실시간 데이터의 특징과 Apache Kafka 개요
- 1. 개요 및 정의
- 2. Apache Kafka 개발역사
- 3. 실시간 데이터(Streaming Data)
- 4. Kafka의 핵심 철학 및 특징
- 5. 아키텍처
- 6. 장점과 단점
- 7. 주요 사용 목적 및 활용 분야
1. 개요 및 정의
- Apache Kafka
- 대용량·실시간 데이터 스트림을 처리하기 위해 설계된 분산형 이벤트 스트리밍 플랫폼(Distributed Event Streaming Platform)
- 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션 등에서 활용
- 현대 IT 아키텍처에서는 실시간 데이터 처리를 위한 ‘중앙 데이터 신경망’ 역할을 담당
- 단순 메시지 큐와의 차이
- 전통적인 메시지 큐(RabbitMQ, ActiveMQ 등): 시스템 간의 간단한 메시지 전달(Push/Delete 방식)에 집중
- Kafka: Log 기반의 스트리밍 플랫폼
- 이벤트 스트리밍(Event Streaming):
- 데이터베이스, 모바일 기기, 클라우드 서비스, 소프트웨어 애플리케이션 등 다양한 소스에서 발생하는 데이터(이벤트)를
- 실시간 스트림 형태로 지속적으로 캡처하고, 보존하고, 처리하는 기술
- 분산 아키텍처:
- 여러 대의 서버(Broker)에 데이터를 분산하여 저장하고 처리
- 데이터 양이 늘어나도 서버를 추가(Scale-out)하여 성능을 선형적으로 확장할 수 있음
- 이벤트 스트리밍(Event Streaming):
2. Apache Kafka 개발역사
2.1 2009~2010: 데이터 아키텍처 고민
- 급성장하던 비즈니스 인맥 SNS인 링크드인의 고민: 심각한 데이터 아키텍처 문제
- 스파게티 아키텍처
- 유저들의 클릭 로그, 프로필 조회 등 파편화된 데이터를 수집하기 위해
- 수많은 메시징 시스템을 개별적으로 연결
- 시스템이 거미줄처럼 꼬여버린 ‘스파게티 아키텍처’가 됨
- 데이터가 조금만 몰려도 시스템이 뻗어버리는 문제
- 스파게티 아키텍처
- 링크드인의 엔지니어 제이 크렙스(Jay Kreps), 네하 나르케데(Neha Narkhede), 준 라오(Jun Rao)
- 새로운 개념의 시스템을 설계하기 시작
2.2 2011~2012: 오픈소스화
- 2011년:
- 링크드인은 개발한 시스템을 오픈소스로 공개
아파치 소프트웨어 재단(Apache Software Foundation)의 인큐베이터 프로젝트로 등록됨
- 이름의 유래:
- 제이 크렙스가 작가 프란츠 카프카(Franz Kafka)의 작품을 좋아했음
- “작가를 위해 글을 쓰는 시스템(책을 쓰는 시스템)”이라는 은유를 담아 이름을 ‘Kafka’라고 명명
- 2012년:
- 아파치 재단의 공식 최상위 프로젝트(Top-Level Project)로 승격
- 전 세계 개발자들의 주목을 받기 시작
2.3 2014~2019: Confluent 창립
- 2014년:
- 카프카를 처음 만든 핵심 개발자들이 링크드인을 나와 Confluent(컨플루언트)라는 전문 기업 창립
- 이때부터 카프카는 단순 가동 시스템을 넘어 기업용 엔터프라이즈 플랫폼으로 진화
- 스트리밍 플랫폼
- 단순 메시지 저장을 넘어 데이터를 실시간으로 가공하는 Kafka Streams, 외부 시스템과 코딩 없이 연결하는 Kafka Connect 등 추가
- 단순 MQ가 아닌 ‘스트리밍 플랫폼’의 진용을 갖춤
2.4 2020~현재: KRaft 도입(홀로서기)
- 그동안 Kafka는 클러스터 관리를 위해 Zookeeper(주키퍼)라는 별도의 시스템에 완전히 의존
- 관리 포인트를 늘리고 대규모 클러스터에서 병목을 일으키는 원인
- 2021년~2023년:
- Zookeeper 없이 Kafka 자체적으로 클러스터를 관리하는 KRaft(Kafka Raft) 모드가 개발 및 안정화
- 최근 버전에서는 Zookeeper 지원이 완전히 제거(Deprecated)되거나 제거되는 추세
- 더욱 가볍고 빠른 ‘클라우드 네이티브’ 스트리밍 플랫폼으로 완전히 자리 잡음
- 요약
- 2010년: 링크드인의 사내 데이터 꼬임 문제를 해결하기 위해 탄생
- 2012년: 아파치 오픈소스로 공개된 후 대용량 처리가 필요한 전 세계 대기업들의 필수 기술로 등극
- 현재: Zookeeper 독립(KRaft)을 이루며 더욱 고성능의 실시간 데이터 중추(Backbone)로 진화 완료
3. 실시간 데이터(Streaming Data)
- 실시간 데이터(Streaming Data)는 전통적인 데이터베이스에 저장되어 정지해 있는 데이터(Data at Rest)와 달리,
- “끊임없이 흐르는 데이터(Data in Motion)”라는 독특한 패러다임을 가짐
3.1 실시간 데이터의 5대 핵심 특징
- 무한성 (Unboundedness)
- 특징:
- 데이터의 시작은 있지만 끝이 정의되어 있지 않음
- 설명:
- 전통적인 배치(Batch) 데이터는 “어제 하루 동안 들어온 데이터”처럼 경계(Bound)가 명확함
- 실시간 데이터는 서비스가 가동되는 한 24시간 내내 끊임없이 밀려드는 무한한 크기의 데이터 스트림
- 특징:
- 불변성 (Immutability)
- 특징:
- 한 번 발생한 이벤트 데이터는 절대 수정되거나 삭제되지 않음
- 설명:
- “A 사용자가 상품을 장바구니에 담았다”라는 과거의 사실(Fact) 자체는 변하지 않음
- 만약 사용자가 장바구니를 비웠다면, 기존 데이터를 수정하는 것이 아니라 “장바구니 비움”이라는 새로운 이벤트를 뒤에 추가(Append-only)하여 최종 상태를 업데이트함
- 특징:
- 시간 민감성 (Time-Sensitiveness)
- 특징:
- 데이터가 발생한 시점과 처리되는 시점 사이의 지연(Latency)이 비즈니스 가치에 직결됨
- 설명:
- 이상 거래 탐지(FDS)나 주식 거래 시스템처럼,
- 데이터가 생성된 지 몇 초 혹은 몇 밀리초(ms) 이내에 처리되어야만 의미가 있는 경우가 많음
- 시간이 흐를수록 데이터의 가치가 급격히 떨어지는 특성을 가짐
- 특징:
- 순서 보장 (Ordering)의 중요성
- 특징:
- 이벤트가 발생한 정확한 순서대로 처리되어야 데이터의 무결성이 유지됨
- 설명:
- 동일한 사용자가 ‘회원 가입’ -> ‘상품 주문’ -> ‘결제 완료’ 순으로 이벤트를 발생시켰을 때,
- 이 순서가 뒤바뀌어 수집된다면 시스템은 심각한 오류를 일으키게 됨
- 실시간 스트리밍에서는 인과관계(순서)를 보장하는 메커니즘이 필수
- 특징:
- 휘발성과 다양성 (High Velocity & Variety)
- 특징:
- 대규모의 데이터가 초당 수만~수백만 건씩 불규칙하게 쏟아짐
- 포맷이 다양함
- 설명:
- 예를 들면, 대규모 세일 기간의 커머스 클릭 로그나 IoT 센서 데이터는 예측하기 힘든 수준으로 트래픽이 폭증(Spike)할 수 있음
- 또한 JSON, 텍스트, 바이너리 등 정형화되지 않은 다양한 형태의 데이터가 섞여 들어옴
- 특징:
3.2 배치 데이터 vs 실시간 데이터 비교
| 구분 | 배치 데이터 (Batch Data) | 실시간 데이터 (Streaming Data) |
|---|---|---|
| 데이터 경계 | 유한함 (Bounded) | 무한함 (Unbounded) |
| 데이터 수정 | CRUD (수정, 삭제 빈번) | Append-only (추가만 가능, 불변) |
| 처리 지연 시간 | 시간~일 단위 (Hours to Days) | 밀리초~초 단위 (ms to Seconds) |
| 접근 방식 | 정적 쿼리 (데이터가 멈춰있음) | 지속적 쿼리 (데이터가 계속 흐름) |
| 대표 기술 | Hadoop, Spark, SQL DB | Kafka, Flink, Spark Streaming |
- 요약
- 실시간 데이터를 다룰 때 가장 위험한 접근은 “데이터가 다 쌓일 때까지 기다리는 것”
- 데이터가 생성되는 즉시 가치를 추출하기 위해서는 불변성을 가진 로그를 순서대로, 수신 측의 오버플로우 없이 안정적으로 받아줄 수 있는 인프라(예: Kafka)가 반드시 뒷받침되어야 함
4. Kafka의 핵심 철학 및 특징
- 파일 시스템을 활용한 영속성 (Durability)
- 일반적인 메시지 큐는 소비자가 메시지를 읽어가면 큐에서 데이터를 삭제함
- Kafka는 메시지를 디스크(파일 시스템)에 계속해서 추가(Append-only)하는 방식으로 저장
- 이점:
- 소비자가 데이터를 읽어가도 데이터가 사라지지 않으므로,
- 장애가 발생했을 때 과거 특정 시점부터 데이터를 다시 읽어와 복구(Replay)할 수 있음
- 성능 보장:
- 디스크에 순차적 쓰기(Sequential Write) 방식 사용 + OS의 페이지 캐시 적극 활용
- 디스크 기반임에도 메모리 시스템에 준하는 초고속 처리가 가능함
- Pull 기반의 소비자 모델 (Consumer Pull Model)
- 브로커가 소비자에게 데이터를 강제로 밀어 넣는(Push) 구조가 아니라,
- 소비자가 자신의 처리 능력에 맞춰 브로커로부터 데이터를 가져오는(Pull) 구조
- 이점:
- 소스 데이터가 폭발적으로 증가하더라도 수신 측(Consumer) 시스템이 과부하로 다운되는 현상을 방지할 수 있음
- 느슨한 결합 (Decoupling)을 통한 대규모 통합
- 생산자(Producer): 데이터를 받는 상대가 누구인지 알 필요 없이 Kafka 토픽에 데이터를 던지기만 하면 됨
- 소비자(Consumer): 생산자의 상태와 관계없이 원하는 때에 데이터를 가져옴
- 이점:
- \(N:N\) 구조로 얽혀있던 복잡한 데이터 파이프라인 🡲 Kafka를 중심으로 하는 단순한 \(1:N\) 구조로 재편
5. 아키텍처
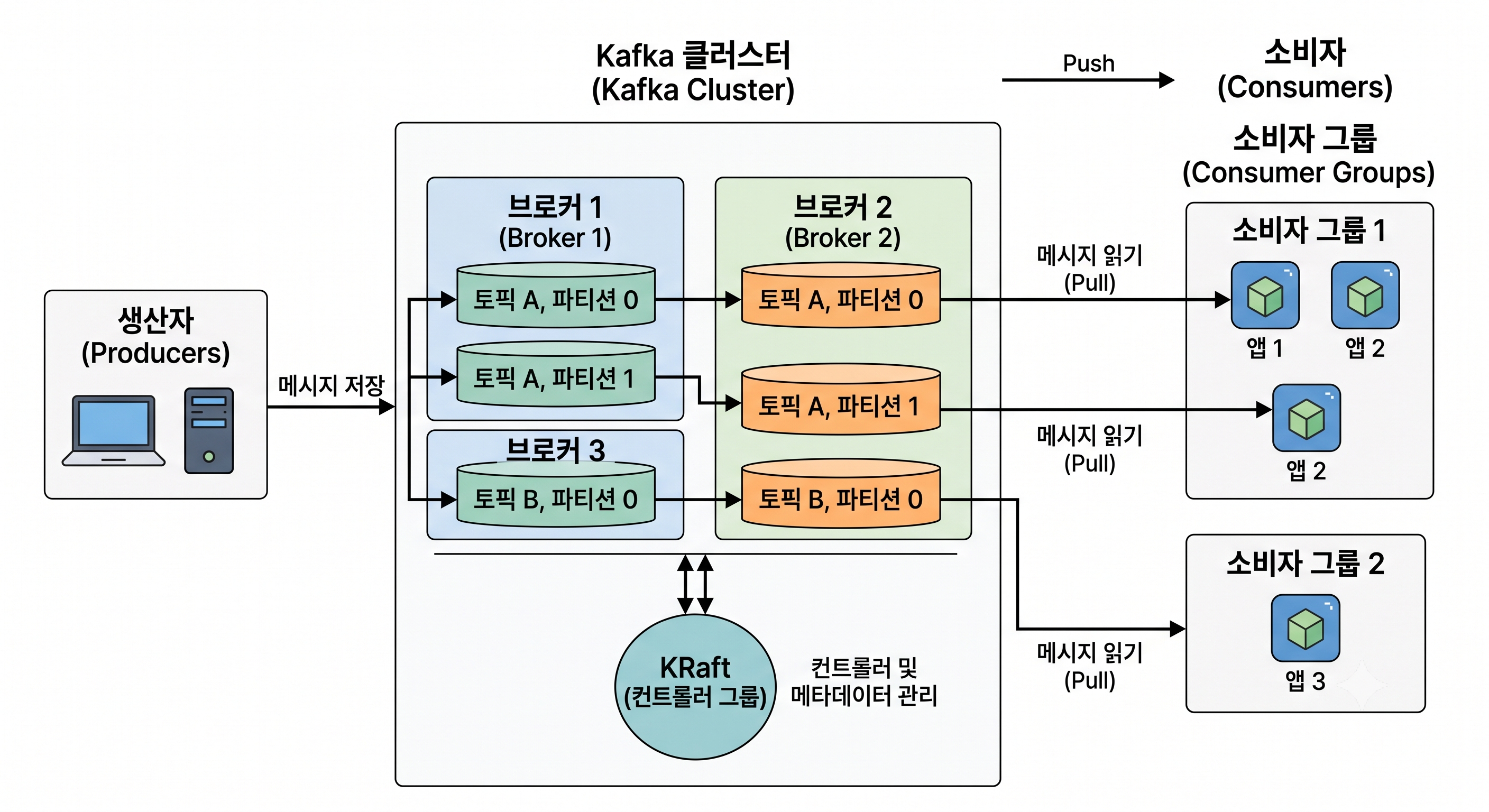
- 생산자(Producers)가 데이터를 생성하여 Kafka 클러스터 내의 브로커들에게 전달하고,
- 클러스터 내부의 토픽과 파티션 구조를 거쳐,
- 소비자 그룹(Consumer Groups)이 데이터를 처리하는 흐름
5.1 아키텍처의 핵심 구성요소 상세 설명
- Kafka 아키텍처는
- 데이터의 생성, 보관, 소비가 철저하게 분리된 구조를 가짐
- 기본적으로 게시-구독(Publish-Subscribe) 모델을 따름
- 생산자 (Producer):
- 이벤트를 발행(Publish)하는 주체 🡲 데이터(이벤트)를 생성하여 Kafka 토픽으로 발행
- 메시지를 보낼 때 어떤 토픽(Topic)으로 보낼지 결정
- 메시지의 키(Key)를 지정해 특정 파티션(Partition)으로 데이터를 고정 전송할 수 있음
- 브로커 (Broker)와 클러스터 (Cluster):
- Kafka 애플리케이션이 실행되는 서버
- 브로커: 하나의 Kafka 서버
- 클러스터: 브로커들이 여러 대 모여 고가용성을 이루는 단위
- 일반적으로 안정성을 위해 3대 이상의 브로커로 클러스터를 구성함
- 브로커들은 데이터를 나누어 저장하고, 서로 복제(Replication) 🡲 하나의 서버가 다운되더라도 데이터가 유실되지 않도록 방어함
- Kafka 애플리케이션이 실행되는 서버
- 토픽 (Topic)과 파티션 (Partition):
- 토픽:
- 데이터가 쌓이는 가상의 논리적 채널 (예:
user-click-logs) - 데이터가 저장되는 카테고리 또는 메일함 같은 개념
- 데이터가 쌓이는 가상의 논리적 채널 (예:
- 파티션:
- 병렬 처리와 부하 분산을 위해 하나의 토픽을 여러 개로 쪼갠 물리적인 파일 단위
- Append-only(추가만 가능) 형태로 운영됨
- 내부에 저장되는 데이터는 고유 번호인 오프셋(Offset)을 부여받아 순서가 고정됨
- 병렬 처리를 가능하게 하고 (단일 파티션 내에서) 데이터의 순서를 보장함
- Offset (오프셋):
- 파티션 내에서 메시지가 가지는 고유한 순서 번호(0, 1, 2, …)
- 소비자는 이 오프셋을 바탕으로 자신이 어디까지 데이터를 읽었는지 기억함
- 토픽:
- 소비자 (Consumer):
- Kafka 토픽에서 데이터를 구독하여(읽어와서) 처리하는 주체
- 여러 소비자를 묶어 소비자 그룹(Consumer Group)을 형성해 병렬 처리를 수행함
- 참고: Consumer와 Application
- 소비자(Consumer)가 곧 우리가 만든 애플리케이션(Application)
- 정확한 관계는 포함관계
- 대부분의 실무 환경에서는 우리가 만든 애플리케이션 내부에 Kafka Consumer 코드가 들어가서 동작하기 때문
- 소비자 (Consumer):
- Kafka 클러스터(브로커)에 접속하여 특정 토픽의 데이터를 읽어오는(Pull) ‘기능적 주체’
- Kafka 라이브러리(Client API)를 코드에 포함하여 호출하는 객체나 프로세스를 뜻함
- Application:
- 개발자가 작성한 ‘프로그램 전체’를 의미
- 가령 스프링 부트(Spring Boot)나 파이썬(Python)으로 만든 서비스 전체가 Application임
- 비유
- Application: 스마트폰 (기기 전체)
- Consumer: 스마트폰 안에서 돌아가는 ‘유튜브 앱’ (데이터를 다운로드하여 보여주는 특정 기능)
- 즉, “데이터를 소비하는 기능을 가진 Application”을 줄여서 그냥 “Consumer”라고 부르는 것
- 구조가 복잡해지면 하나의 애플리케이션 안에 여러 개의 Consumer가 존재할 수 있기 때문에 개념적으로는 분리되어 있음
- 소비자 그룹 (Consumer Group):
- 하나의 목적을 가진 소비자(Application)들을 묶은 그룹
- 토픽의 파티션과 소비자 그룹 내의 소비자를 1:1로 매핑하여 데이터를 분산 처리함
- 만약 소비자 하나가 고장 나면 그룹 내의 다른 소비자가 해당 파티션을 넘겨받아 처리(Rebalancing)함
- KRaft (Kafka Raft 메타데이터 모드):
- 클러스터의 ‘브로커 상태 관리’, ‘리더 브로커 선출’, ‘토픽 생성 정보’ 등의 메타데이터를 관리하는 중추
- 과거에는 별도의 Zookeeper 클러스터가 필요했으나, 현재는 Kafka 내부에서 KRaft 알고리즘을 통해 자체적으로 합의하고 제어함
5.2 데이터의 흐름 및 전체 프로세스 (End-to-End)
- 데이터가 생성되어 최종 소비되는 전체 라이프사이클
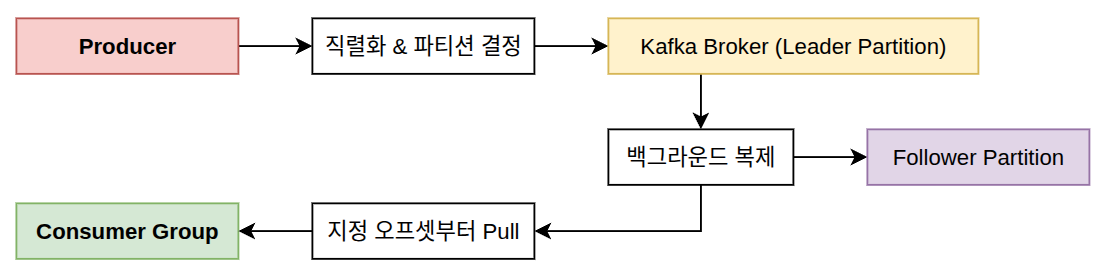
- 발행 (Publish):
- 애플리케이션(Producer)에서 이벤트가 발생하면 설정된
Serializer(예: JSON, String)를 통해 바이트 데이터로 변환됨 - 키(Key)가 있다면 해시 알고리즘을 통해 타겟 파티션이 결정됨
- 애플리케이션(Producer)에서 이벤트가 발생하면 설정된
- 수신 및 저장 (Write):
- 해당 파티션의 리더(Leader) 역할을 하는 브로커가 메시지를 수신
- 브로커는 OS의 페이지 캐시를 거쳐 디스크의 로그 파일 끝에 데이터를 순차적으로 기록(Append-only)
- 복제 (Replication):
- 리더 브로커에 데이터가 쓰여지면,
- 다른 브로커에 위치한 팔로워(Follower) 파티션들이 리더의 데이터를 실시간으로 복제하여 자신의 디스크에 저장
- 소비 (Fetch/Pull):
- 소비자(Consumer)는 자신이 속한 소비자 그룹이 담당하는 파티션에
poll()요청을 발송 - 이때 자신이 마지막으로 읽었던 오프셋(Offset) 번호 다음부터 데이터를 필요한 만큼 가져옴
- 소비자(Consumer)는 자신이 속한 소비자 그룹이 담당하는 파티션에
- 커밋 (Commit):
- 소비자가 데이터를 성공적으로 처리하면,
- “여기까지 읽었다”는 정보를 Kafka의 내부 토픽(
__consumer_offsets)에 기록(Commit)하여 - 다음 번 요청 때 중복 처리가 없도록 만듦
5.3 아키텍처 상의 핵심 특징 및 주요 사항
- 리더(Leader)와 팔로워(Follower)의 역할 분담 (ISR)
- Kafka는 파티션 단위로 고가용성을 보장함
- Leader:
- 모든 읽기와 쓰기 요청은 오직 ‘리더 파티션’하고만 이루어짐
- Follower:
- 리더의 데이터를 그대로 복제만 해두는 복사본
- 리더 브로커가 죽으면 팔로워 중 하나가 즉시 새로운 리더로 승격됨
- ISR (In-Sync Replicas):
- 리더와 정상적으로 동기화를 맞추고 있는 신뢰할 수 있는 팔로워들의 그룹
- 데이터 유실을 막기 위해 ISR 내의 멤버들만 리더 자격을 이어받을 수 있음
- 디스크 기반이지만 초고속인 이유: Page Cache & Zero Copy
- 일반적으로 느리다고 알려진 디스크 I/O를 두 가지 기술로 극복
- Page Cache:
- OS가 남는 메모리를 활용해 디스크 쓰기를 최적화하는 페이지 캐시를 적극 활용
- 사실상 메모리에 쓰고 읽는 것과 비슷한 속도를 냄
- Zero Copy:
- 네트워크로 데이터를 전송할 수 있을 때,
- 커널 공간에서 유저 공간을 거치지 않고 디스크 데이터를 네트워크 버퍼로 다이렉트 전송하여
- CPU 소모와 복사 비용을 극적인 수준으로 줄임
- 완벽한 디커플링 (Decoupling)과 멀티 테넌시
- 전통적인 MQ와 달리 Kafka는 토픽에 데이터가 쌓여있어도 소비자가 읽어가는 속도가 생산자에게 아무런 영향을 주지 않음
- A 소비자 그룹은 실시간 대시보드를 위해 초 단위로 데이터를 가져가고,
- B 소비자 그룹은 데이터 레이크 적재를 위해 10분 단위로 대량 배치 형태로 데이터를 가져가도 Kafka 브로커는 이를 완벽히 독립적으로 지원함
- 전통적인 MQ와 달리 Kafka는 토픽에 데이터가 쌓여있어도 소비자가 읽어가는 속도가 생산자에게 아무런 영향을 주지 않음
- 왜 이런 아키텍처를 선택했을까?
- Kafka의 심플하면서도 분산된 아키텍처는 오직 “초고속 대용량 데이터 처리와 안정성”에 초점이 맞춰져 있음
- 중앙 브로커가 복잡한 연산이나 소비자 관리를 하지 않고 오직 ‘순차적 저장 및 전달’에만 집중하게 만들었기 때문에,
- 수천 대의 서버로 확장해도 병목 현상 없이 실시간 데이터 스트림을 안정적으로 유지할 수 있는 것
6. 장점과 단점
6.1 장점
- 고성능 & 고가용성:
- 초당 수백만 건의 데이터를 처리할 수 있음
- 분산 복제(Replication)를 통해 데이터 손실을 방지함
- 확장성 (Scalability):
- 서비스 중단 없이 브로커를 추가하여 성능과 용량을 선형적으로 확장할 수 있음
- 영속성 (Durability):
- 메시지를 메모리가 아닌 디스크에 저장
- 설정에 따라 데이터를 일정 기간 보관할 수 있어 재처리가 가능함
- 소비자 독립성:
- 여러 소비자 그룹이 서로 다른 속도로 동일한 데이터를 읽어갈 수 있음
6.2 단점
- 운영 복잡도:
- 클러스터 설정, 파티션 최적화, 복제 관리 등 운영 난이도가 높은 편
- 메시지 순서 보장의 제약:
- 토픽 전체의 순서가 아닌, 동일 파티션 내에서만 순서가 보장됨
- 설정의 민감성:
- 처리량과 지연 시간(Latency) 사이의 트레이드오프가 있음
- 환경에 맞는 세밀한 튜닝이 필수적
- 작은 메시지에 최적화:
- 너무 큰 용량의 메시지(예: 수백 MB 파일)를 직접 전송하는 데는 적합하지 않음
7. 주요 사용 목적 및 활용 분야
- 데이터 통합(실시간 로그 및 메트릭 수집):
- 수많은 애플리케이션 서버에서 발생하는 로그, CPU/메모리 사용량 등을 실시간으로 수집하여
- 모니터링 시스템(중앙)으로 전송
- 웹 서비스 활동 추적:
- 유저의 클릭 스트림, 검색 이력, 페이지 뷰 등의 이벤트를 실시간으로 수집하여
- 추천 엔진이나 실시간 분석 시스템에 전달
- 이벤트 기반 아키텍처(MSA)의 중추:
- 마이크로서비스 간에 비동기식으로 데이터를 주고받을 때
- 데이터 정합성과 안정성을 보장하는 메시징 채널로 활용
- CDC (Change Data Capture):
- 데이터베이스의 변경 사항(Insert, Update, Delete)을 실시간으로 감지하여
- 데이터 레이크(Data Lake)나 다른 시스템으로 동기화
- 디커플링(Decoupling):
- 데이터를 보내는 쪽과 받는 쪽의 의존성을 완전히 분리
- 한쪽 시스템의 장애가 전체로 퍼지는 것을 방지
- 실시간 스트림 처리:
- 데이터가 발생하는 즉시 가공, 분석하여 비즈니스 가치를 창출
- 활용도 및 유즈케이스
- 메시징 서비스: 마이크로서비스 아키텍처(MSA) 간의 통신
- 사용자 활동 추적: 웹/앱에서의 클릭 스트림, 페이지 뷰 등을 실시간 수집
- 지표 모니터링: 시스템 호스트의 상태나 애플리케이션 성능 지표 수집 및 알람
- 로그 집계: 여러 서비스의 로그를 한곳으로 모아 Elasticsearch나 HDFS로 전달
- 이벤트 소싱(Event Sourcing): 상태 변화를 이벤트의 시퀀스로 저장하여 데이터 변경 이력을 완벽히 추적
- 요약 및 정리
- Apache Kafka는 “강력한 내구성을 가진 실시간 데이터 배관”이라고 이해할 수 있음
- 대규모 시스템에서 발생하는 방대한 데이터를 막힘없이 흐르게 하고, 시스템 간의 결합도를 낮추어 확장성 있는 아키텍처를 구축하는 데 핵심적인 역할을 수행함