워커 노드의 관리 데몬이 실행됨
- 클러스터 매니저에게 “저는 CPU 코어 8개, RAM 16GB를 가진 워커 노드입니다”라고 등록
- 주기적으로 살아있다는 신호(Heartbeat)를 보냄
- 2단계: 익스큐터 할당 및 구동 (Launch Executor)
- 클러스터 매니저로부터 특정 Spark 작업을 지원하라는 명령을 받으면,
- 지정된 만큼의 자원(예: CPU 4코어, RAM 8GB)을 떼어내어
- 독립된 익스큐터(Executor) 프로세스를 노드 내에 구동
- 3단계: 데이터 로드 및 병렬 연산 (Task Execution)
- 구동된 익스큐터는 이제 드라이버 프로그램과 직접 통신 라인을 개설하고 태스크들을 받아옴
- 외부 분산 스토리지(MinIO 등)에서 배정된 데이터 파티션을 읽어와 메모리 저장소에 올린 뒤,
- 내부 스레드 풀을 돌려 연산을 병렬로 처리
- 4단계: 데이터 셔플링 처리 (Data Shuffling)
- 연산 도중 ReduceByKey나 Join 같은 명령을 만나면 🡲 자기가 가진 데이터와 다른 워커 노드가 가진 데이터를 섞어야 함
- 이때 중간 결과를 로컬 디스크에 임시로 기록
- 네트워크 통신을 통해 다른 워커 노드의 익스큐터들과 데이터를 교환(Shuffle)
- 5단계: 결과 보고 및 프로세스 회수 (Result Report & Clean)
- 모든 태스크 연산과 가공이 끝나면 익스큐터는 최종 부분 결과물을 드라이버 프로그램으로 전송
- 전체 Spark 작업이 종료되면
- 실행 중이던 익스큐터 프로세스를 완전히 종료(Kill)
- 사용했던 메모리와 CPU 자원을 완전히 비움
- 다음 작업을 위해 대기 상태로 돌아감
- 외부 분산 스토리지 (External Distributed Storage)
그림 우측 상단에 위치
- 주요 역할
- Spark 클러스터와 분리되어 존재
수 페타바이트(PB) 이상의 대용량 데이터를 고성능으로 읽고 쓸 수 있도록 지원하는 독립된 저장소 시스템
- 컴퓨팅과 저장의 분리 (Decoupling of Compute and Storage):
- 연산 엔진(Spark)과 저장소(Storage)의 분리 🡲 유연한 인프라 확장을 가능
- 데이터가 늘어나면 저장소만 늘림
- 연산이 복잡해지면 Spark 노드만 늘림
- 연산 엔진(Spark)과 저장소(Storage)의 분리 🡲 유연한 인프라 확장을 가능
- 데이터 영속성 (Data Persistence) 보장:
- Spark 클러스터나 워커 노드가 어떤 이유로든 완전히 다운되거나 삭제(도커 컨테이너 삭제 등)되어도,
- 원본 데이터와 최종 결과 데이터는 이곳에 안전하게 보관됨
- 고성능 병렬 Read/Write 지원:
- Spark의 여러 워커 노드가 동시에 접속
- 데이터를 파티션 단위로 빠르게 읽어가고 쓸 수 있도록 멀티 채널 입출력(I/O)을 지원
- 주요 종류 및 구성 요소
실무 환경 및 커리큘럼에 따라 활용되는 스토리지 종류가 다름
- 오픈소스/클라우드 오브젝트 스토리지 (현대적 대세):
- MinIO(로컬 S3 호환)나 AWS S3등이 여기에 해당
- 구성 요소:
- 데이터를 버킷(Bucket)과 객체(Object) 단위로 관리
- 디렉터리 계층 구조 없이 고유 키(Key)를 통해 HTTP REST API로 초고속 접근
- 하둡 분산 파일 시스템 / HDFS (전통적 환경):
- 과거 빅데이터 인프라의 표준이던 파일 시스템
- 구성 요소:
- 파일의 메타데이터와 블록 위치를 관리하는 네임노드(NameNode)
- 실제 데이터 블록을 쪼개어 저장하는 수많은 데이터노드(DataNode)
- 차세대 테이블 포맷 라이브러리 (Iceberg 등):
- Apache Iceberg는 스토리지 자체가 아니라, 이 외부 분산 스토리지 위에 올라가는 소프트웨어 계층
- 데이터 파일들의 목록을 관리하여 분산 스토리지 환경에서도 SQL 트랜잭션(ACID)이 가능하도록 지원
- 작업 프로세스 (Step-by-Step)
Spark 애플리케이션이 실행될 때, 외부 분산 스토리지가 데이터와 소통하는 단계별 흐름
- 1단계: 스토리지 커넥터 연결 (Connection)
- Spark 드라이버 프로그램이 실행될 때
- 환경 설정 정보(spark-defaults.conf 등)를 통해 외부 스토리지의 주소(Endpoint)와 인증 정보(Access Key, Secret Key)를 전달받아
- 연결 파이프라인을 개설
- 2단계: 데이터 구조 분석 및 분할 계획 (Metadata Read)
- 사용자가 데이터를 읽는 코드(예: spark.read.load())를 실행하
- 외부 스토리지는 파일의 크기와 스키마 정보를 드라이버에게 제공
- 드라이버는 이를 바탕으로 워커 노드들이 나누어 읽을 수 있도록 분할 계획을 수립
- 3단계: 병렬 데이터 전송 (Parallel Data Supply)
- 각 워커 노드의 익스큐터들이 자신에게 배정된 데이터 블록이나 오브젝트 파티션을 외부 분산 스토리지에 요청
- 외부 스토리지는 여러 워커 노드의 요청을 동시에 받아들여 독립된 네트워크 채널을 통해 데이터를 병렬로 전달
- 4단계: 최종 결과 적재 및 저장 (Data Write & Replication)
- Spark의 연산과 가공이 모두 끝난 뒤 저장(DataFrame.write) 명령이 전달되면
- 수많은 익스큐터가 각자 계산한 결과 파일들을 외부 분산 스토리지의 지정된 경로로 동시 저장 시도
- 스토리지는 이 파일들을 분산 저장
- 시스템 설정에 따라 자동으로 데이터를 복제(Replication)하여 장애에 대비
- 5단계: 트랜잭션 마감 (Commit / Iceberg 연동 시)
- Apache Iceberg 같은 테이블 포맷을 함께 사용 중인 경우,
- 파일 저장이 끝난 후 최종적으로 메타데이터 스냅샷 파일이 갱신됨
🡲 외부 분산 스토리지 내의 데이터가 “오염 없이 완벽하게 저장 완료되었다”는 것을 보장
- 요약
- 드라이버(Driver) 기동:
- 개발자가 제출한 파이썬/스칼라 코드 실행 🡲 클러스터의 두뇌인 드라이버 프로그램이 먼저 기동
- 자원 요청:
- 드라이버는 Spark Master에게 “이 작업을 처리해야 하니 자원을 할당해달라”고 요청
- 익스큐터 생성 명령:
- Master는 클러스터 내의 Worker Node들의 여유 자원을 확인 후 🡲 워커들에게 “너희 서버에 익스큐터 프로세스를 띄워라”고 명령
- 드라이버와 익스큐터의 직접 소통:
- 익스큐터들이 구동되면, 이들은 Master를 거치지 않고 드라이버와 직접 연결됨
- 드라이버는 코드를 쪼갠 소형 작업(Task)을 익스큐터들에게 직접 던지고 🡲 익스큐터는 연산 결과를 드라이버에게 직접 보고함
- 자원 반납:
- 작업이 완전히 끝나면 익스큐터 종료 🡲 Master는 해당 자원을 다시 여유 자원으로 회수
1.4 M-W 구조의 특징 및 한계
- 장점
- 동적 확장성 (Scalability):
- 데이터 처리량이 늘어나면
🡲 가동 중인 Master 밑에 새로운 Worker Node 서버를 물리적으로 추가 🡲 클러스터 규모 쉽게 확장
- 데이터 처리량이 늘어나면
- 결함 허용 (Fault Tolerance):
- 특정 Worker Node가 네트워크 단절이나 하드웨어 고장으로 죽으면
🡲 Master는 이를 즉시 감지 🡲 해당 워커에 배정되었던 작업을 다른 살아있는 워커의 익스큐터로 이관하여 재실행(Failover)
- 특정 Worker Node가 네트워크 단절이나 하드웨어 고장으로 죽으면
- 동적 확장성 (Scalability):
- 한계 및 보완 (HA 구조)
- 마스터의 단일 장애점 (SPOF):
- 클러스터의 자원을 관리하는 Master가 한 대뿐이라면,
- 이 Master 서버가 다운될 경우 전체 클러스터 시스템이 마비됨
- 해결책:
- ZooKeeper(주키퍼)를 연동하여
Active Master와Standby Master를 두는 고가용성(HA: High Availability) 구조 채택 - Active Master가 죽더라도 Standby Master가 즉시 역할을 승계하도록 구성함
- ZooKeeper(주키퍼)를 연동하여
- 마스터의 단일 장애점 (SPOF):
2. Spark와 전통적 분산 데이터 처리
- 여기서 ‘일반적인 분산 데이터 처리’란 Spark 등장 이전의 표준이었던 Hadoop MapReduce 기반의 시스템을 의미
| 비교 항목 | 일반적인 분산 처리 (Hadoop MapReduce) | Apache Spark |
|---|---|---|
| *연산 중심축 | 디스크(Disk) 중심 | 메모리(In-Memory) 중심 |
| 중간 결과 저장 | `Map` 단계가 끝나면 중간 결과를 무조건 디스크(HDFS)에 쓰고, `Reduce`가 다시 읽음 | 연산 중간 결과를 디스크로 내리지 않고 메모리(RAM)에 유지하며 다음 연산으로 직행 |
| 속도 차이 | 디스크 I/O가 빈번하여 느림 (특히 반복 연산 시 심각함) | MapReduce 대비 **최대 100배** 빠른 연산 속도 제공 |
| 결함 허용 방식 (Fault Tolerance) | 복제본(Replica) 데이터를 디스크에 여러 개 저장해 두는 방식 | 데이터 계보(Lineage)를 기억하여 노드가 죽으면 유실된 파티션만 메모리에서 재계산해 복구 |
| 스트리밍 처리 | 기본적으로 불가능하거나 별도의 엔진(Storm 등)을 붙여야 함 | 하나의 아키텍처 내에서 **마이크로 배치(Micro-batch)** 형태로 스트리밍 처리 통합 지원 |
| 개발 API | `Map`과 `Reduce`라는 저수준의 복잡한 로직을 직접 구현해야 함 | SQL, DataFrame 등 고수준 API를 제공하여 코드가 간결하고 직관적임 |
- 왜 Spark 아키텍처가 대세인가?
- 전통적인 하둡 분산 처리:
- “네트워크나 노드는 언제든 죽을 수 있으니, 매 단계 안전하게 디스크에 기록하자”라는 철학
- 안전하지만 지나치게 느림
- Spark 아키텍처:
- “메모리는 엄청나게 빠르다. 노드가 고장 나서 메모리 데이터가 날아가면 어떻게 하냐고? 데이터가 만들어진 족보(Lineage)를 드라이버가 쥐고 있으니, 고장 난 부분만 번개처럼 새로 계산하면 된다!”라는 철학
- 이 스마트한 구조 덕분에 Spark는 오늘날 현대 데이터 엔지니어링의 표준 지위를 차지함