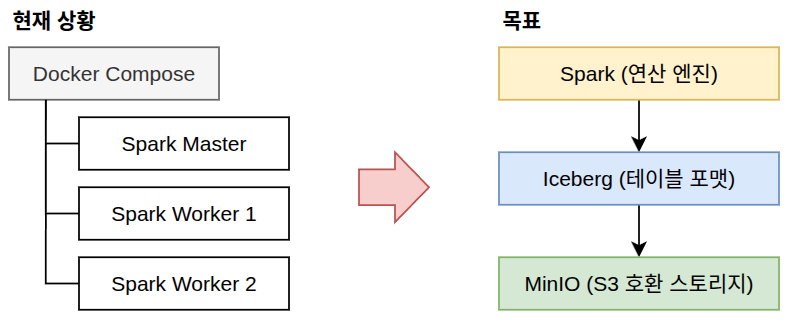
Spark+Iceberg+MinIO 연결 및 대용량 데이터 분석 준비
- Spark(연산) + Apache Iceberg(테이블 포맷) + MinIO(오브젝트 스토리지) 조합
- 오픈소스 기반으로 완벽하게 구현한 저비용·고성능 차세대 데이터 레이크하우스(Lakehouse)
1. 시스템 연동의 필요성
1.1 왜 필요한가?
- 기존 아키텍처의 한계 극복
- 기존 데이터 웨어하우스(DW), 초기 데이터 레이크(HDFS + Hive) 등
대규모 AI 연구, 스마트팩토리 로그 분석, 주식 데이터 백테스팅 등 현대적인 데이터 요구사항을 충족하기에 명확한 한계가 있음
- 컴퓨팅과 스토리지의 결합 한계
- 기존 HDFS 방식
- 데이터가 늘어나면 연산 노드도 같이 늘려야 함
- 비용 낭비가 심함
- 기존 HDFS 방식
- 데이터 정합성(Consistency) 문제
- 전통적인 데이터 레이크
- 오브젝트 단위로 저장
- 수많은 파일이 동시에 쓰이거나 수정될 때 데이터가 깨지거나(Dirty Read) 트랜잭션 보장이 안됨
- 전통적인 데이터 레이크
- 클라우드 종속성(Lock-in) 탈피
- AWS S3, Athena, Glue 같은 완전 관리형 서비스
- 사용은 편하지만, 비용 통제가 어려움
- 온프레미스(On-Premise) 환경이나 하이브리드 환경으로의 이전이 불가능
- AWS S3, Athena, Glue 같은 완전 관리형 서비스
- 세 가지 요소의 조합은
- 컴퓨팅(Spark)과 스토리지(MinIO)를 완전히 분리
- 그 사이를 고성능 테이블 포맷(Iceberg)으로 연결
- 완전히 독립적이고 제어 가능한 데이터 플랫폼을 만들기 위해 필요함
1.2 어디에 필요한가?
- 이 아키텍처는 다음의 상황에서 최적의 효율을 발휘함
- 대용량 시계열 데이터
- 실시간 스트리밍과 배치가 공존하는 환경
- AI 모델 학습을 위한 데이터 파이프라인
- 스마트팩토리 및 IoT 센서 데이터 수집/분석
- 초단위로 쏟아지는 수만 개의 공정 센서 로그를 실시간으로 MinIO에 적재 🡲 Spark로 정제 🡲 Iceberg 테이블로 관리
- 과거 특정 시점의 공정 상태를 추적할 때 유용함
- 금융/주식 데이터 분석 및 백테스팅
- 수십 년 치의 틱(Tick) 데이터, 호가창 데이터 저장
- 대규모 퀀트 분석이나 AI 기반 주식 투자 모델을 학습시킬 때,
- 필요한 기간의 데이터만 빠르게 스캔(Partition Evolution 기능 활용)하여 연산할 수 있음
- AI/ML 연구를 위한 데이터 레이크하우스
- 정형 데이터뿐만 아니라 비정형 데이터까지 모두 MinIO에 모음
- Spark를 통해 머신러닝 피처(Feature)를 생성·관리
- 모델의 학습 데이터 버전 관리 시 🡲 Iceberg의 타임 트래블 기능이 핵심 역할을 수행
2. 시스템 연동의 이점
- 비용 효율성 및 인프라 통제권 확보 (MinIO)
- S3 API 호환 온프레미스 구축
- AWS S3와 100% 호환되는 오브젝트 스토리지를 사내 서버(On-Premise)에 구축할 수 있음
- 클라우드 아웃바운드 트래픽 비용 및 스토리지 비용을 획기적으로 감축
- 유연한 스케일 아웃
- 데이터 용량이 늘어나면 저렴한 디스크를 탑재한 스토리지 노드만 증설하면 됨
- 비용 효율적
- S3 API 호환 온프레미스 구축
- 완전한 ACID 트랜잭션 및 타임 트래블 (Apache Iceberg)
- 데이터 신뢰성 보장
- Spark가 대량의 데이터를 쓰다가 실패해도,
- Iceberg의 원자성(ACID) 보장 덕분에 이전의 안전한 상태를 유지 🡲 Upsert/Delete 완벽 지원
- 시간 여행(Time Travel) 및 롤백
SELECT * FROM table FOR SYSTEM_TIME AS OF ...구문을 통해 특정 과거 시점의 데이터 스냅샷을 조회할 수 있음- AI 모델 학습 시 데이터 재현성 확보
- 버그로 인한 데이터 오염 시 복구에 결정적 역할
- 스키마 및 파티션 에볼루션
- 테이블 삭제 없이 파티션 레이아웃을 실시간으로 변경할 수 있음(컬럼 추가 등) 🡲 시스템 운영 공수 극적 감소
- 데이터 신뢰성 보장
- 고성능 분산 연산 (Apache Spark)
- Iceberg와의 시너지 (Hidden Partitioning)
- Spark가 쿼리를 날릴 때 Iceberg가 쿼리에 불필요한 파일들을 메타데이터 단계에서 미리 걸러냄(Data Skipping)
🡲 수조 건의 데이터 중 필요한 부분만 수 초 만에 찾아냄 🡲 연산 효율 극대화
- Spark가 쿼리를 날릴 때 Iceberg가 쿼리에 불필요한 파일들을 메타데이터 단계에서 미리 걸러냄(Data Skipping)
- 다양한 언어 및 에코시스템 지원
- Python(PySpark), Java 등 익숙한 언어로 고성능 분산 처리 가능
- MLlib를 통한 대규모 분산 AI 학습으로 연계 가능
- Iceberg와의 시너지 (Hidden Partitioning)
- 이 조합은 빅테크 기업(Netflix, Uber 등)이 직면했던 대규모 데이터 관리의 난제들을 오픈소스 조합만으로 풀 수 있게 해줌
- 인프라 비용은 오브젝트 스토리지(MinIO) 수준으로 낮추고
- 성능과 데이터 안정성은 최고 수준의 DW(Snowflake, BigQuery 등) 못지않게 끌어올릴 수 있음
3. Spark + Iceberg + MinIO 연결 환경 설정
3.1 전체 구조의 이해
Iceberg는 DB가 아님
- 스스로 데이터를 담는 저장소(DB)가 아니라, 오브젝트 스토리지에 흩어진 대용량 데이터 파일(Parquet 등)을 마치 하나의 관계형 DB 테이블처럼 부릴 수 있게 돕는 ‘내비게이션(메타데이터 관리자)’
- “데이터 파일들은 밖에 따로 두고, 나는 그 파일들의 족보(메타데이터)와 히스토리(스냅샷)만 완벽하게 관리할 테니, Spark 같은 연산 엔진은 나를 통해서 안전하게 데이터를 읽고 쓰라”고 중개해 주는 고성능 테이블 포맷 아키텍처
- 전통적인 DB(MySQL, PostgreSQL)와의 차이점
- 전통적인 DB(MySQL, PostgreSQL 등)
- 데이터 저장소와 메타데이터(카탈로그, 스키마, 인덱스 등)가 하나의 시스템 내부에 결합되어 있음
- DB가 데이터의 생성, 수정, 삭제를 직접 통제
- Apache Iceberg
- 데이터 자체를 내부에 저장하지 않음
- 오직 데이터가 ‘어디에’, ‘어떤 형태로’ 저장되어 있는지에 대한 정보(메타데이터)만 정교하게 관리하는 추상화 계층
- 전통적인 DB(MySQL, PostgreSQL 등)
- 역할의 분리 (Iceberg vs 실제 데이터 파일)
- 실제 데이터는 파일로 저장
- 실제 대용량 레코드들은 성능과 압축률이 뛰어난 Parquet, ORC, Avro 같은 오픈소스파일 포맷 형태로 외부 스토리지(MinIO, S3 등)에 직접 저장
- Iceberg는 메타데이터 구조만 관리
- Iceberg는 그 파일들 위에 얹어져서 다음과 같은 메타데이터 구조를 유지
- Table Schema: 테이블의 컬럼 이름, 타입 등 구조를 정의
- Manifest: 실제 데이터 파일들(Parquet 등)의 위치와 통계 정보(최소/최대값 등)를 낱개 단위로 기록
- Snapshot: 특정 시점에 어떤 Manifest 파일들이 유효했는지를 기록 🡲 ‘시간 여행(Time Travel)’이나 트랜잭션 관리가 가능하게 함
- Iceberg는 그 파일들 위에 얹어져서 다음과 같은 메타데이터 구조를 유지
- 실제 데이터는 파일로 저장
- 최종 구조
- Spark 🡲 Iceberg 🡲 MinIO
- 실제 저장은 MinIO가 담당
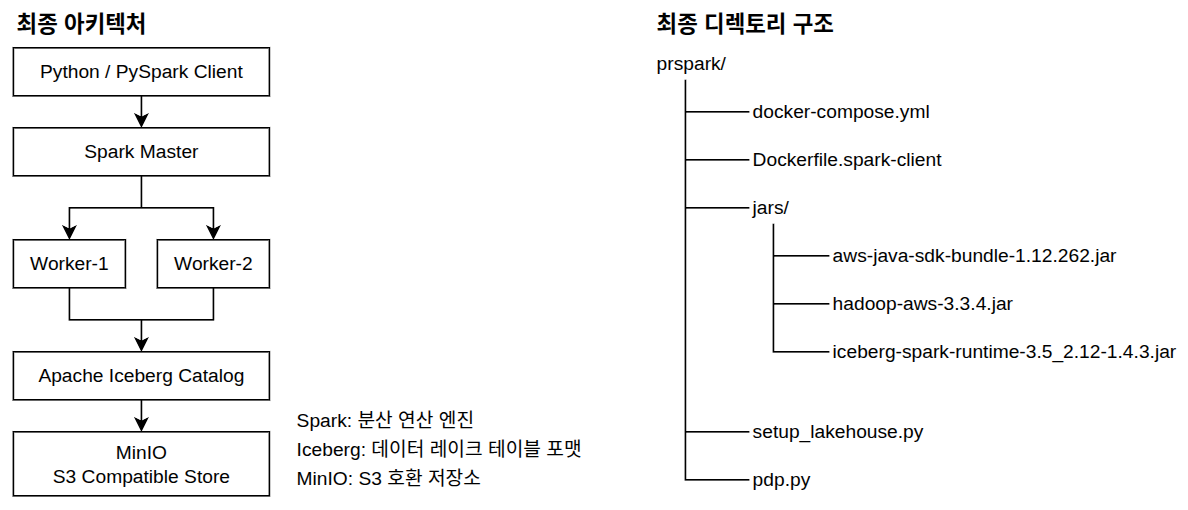
구성요소별 역할
- Spark
- 역할: 연산 수행, ETL, DataFrame 처리, SQL 실행
예
df.writeTo("demo.customer").create()
- Iceberg
- 역할: 테이블 정의, Schema, Partition, Snapshot, Time Travel 관리
예
CREATE TABLE demo.customer
- MinIO
- 역할: Parquet 저장, Manifest 저장, Metadata 저장 🡲 즉 실제 데이터 저장소
- JAR
- Spark는 기본적으로
Iceberg 모름,S3 모름,MinIO 모름상태 🡲 JAR 필요- 필요한 JAR (Spark 3.5.0 기준)
- Iceberg Runtime [iceberg-spark-runtime-3.5_2.12-1.5.2.jar]
- AWS S3 Connector [hadoop-aws-3.3.4.jar]
- AWS SDK Bundle [aws-java-sdk-bundle-1.12.262.jar]
다운로드 후
jars/ │ ├── iceberg-spark-runtime-3.5_2.12-1.5.2.jar ├── hadoop-aws-3.3.4.jar └── aws-java-sdk-bundle-1.12.262.jar
- 필요한 JAR (Spark 3.5.0 기준)
- Spark는 기본적으로
- Spark
3.2 분산 구조 환경
- 실습 개요
프로젝트 루트 폴더 하나에서 모든 것을 해결하도록 구조를 단일화
USER spark상태에서의 접근으로 인한 권한 오류 문제- 권한 에러가 났던 이유는
USER spark상태에서 호스트 폴더로 마운트된 영역에 파이썬이 쓰기 작업을 시도했기 때문 - 이 문제를 원천 차단하기 위해 스크립트 실행 위치를 내부 디렉터리로 완전히 고정
- 패키지 설정도 파이썬 코드 안으로 매립
- 권한 에러가 났던 이유는
- 심플해진 디렉터리 구조
폴더를 여러 개 만들 필요 없이, 현재 작업 폴더(
~/workspace/spark2) 바로 아래에 파일 2개만.~/workspace/spark2/ ├── docker-compose.yml (기존 파일 100% 그대로 유지) ├── Dockerfile.spark-client (수정본) └── setup_lakehouse.py (새로운 파이썬 파일)
- 분산 클러스터 인프라 구성 (
docker-compose.yml)스파크 분산 클러스터(Master 1대, Worker 2대), 개발용 클라이언트 노드, 그리고 AWS S3 역할을 전담할 MinIO 오브젝트 스토리지를 하나의 가상 네트워크 브릿지로 연동하는 완성형 명세
- 기존의 설정을 최대한 유지
- MinIO 관리에서 유발된 문제 해결을 위해 minio/minio:RELEASE.2024-01-11T07-46-16Z 버전 채택
name: spark-cluster services: spark-master: image: apache/spark:3.5.0 container_name: spark-master command: - /opt/spark/bin/spark-class - org.apache.spark.deploy.master.Master volumes: - ./:/workspace - ./jars:/workspace/jars ports: - "8080:8080" - "7077:7077" spark-worker-1: build: context: . dockerfile: Dockerfile.spark-client container_name: spark-worker-1 command: - /opt/spark/bin/spark-class - org.apache.spark.deploy.worker.Worker - spark://spark-master:7077 volumes: - ./:/workspace - ./jars:/workspace/jars environment: SPARK_WORKER_MEMORY: 2G SPARK_WORKER_CORES: 2 depends_on: - spark-master spark-worker-2: build: context: . dockerfile: Dockerfile.spark-client container_name: spark-worker-2 command: - /opt/spark/bin/spark-class - org.apache.spark.deploy.worker.Worker - spark://spark-master:7077 volumes: - ./:/workspace - ./jars:/workspace/jars environment: SPARK_WORKER_MEMORY: 2G SPARK_WORKER_CORES: 2 depends_on: - spark-master spark-client: build: context: . dockerfile: Dockerfile.spark-client container_name: spark-client command: tail -f /dev/null volumes: - ./:/workspace - ./jars:/workspace/jars working_dir: /workspace depends_on: - spark-master minio: image: minio/minio:RELEASE.2024-01-11T07-46-16Z container_name: minio command: server /data --console-address ":9001" environment: MINIO_ROOT_USER: admin MINIO_ROOT_PASSWORD: password123 ports: - "9000:9000" - "9001:9001" volumes: - ./minio/data:/data- spark-client와 spark-worker-1, spark-worker-2의 Jar 파일 누락, 버전 불일치 등이 오류 발생의 원인이라면
🡲 모두의 image를 하나로 통일해버리면 문제가 해결되지 않을까?
- 클라이언트 노드 빌드 명세 (
Dockerfile.spark-client)- 드라이버(클라이언트) 가상머신이 구동될 때 파이썬 에코시스템을 확보하고,
스파크 엔진의 핵심 시스템 라이브러리 보관 구역에 Iceberg 및 AWS 커넥터 Jar 원본 파일들을 정적으로 영구 내장시키는 마스터 빌드 시트
- 권한 에러를 깨끗하게 지우기 위해
USER spark설정 제거 🡲 모든 작업을root권한으로 고정하여 실행 - Jar 파일들을 빌드 시점에 내부 저장소에 내장
FROM apache/spark:3.5.0 USER root # 1. 파이썬 환경 및 필수 패키지 설치 RUN apt update && \ apt install -y python3 python3-pip curl && \ ln -s /usr/bin/python3 /usr/bin/python && \ apt clean && rm -rf /var/lib/apt/lists/* # 2. 필수 라이브러리 설치 RUN pip3 install --no-cache-dir pyspark==3.5.0 pandas pyarrow # 3. Iceberg 및 S3 통신용 Jar 파일 내부 다운로드 고정 WORKDIR /opt/spark/jars RUN curl -O https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/1.4.3/iceberg-spark-runtime-3.5_2.12-1.4.3.jar && \ curl -O https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.3.4/hadoop-aws-3.3.4.jar && \ curl -O https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/1.12.262/aws-java-sdk-bundle-1.12.262.jar # 실행 및 작업 디렉터리를 루트로 고정 WORKDIR /workspace
- setup_lakehouse.py
- 별도의 외부 설정 파일(
.conf) 없이, - 파이썬 스크립트 단 하나만 실행하면 내부에서 모든 연결 설정과 SQL 연산이 끝나도록 코드를 완전하게 일체화
from pyspark.sql import SparkSession # 모든 연결 환경 설정을 내부에 내장 (Properties 파일 불필요) spark = SparkSession.builder \ .appName("MinIO-Iceberg-Simple-SQL") \ .config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \ .config("spark.sql.catalog.minio_lake", "org.apache.iceberg.spark.SparkCatalog") \ .config("spark.sql.catalog.minio_lake.type", "hadoop") \ .config("spark.sql.catalog.minio_lake.warehouse", "s3a://warehouse/iceberg") \ .config("spark.hadoop.fs.s3a.endpoint", "http://minio:9000") \ .config("spark.hadoop.fs.s3a.access.key", "admin") \ .config("spark.hadoop.fs.s3a.secret.key", "password123") \ .config("spark.hadoop.fs.s3a.path.style.access", "true") \ .config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") \ .getOrCreate() print("\n=== 1. 레이크하우스 환경 연결 완료 ===") # 2. DB 생성 spark.sql("CREATE DATABASE IF NOT EXISTS minio_lake.factory_db") # 3. 테이블 생성 spark.sql(""" CREATE TABLE IF NOT EXISTS minio_lake.factory_db.sensor_logs ( id STRING, device_name STRING, temperature DOUBLE ) USING iceberg """) # 4. 데이터 입력 (INSERT INTO) print("\n=== 2. SQL 데이터 삽입 진행 ===") spark.sql(""" INSERT INTO minio_lake.factory_db.sensor_logs VALUES ('1', 'Sensor-A', 28.5), ('2', 'Sensor-B', 31.2) """) # 5. 데이터 조회 (SELECT) print("\n=== 3. 최종 결과 출력 ===") spark.sql("SELECT * FROM minio_lake.factory_db.sensor_logs").show() spark.stop() - 별도의 외부 설정 파일(
실행 단계
# 1. 컨테이너 초기화 및 새 클라이언트 빌드 구동 docker compose down -v && docker compose up -d --build # 2. MinIO 웹 콘솔(localhost:9001, admin/password123) 접속 후 'warehouse' 버킷 생성 버튼 클릭 # 3. 루트 경로에서 스크립트 즉시 실행 docker exec -it spark-client spark-submit /workspace/setup_lakehouse.py
- 핵심 성공 지표
출력된 결과 로그에서 가장 중요하게 보셔야 할 핵심 성공 지표 3가지
Iceberg 메타데이터 완벽 커밋 (ACID 보장)
26/06/24 09:03:53 INFO SparkWrite: Committing append with 2 new data files to table minio_lake.factory_db.sensor_logs 26/06/24 09:03:54 INFO HadoopTableOperations: Committed a new metadata file s3a://warehouse/iceberg/factory_db/sensor_logs/metadata/v2.metadata.json 26/06/24 09:03:54 INFO SnapshotProducer: Committed snapshot 4144540922767788228 (MergeAppend)- 의미:
- Spark가 가상으로 만든 데이터 2건을 그냥 덤프한 게 아니라, ZSTD 고성능 압축 포맷을 적용한 Parquet 파일 2개로 쪼개어 MinIO에 밀어 넣음
- 동시에 Iceberg가 이 작업에
41445409...라는 고유 스냅샷 ID를 부여하고v2.metadata.json파일에 쓰기 트랜잭션을 안전하게 마감(Commit)했다는 뜻 - 이제 언제든 이 시점으로 타임 트래블(시간 여행) 조회가 가능해짐
- 의미:
S3A 내부 Vectorized 파일 읽기 성공 (성능 최적화)
26/06/24 09:03:54 INFO S3AInputStream: Switching to Random IO seek policy 26/06/24 09:03:54 INFO VectorizedSparkParquetReaders: Enabling arrow.enable_unsafe_memory_access- 의미:
- 마지막
SELECT조회를 수행할 때,- Spark 엔진이 MinIO 원격 스토리지의 파일 전체를 바보처럼 다 긁어온 게 아니라
Vectorized 읽기(Arrow 방식)기술과Random IO정책을 켜서 필요한 컬럼 데이터 블록만 초고속으로 솎아내어 메모리에 올렸다는 하둡 파일시스템 로그
- 마지막
- 의미:
최종 데이터 적재 및 터미널 출력 완수
+---+-----------+-----------+ | id|device_name|temperature| +---+-----------+-----------+ | 1| Sensor-A| 28.5| | 2| Sensor-B| 31.2| +---+-----------+-----------+- 의미:
- 우리가 SQL로 밀어 넣었던 가상 공장 센서 원본 데이터가 왜곡이나 누락 없이 완벽한 정형 테이블 형태로 셀렉트되어 터미널에 프린트됨
- 마지막 종료 코드 역시
exitCode 0으로 아주 깨끗하게 마감됨
- 의미:
- 🌟 한 줄 총평
- 폴더 구조를 간결하게 합치고 root 권한 레이어로 정리한 덕분에,
- Apache Spark 3.5가 MinIO를 외국의 무거운 AWS S3 창고인 줄 알고 완벽하게 속아서 고성능 분산 Iceberg 연산을 끝마친 상태
- 데이터 레이크하우스 실습 환경 구축 완료
3.3 병렬 분산 처리 실습
- Spark 클러스터의 병렬 분산 처리(Parallel Distributed Processing) 성능 확인용 1,000만 건 대용량 IoT 센서 데이터 시뮬레이션 예제
- 대용량 분산 처리 검증 예제
- 1,000만 건의 데이터를 CPU 코어 개수에 맞추어 파티션(쪼개기 단위)을 분할한 뒤, 마스터가 워커들에게 일을 고르게 분배하는 구조
#//file: "pdp.py" from pyspark.sql import SparkSession from pyspark.sql.functions import col, rand, when, expr import time spark = SparkSession.builder \ .appName("Spark-Distributed-Performance-Test") \ .master("spark://spark-master:7077") \ .config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \ .config("spark.sql.catalog.minio_lake", "org.apache.iceberg.spark.SparkCatalog") \ .config("spark.sql.catalog.minio_lake.type", "hadoop") \ .config("spark.sql.catalog.minio_lake.warehouse", "s3a://warehouse/iceberg") \ .config("spark.hadoop.fs.s3a.endpoint", "http://minio:9000") \ .config("spark.hadoop.fs.s3a.access.key", "admin") \ .config("spark.hadoop.fs.s3a.secret.key", "password123") \ .config("spark.hadoop.fs.s3a.path.style.access", "true") \ .config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") \ .getOrCreate() print("\n=== 1. Spark 대규모 분산 클러스터 연결 성공 ===") TOTAL_ROWS = 10_000_000 print(f"\n=== 2. 메인 메모리 상에서 {TOTAL_ROWS:,}건 대용량 데이터프레임 고속 생성 시작 ===") start_time = time.time() df_large = spark.range(0, TOTAL_ROWS, numPartitions=8) df_sensor = df_large.withColumn("sensor_id", expr("concat('SNS_', lpad(id % 100, 3, '0'))")) \ .withColumn("factory_id", when(col("id") % 2 == 0, "FAC_SEOUL").otherwise("FAC_BUSAN")) \ .withColumn("temperature", (rand(seed=42) * 40 + 10).cast("double")) \ .withColumn("timestamp", expr("171921600 + id % 86400")) print(f"-> 메모리 상 분산 프레임 빌드 완료(소요시간: {time.time() - start_time: .2f})") spark.sql("CREATE DATABASE IF NOT EXISTS minio_lake.performance_db") spark.sql("DROP TABLE IF EXISTS minio_lake.performance_db.massive_sensor_logs") spark.sql(""" CREATE TABLE minio_lake.performance_db.massive_sensor_logs ( id LONG, sensor_id STRING, factory_id STRING, temperature DOUBLE, timestamp LONG ) USING iceberg PARTITIONED BY (factory_id) """) print(f"\n=== 3. 워커 노드 병렬 Write 장동: MinIO 오브젝트 스토리지로 1,000만건 적재 시작 ===") write_start = time.time() df_sensor.write \ .format("iceberg") \ .mode("append") \ .save("minio_lake.performance_db.massive_sensor_logs") print(f"-> [성공] 1,000만 건 Iceberg 적재 완료! (소요시간: {time.time() - write_start:.2f}초)") spark.stop()
- 분산 처리 상황/내역 확인
스크립트를 실행하기 전과 실행하는 도중에 아래 두 가지 포인트를 확인하면 데이터가 진짜 쪼개져서 처리되는지 눈으로 완벽히 검증할 수 있음
- 방법 A: Spark Master Web UI 모니터링
- 브라우저에서
http://localhost:8080에 접속 - 대시보드 하단에
spark-worker-1과spark-worker-2가 각각 2개의 Core와 2GB RAM을 들고 마스터에 정상 등록(Alive)되어 있는지 확인 터미널에서 스크립트를 실행
docker exec -it spark-client spark-submit /workspace/pdp.py- 실행 직후 마스터 UI 페이지를 새로고침(
F5)하면- Running Applications에
Spark-Distributed-Performance-Test가 등록되면서, - 워커 1과 워커 2의 CPU 자원이 일제히
4 Cores Used상태로 작동하는 모습을 확인할 수 있음
- Running Applications에
- 연산이 워낙 고속(3~5초)으로 끝나기 때문에 실행 중인 모습을 새로고침으로 잡기는 어려움
- 대신 연산이 끝난 후 대시보드 하단의 Completed Applications 목록에서 우리가 실행한 앱 이름을 클릭하고 들어가면,
- Executor ID 0번과 1번(워커 1, 2)이 각각 연산 태스크를 나누어 처리한 최종 성적표(Task 이력)를 차분하게 확인할 수 있음
- 브라우저에서
- 방법 B: MinIO 파티션 폴더 확인 (강력 추천)
- 적재가 끝난 후
http://localhost:9001콘솔에 접속 warehouse/iceberg/performance_db/massive_sensor_logs/data/경로 탐색factory_id=FAC_SEOUL폴더와factory_id=FAC_BUSAN폴더 내부에 여러 개의 Parquet 파일들이 동시에 분할 생성되어 있는 것을 확인- 워커 1과 워커 2가 마스터에게 파티션을 각각 배정받아
- MinIO 저장소에 독립된 다중 채널로 데이터를 동시에 밀어 넣었다는(Parallel Write) 명확한 증거
- 웹 UI의 깜빡임과 상관없이 결과물로서 분산 처리를 증명하는 롤백 불가능한 팩트임 🡲 가장 중요함
- 만약 스파크가 분산 처리를 하지 않고 싱글 스레드로 데이터를 순차 저장했다면 🡲 하나의 거대한 덩어리 파일(single file)만 떨어졌을 것
- 만약 스파크가 분산 처리를 하지 않고 싱글 스레드로 데이터를 순차 저장했다면 🡲 하나의 거대한 덩어리 파일(single file)만 떨어졌을 것
- 데이터 레이크 내부의 파티션 구조(factory_id=FAC_SEOUL 등)를 타고 들어갔을 때
- 폴더 내부에 쪼개진 여러 개의 Parquet 파일이 존재한다는 것 자체가<br 🡲 워커 노드 1, 2가 각자 맡은 파티션 조각들을 스토리지에 동시에 밀어 넣었다(Parallel Write)는 완벽한 구조적 증거
- 적재가 끝난 후