Kafka Connect를 이용한 실시간 데이터의 MinIO 적재
1. Kafka Connect 개요
- Kafka Connect
Apache Kafka의 공식 에코시스템 중 하나
- Kafka와 외부 시스템 간에 데이터를 효율적이고 안전하게 주고받을 수 있도록 표준화된 방법을 제공하는 프레임워크
- 외부 시스템: 데이터베이스, 키-값 저장소, 검색 엔진, 파일 시스템, 클라우드 스토리지 등
- 코드 한 줄 작성하지 않고 (No-Code/Low-Code), 선언적인 JSON 설정 파일만으로 대규모 데이터 파이프라인을 연동할 수 있음
- 과거: 외부 데이터를 카프카로 가져오거나 보낼 때 🡲 직접 Producer와 Consumer 애플리케이션 코드를 자바나 파이썬으로 작성
- Kafka Connect: 반복적인 데이터 이동 작업을 템플릿화 🡲 JSON 설정 파일 하나만으로 데이터 파이프라인을 구동할 수 있도록 정형화
Kafka Connect를 사용하는 핵심 이유 (개발 생산성 및 안정성)
- 개발 생산성과 시스템 안정성을 프레임워크 수준에서 보장받기 위함
Kafka Connect를 쓰지 않고 직접 프로그램을 짜서 MinIO에 저장한다면 🡲 다음 문제들을 코드로 해결해야 함
- 장애 복구(Fail-over):
- 데이터를 저장하던 중 Consumer 프로세스가 죽으면 어느 시점부터 다시 읽어서 저장해야 하는가?
- 분산 처리 및 스케일 아웃:
- 초당 수십만 건의 데이터가 밀려올 때, 여러 프로세스로 어떻게 부하를 분산하고 파티션을 나눠 맡을 것인가?
- 오프셋 관리:
- 데이터가 누락되거나 중복 저장되지 않도록 오프셋 커밋(Commit) 처리를 어떻게 신뢰성 있게 보장할 것인가?
- 장애 복구(Fail-over):
Kafka Connect 프레임워크는 다음과 같은**Offset 자동 관리, , ** 메커니즘을 내장
- 오프셋(Offset) 관리의 자동화:
- 다양한 상태 정보(Offset)를
- “내가 원천 DB 로그를 어디까지 읽었는지”,
- “MinIO 스토리지에 몇 번 메시지까지 저장했는지” 등
- 카프카 내부 메타데이터 토픽에 알아서 저장하고 관리해 줌
- 장애 발생 시 유기적인 Rebalancing
- 시스템이 불시에 뻗어도 데이터 누락이나 중복 없이 멈춘 곳부터 정확히 복구됨
- 다양한 상태 정보(Offset)를
- REST API 기반의 동적 제어:
- 코드를 수정하고 서버를 재빌드할 필요가 없음
8083포트 인터페이스를 통해 JSON 명령어를 보내는 것만으로
🡲 실시간으로 파이프라인을 켜고, 끄고, 설정을 변경할 수 있음
- 파편화된 연동 코드의 통합:
- Task 단위의 자동 부하 분산
- 기업 내에 MySQL, PostgreSQL, S3, Elasticsearch 등 수십 개의 저장소가 존재할 때,
🡲 카프카와 연결하는 코드를 일일이 짜면 유지보수가 불가능해짐 - Kafka Connect는 검증된 플러그인(디비지움 등)을 꽂기만 하면 되므로 인프라가 극도로 단순해짐
- 오프셋(Offset) 관리의 자동화:
- 개발자는 인프라의 안정성을 프레임워크에 맡기고, 오직 데이터의 ‘출발지’와 ‘목적지’ 설정에만 집중할 수 있음
- 개발 생산성과 시스템 안정성을 프레임워크 수준에서 보장받기 위함
2. Kafka Connect의 핵심 구조 및 아키텍처
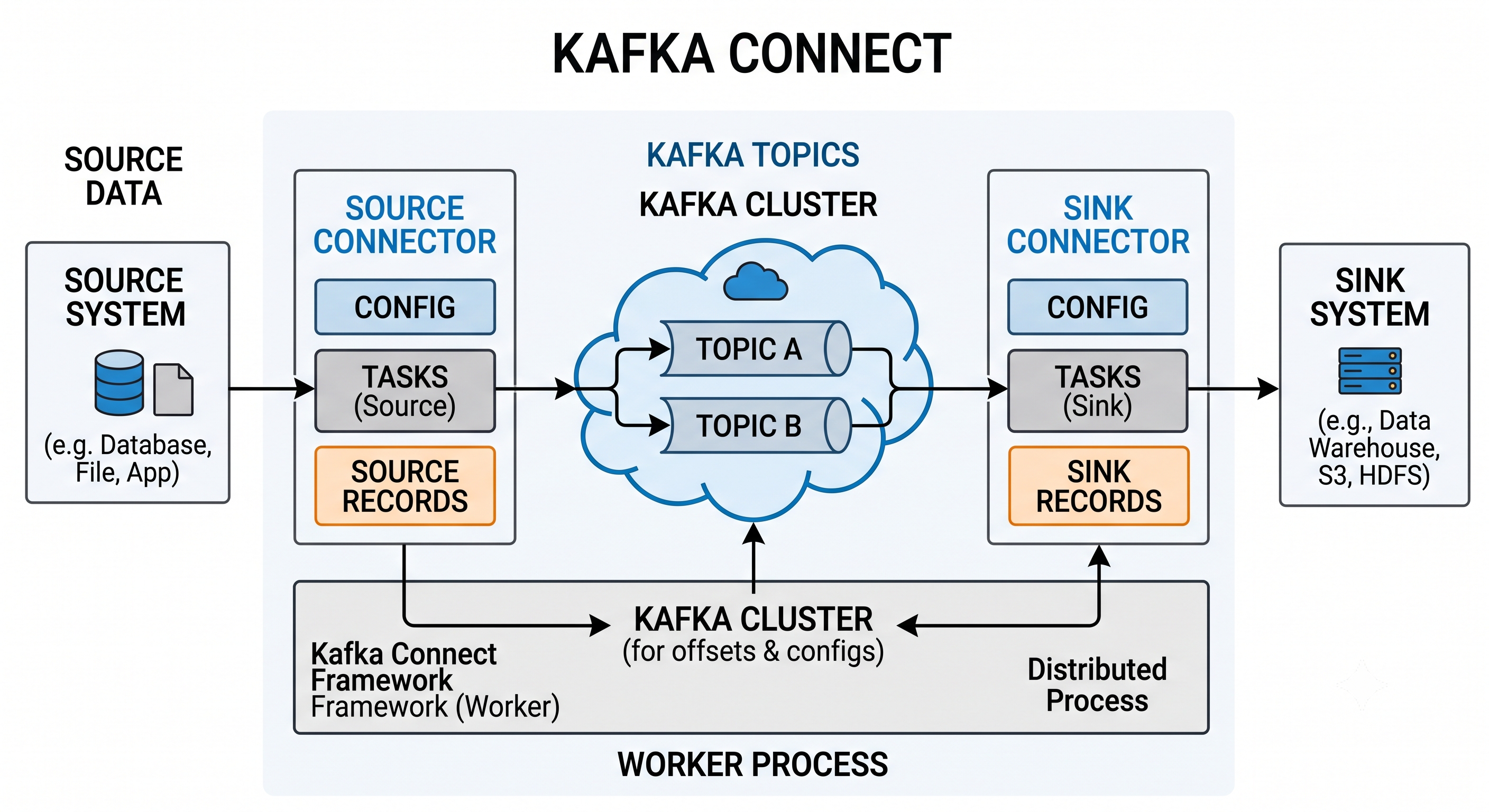
- Kafka Connect가 데이터 소스와 목적지 사이에서 어떻게 데이터를 주고받는지 보여주는 핵심 다이어그램
- Source System (데이터 소스):
- 데이터를 가져올 원천 시스템
- 예: MySQL, PostgreSQL 등의 데이터베이스, 파일 시스템, 애플리케이션 등
- Kafka Connect Framework (Worker):
- 커넥터를 실행하고 관리하는 런타임 환경(서버)
- 그림에서는 전체 프로세스를 감싸는 큰 틀로 표현됨
- Source Connector:
- 소스 시스템에서 데이터를 읽어와 Kafka로 전송하는 커넥터
- 디비지움(Debezium) 같은 CDC 커넥터가 여기에 해당
- Kafka Cluster:
- 데이터가 최종적으로 저장되는 곳
- 토픽(Topic)이라는 저장소에 데이터가 쌓이게 됨
- Sink Connector:
- Kafka 토픽에 저장된 데이터를 읽어와 목적지 시스템으로 전송하는 커넥터
- Sink System (목적지 시스템):
- 데이터를 최종적으로 저장할 시스템
- 예: Data Warehouse, S3, HDFS 등
- 커넥터 (Connector)
- 데이터 파이프라인의 ‘방향성과 규칙’을 정의하는 뇌의 역할
- 어떤 토픽의 데이터를 읽을지, 외부 어떤 DB에 저장할지 등의 메타데이터 설정을 관리 🡲 실질적인 데이터 이동을 지휘
- 데이터가 흐르는 방향에 따라 소스 커넥터와 싱크 커넥터로 분류됨
- Source Connector (수집):
- 외부 시스템(예: MySQL, Oracle, Application Log)의 데이터를 캡처하여 Kafka 토픽으로 밀어 넣는 역할 (생산자 우회)
- 대표적인 소스 커넥터: Debezium CDC
- Sink Connector (적재):
- Kafka 토픽의 데이터를 읽어와 외부 저장소(예: MinIO, S3, Elasticsearch)로 내보내는 역할 (소비자 우회)
- 본 과정에서는 S3/MinIO 전용 Sink Connector를 사용
- Source Connector (수집):
- 태스크 (Task)
- 커넥터가 지휘관이라면, 태스크는 실제로 데이터를 나르는 ‘일꾼 스레드(Thread)’
- 카프카의 파티션 구조와 연계되어 물리적인 데이터 복사 작업을 수행
- 예: 카프카 토픽의 파티션이 3개 🡲 태스크를 최대 3개까지 늘려 파티션 하나씩을 전담 마크하게 함 🡲 병렬 처리(Scale-Out) 달성
- 워커 (Worker)
- 태스크와 커넥터가 실행되는 물리적인 서버 프로세스(컨테이너) 환경
- 단독 모드(Standalone):
- 단 한 대의 프로세스만 띄우는 방식
- 개발 환경이나 단순 파일 백업용으로 사용
- 분산 모드(Distributed):
- 여러 대의 워커를 클러스터로 묶는 방식
- 특정 워커 서버가 죽으면(Fault), 그 안에서 돌던 태스크들을 다른 건강한 워커 서버로 자동으로 이사시키는 고가용성(Fail-over) 메커니즘을 내장
- 실무 표준으로 사용됨
- 컨버터 (Converter)
- 데이터가 국경을 넘을 때 언어를 통역해 주는 ‘번역기’
- 카프카 브로커 내부에서는 데이터를 단순 바이트(Byte) 배열로 저장하지만,
- 외부 DB나 파이썬 애플리케이션은 이를 JSON, Avro, Protobuf 등의 구조화된 포맷으로 읽어야 함
- 컨버터가 중간에서 이 직렬화(Serialization) 및 역직렬화 작업을 자동으로 수행
- 데이터가 국경을 넘을 때 언어를 통역해 주는 ‘번역기’
- Kafka Connect는
- “카프카와 외부 저장소 사이를 연결하는 No-Code 기반의 분산 데이터 셔틀 버스”
- 분산 아키텍처 특유의 복잡한 장애 복구, 병렬 처리, 분산 잠금 메커니즘을 백엔드 깊숙이 숨겨두고,
- 엔지니어에게는 “오직 출발지와 목적지만 명시하면 데이터는 우리가 안전하게 나르겠다”는 인터페이스를 제공하는 도구
- 이 인프라가 갖춰져야 비로소 엔드투엔드(End-to-End) 실시간 데이터 레이크 파이프라인이 완성됨
3. 실시간 데이터 MinIO 적재 아키텍처 및 관련 기술
- 실습에서 구현할 실시간 스트리밍 데이터 파이프라인의 전체 아키텍처
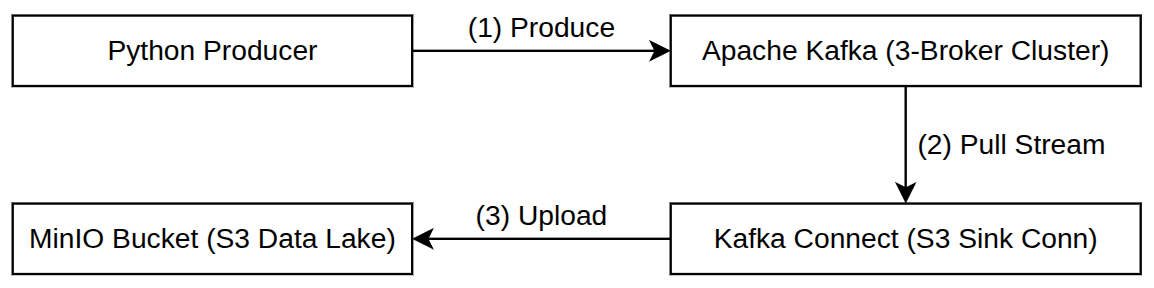
- 관련 기술 구성 요소 설명
- Apache Kafka (3-Broker Cluster):
- 데이터 고속도로 역할을 수행
- 주키퍼 없이 KRaft 모드로 자율 제어되는 3대의 브로커 시스템
- MinIO:
- 오픈소스 기반의 고성능 오브젝트 스토리지(Object Storage)
- AWS S3와 완전히 동일한 API 규격을 공유
- 로컬 환경에서 AWS S3 데이터 레이크 인프라를 그대로 시뮬레이션할 수 있는 표준 도구
- Camel-S3 Sink Connector:
- Apache Camel 프로젝트에서 제공하는 S3 호환 전용 싱크 커넥터
- Kafka 토픽에 들어오는 메시지를 낚아채어 지정된 분량(시간 또는 개수 크기)만큼 묶어서 MinIO 버킷에 파일 형식으로 자동 업로드함
- Apache Kafka (3-Broker Cluster):
4. 실습 예제
- 아파치 공식 Kafka 클러스터 위에 MinIO와 Kafka Connect 인프라를 결합하고, 파이썬을 이용해 데이터를 흘려보내는 전 과정
- debezium/connect:2.4 이미지에는 MinIO(S3)와 연동할 수 있는 S3 Sink 커넥터 플러그인이 포함되어 있지 않음
🡲 debezium/connect 이미지를 베이스로, Confluent S3 Sink 커넥터 같은 플러그인을 수동으로 설치, Docker 이미지를 빌드하여 사용함- Confluent S3 Sink 커넥터는 유료화 정책에 의해 Self-Hosted 버전을 공식 사이트에서 직접 다운로드해야 함(Curl 사용 불가)
- [1단계] 복합 인프라 환경 구축
기존의 3-브로커 설정 아래에 MinIO와 Kafka Connect 서비스를 통합
환경 구축을 위한
docker-compose.ymlservices: # ----------------------------------------------------------------- # 1. Kafka 3-브로커 클러스터 (내/외부 리스너 완벽 분리) # ----------------------------------------------------------------- kafka-1: image: apache/kafka:latest container_name: kafka-1 ports: - "9092:9092" environment: - KAFKA_NODE_ID=1 - KAFKA_PROCESS_ROLES=broker,controller - KAFKA_LISTENERS=INTERNAL://:19092,EXTERNAL://:9092,CONTROLLER://:9093 - KAFKA_ADVERTISED_LISTENERS=INTERNAL://kafka-1:19092,EXTERNAL://localhost:9092 - KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT,CONTROLLER:PLAINTEXT - KAFKA_INTER_BROKER_LISTENER_NAME=INTERNAL - KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER - KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093 - KAFKA_LOG_DIRS=/var/lib/kafka/data volumes: - kafka_1_data:/var/lib/kafka/data kafka-2: image: apache/kafka:latest container_name: kafka-2 ports: - "9094:9092" environment: - KAFKA_NODE_ID=2 - KAFKA_PROCESS_ROLES=broker,controller - KAFKA_LISTENERS=INTERNAL://:19092,EXTERNAL://:9094,CONTROLLER://:9093 - KAFKA_ADVERTISED_LISTENERS=INTERNAL://kafka-2:19092,EXTERNAL://localhost:9094 - KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT,CONTROLLER:PLAINTEXT - KAFKA_INTER_BROKER_LISTENER_NAME=INTERNAL - KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER - KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093 - KAFKA_LOG_DIRS=/var/lib/kafka/data volumes: - kafka_2_data:/var/lib/kafka/data kafka-3: image: apache/kafka:latest container_name: kafka-3 ports: - "9095:9092" environment: - KAFKA_NODE_ID=3 - KAFKA_PROCESS_ROLES=broker,controller - KAFKA_LISTENERS=INTERNAL://:19092,EXTERNAL://:9095,CONTROLLER://:9093 - KAFKA_ADVERTISED_LISTENERS=INTERNAL://kafka-3:19092,EXTERNAL://localhost:9095 - KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT,CONTROLLER:PLAINTEXT - KAFKA_INTER_BROKER_LISTENER_NAME=INTERNAL - KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER - KAFKA_CONTROLLER_QUORUM_VOTERS=1@kafka-1:9093,2@kafka-2:9093,3@kafka-3:9093 - KAFKA_LOG_DIRS=/var/lib/kafka/data volumes: - kafka_3_data:/var/lib/kafka/data # ----------------------------------------------------------------- # 2. Kafka Connect 엔진 (Debezium 베이스 + Confluent S3 커스텀 빌드) # ----------------------------------------------------------------- kafka-connect: build: context: . dockerfile: Dockerfile container_name: kafka-connect ports: - "8083:8083" environment: - BOOTSTRAP_SERVERS=kafka-1:19092,kafka-2:19092,kafka-3:19092 - GROUP_ID=1 - CONFIG_STORAGE_TOPIC=my_connect_configs - OFFSET_STORAGE_TOPIC=my_connect_offsets - STATUS_STORAGE_TOPIC=my_connect_statuses - CONFIG_STORAGE_REPLICATION_FACTOR=1 - OFFSET_STORAGE_REPLICATION_FACTOR=1 - STATUS_STORAGE_REPLICATION_FACTOR=1 - CONNECT_KEY_CONVERTER=org.apache.kafka.connect.json.JsonConverter - CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE=false - CONNECT_VALUE_CONVERTER=org.apache.kafka.connect.json.JsonConverter - CONNECT_VALUE_CONVERTER_SCHEMAS_ENABLE=false depends_on: - kafka-1 - kafka-2 - kafka-3 # ----------------------------------------------------------------- # 3. Object Storage 백업 인프라 # ----------------------------------------------------------------- minio: image: minio/minio:RELEASE.2024-01-11T07-46-16Z container_name: minio ports: - "9000:9000" # API 엔드포인트 - "9001:9001" # 웹 GUI 콘솔 environment: - MINIO_ROOT_USER=minioadmin - MINIO_ROOT_PASSWORD=minioadmin command: server /data --console-address ":9001" volumes: - minio_data:/data volumes: kafka_1_data: kafka_2_data: kafka_3_data: minio_data:
커스텀 빌드를 위한
DockerfileFROM debezium/connect:2.4 # 파일 주입 및 압축 해제를 위해 root 권한 고정 USER root ENV KAFKA_CONNECT_PLUGINS_DIR="/kafka/connect" # 브라우저로 직접 다운로드한 12.1.6 최신 정품 패키지를 엔진 내부로 주입 COPY confluentinc-kafka-connect-s3-12.1.6.zip . # 내부 압축 해제 시퀀스 작동 후 잔여 파일 완전 박멸 RUN unzip confluentinc-kafka-connect-s3-12.1.6.zip -d $KAFKA_CONNECT_PLUGINS_DIR && \ rm confluentinc-kafka-connect-s3-12.1.6.zip # 실습 편의와 볼륨 매핑 권한 프리패스를 위해 root 유지
터미널에서 아래 명령어로 모든 인프라를 구동
docker compose up -d --build
[2단계] MinIO 웹 버킷(Bucket) 생성 및 확인
- 브라우저를 열고
http://localhost:9001에 접속 - ID:
minioadmin/ PW:minioadmin을 입력하여 대시보드에 로그인 - [Create Bucket] 버튼을 클릭하여 데이터가 적재될 공간인
telemetry-data-lake라는 이름의 버킷을 생성
- 브라우저를 열고
[3단계] Kafka Connect에 MinIO Sink Connector 등록하기
- Kafka Connect의 REST API 포트(
8083)로 JSON 명세서 발송 - “카프카의
minio-stream-topic에 들어오는 데이터를 실시간으로 감시해서 MinIO 버킷으로 전송”하는 명령호스트 PC 터미널 창에서 다음
curl명령어 실행curl -X POST -H "Content-Type: application/json" --data '{ "name": "minio-sink-connector", "config": { "connector.class": "io.confluent.connect.s3.S3SinkConnector", "tasks.max": "1", "topics": "minio-clean-topic", "s3.region": "us-east-1", "s3.bucket.name": "telemetry-data-lake", "s3.part.size": "5242880", "flush.size": "1", "behavior.on.null.values": "ignore", "errors.tolerance": "all", "storage.class": "io.confluent.connect.s3.storage.S3Storage", "format.class": "io.confluent.connect.s3.format.json.JsonFormat", "schema.compatibility": "NONE", "store.url": "http://minio:9000", "aws.access.key.id": "minioadmin", "aws.secret.access.key": "minioadmin" } }' http://localhost:8083/connectors- 핵심 설정
- connector.class
- 수동 설치한 Confluent S3 Sink Connector의 핵심 클래스명 명시
- topics
- 실시간 감시 및 데이터 수집 대상인 카프카 토픽 이름 명시 (minio-clean-topic)
- s3.bucket.name
- 데이터를 최종 적재할 오브젝트 스토리지(MinIO)의 대상 버킷 이름 매핑 (telemetry-data-lake)
- store.url
- 외부 AWS S3가 아닌,
- 도커 가상망 안에 독립적으로 가동 중인 로컬 MinIO 서버 주소(http://minio:9000)로 우회 지정
- flush.size
- 카프카 토픽에 이벤트 데이터가 딱 1개 인입될 때마다
- 지연 없이 MinIO 버킷 내부로 즉시 플러시(Commit)하여
- 실시간 파일 생성을 보장하도록 설정 (실습 및 디버깅 최적화)
- format.class
- 카프카의 바이너리 레코드 스트림을
- 가독성이 높고 다루기 쉬운 순수 JSON 파일 포맷으로 변환하여
- 버킷에 저장하도록 지정
- behavior.on.null.values (추가)
- 프로듀서 종료 시나리오 등에서 발생할 수 있는 알맹이 없는 빈 메시지(Null Valued Record / Tombstone)를 만났을 때,
- 파이프라인이 중단되지 않고 부드럽게 무시(ignore)하고 넘어가도록 설정
- errors.tolerance (추가)
- 입력 프롬프트 기호 중복 등 데이터 포맷 문법이 완전히 깨진 불량 메시지가 유입되더라도,
- 커넥터 태스크가 FAILED로 뻗지 않고 유연하게 무시(all)하며
- 정상 데이터 스트림을 유지하도록 실무형 예외 처리 정의
- connector.class
예상 결과
{ "name":"minio-sink-connector", "config":{ "connector.class":"io.confluent.connect.s3.S3SinkConnector", "tasks.max":"1", "topics":"minio-clean-topic", "s3.region":"us-east-1", "s3.bucket.name":"telemetry-data-lake", "s3.part.size":"5242880", "flush.size":"1", "behavior.on.null.values":"ignore", "errors.tolerance":"all", "storage.class":"io.confluent.connect.s3.storage.S3Storage", "format.class":"io.confluent.connect.s3.format.json.JsonFormat", "schema.compatibility":"NONE", "store.url":"http://minio:9000", "aws.access.key.id":"minioadmin", "aws.secret.access.key":"minioadmi" } }
- 핵심 설정
- 커넥터 가동 상태 최종 점검
등록 후 일꾼(Task)이 크래시 없이 정상적으로 루프를 돌고 있는지 확인
curl -s http://localhost:8083/connectors/minio-sink-connector/status | json_pp예상 결과
{ "connector" : { "state" : "RUNNING", "worker_id" : "172.18.0.6:8083" }, "name" : "minio-sink-connector", "tasks" : [ { "id" : 0, "state" : "RUNNING", "worker_id" : "172.18.0.6:8083" } ], "type" : "sink" }
실시간 데이터 스트리밍 시험
docker exec -it kafka-1 /opt/kafka/bin/kafka-console-producer.sh --bootstrap-server kafka-1:19092 --topic minio-clean-topic> {"device_id": "sensor_01", "temperature": 22.1, "status": "OK"} > {"device_id": "sensor_02", "temperature": 85.4, "status": "EMERGENCY"} > 아무 문자열이나 막 입력 (엔터) >- (완료 후 Ctrl+C로 탈출)
- MinIO 대시보드 심사
- http://localhost:9001 대시보드 새로고침
- flush.size: 1 규칙에 의해 메시지를 쏠 때마다 실시간으로 파티션 폴더 안에 *.json 정품 물리 파일들이 개수대로 적재되어 있는 모습을 확인
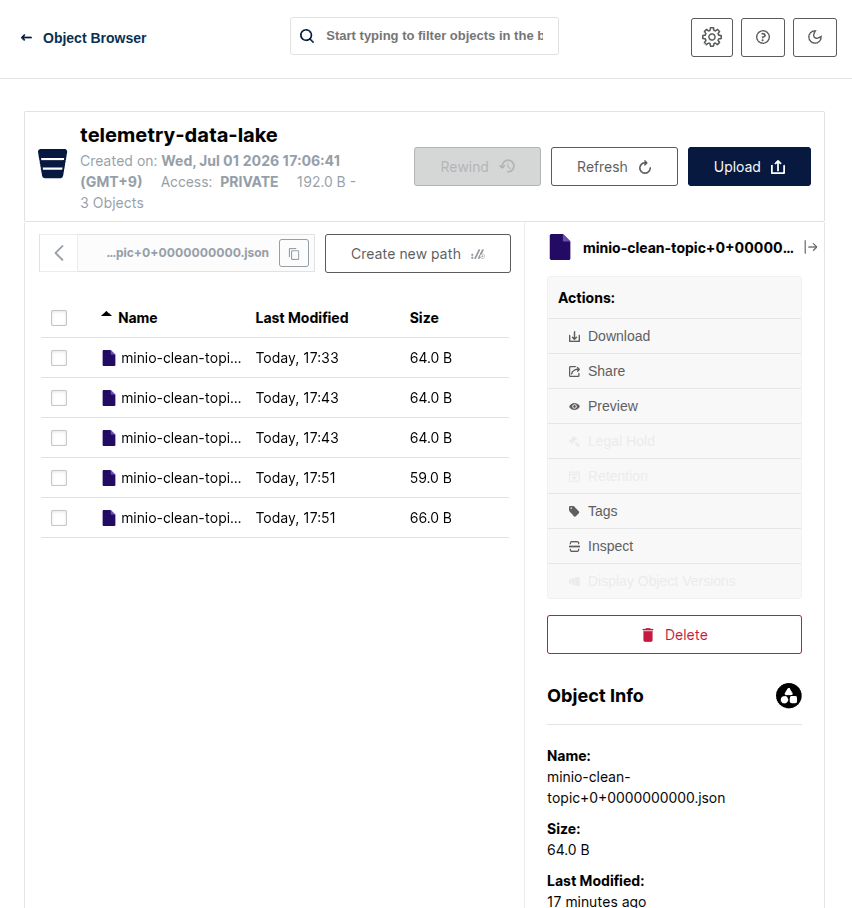
- Kafka Connect의 REST API 포트(
[4단계] 파이썬 실시간 시뮬레이터 구동 (
stream_producer.py)- 원천 데이터를 생성할 파이썬 시뮬레이터 가동
가상환경이 켜진 호스트 쉘에서
stream_producer.py파일 실행#//file: "stream_producer.py" import time import json import random from kafka import KafkaProducer # 호스트 PC 가상망 포트 규격에 맞춰 클러스터 엔트리포인트 지정 producer = KafkaProducer( bootstrap_servers=["localhost:9092"], value_serializer=lambda v: json.dumps(v).encode('utf-8') ) # 새로 교정된 스키마 프리패스 전용 토픽 지정 topic_name = "minio-clean-topic" print(f"[시뮬레이터 가동] '{topic_name}'으로 초당 5개씩 IoT 센서 데이터를 전송합니다.\n") try: while True: sensor_data = { "device_id": f"SENSOR-{random.randint(1, 5)}", "temperature": round(random.uniform(20.0, 35.5), 2), "humidity": round(random.uniform(40.0, 60.0), 2), "timestamp": time.time() } producer.send(topic_name, value=sensor_data) print(f"데이터 전송 -> ID: {sensor_data['device_id']} | Temp: {sensor_data['temperature']}°C") time.sleep(0.2) # 0.2초당 1개씩 (초당 5개 고속 발행) except KeyboardInterrupt: print("\n전송을 중단합니다.") finally: producer.flush() producer.close()
- 원천 데이터를 생성할 파이썬 시뮬레이터 가동
최종 결과 검증 및 총평
파이썬 코드 스크립트 가동 🡲 터미널 창에
데이터 전송로그가 쌓이기 시작
🡲 MinIO 대시보드 브라우저(http://localhost:9001) 접속telemetry-data-lake버킷 내부로 진입- Confluent S3 규격에 따라 자동 생성된 topics/minio-clean-topic/partition=0/ 구조의 클린 데이터 레이크 디렉토리 뼈대 확인
- 디렉토리 내부 진입 🡲 실시간 카프카 오프셋 번호를 기반으로 명명된 데이터 파일들(.json)이 유실없이 초고속으로 동기화 적재됨을 확인
- 별도의 유저 적재 코드를 한 줄도 작성하지 않았음에도 불구하고, 카프카 커넥트(Kafka Connect) 엔진의 선언형 설정만으로 대규모 인입 데이터가 오브젝트 스토리지로 완벽하게 자동 정착됨을 확인할 것
- 파이프라인 완성 총평:
- 이벤트 스트림의 무결한 정착:
- 원천 시뮬레이터 생산자로부터 초당 5개씩 뿜어져 나온 대량의 IoT 센서 이벤트가
- 자율형 분산 Kafka 브로커 클러스터의 분산 큐를 통과하고,
- 실무형 인프라 레벨 튜닝 체득:
- 스키마 검증 필터(schemas.enable=false) 및 불량 데이터 예외 쉴드(errors.tolerance=all) 처리가 완료된
- 고가용성 Kafka Connect 엔진의 정밀 제어를 받아,
- 엔터프라이즈 데이터 레이크 완성:
- 최종 클라우드 스토리지 규격인 MinIO 파일 아키텍처 내부에 실시간으로 안전하게 안착하는
- 엔드투엔드(End-to-End) 데이터 고속도로 개통 완수
- 실시간 인메모리 대용량 데이터 레이크 수집 아키텍처를 통제하고 독자적으로 빌드하는 실무 핵심 역량 확보