MinIO – Iceberg 데이터 파이프라인 구축
- MinIO와 Apache Iceberg를 결합한 데이터 파이프라인
- 현대적인 데이터 엔지니어링에서 가장 주목받는 ‘오픈 레이크하우스(Open Lakehouse)’ 아키텍처의 표준 모델
- 비싸고 유연성이 떨어지는 전통적인 데이터 웨어하우스(DW) 대신,
- 오픈소스 기반의 고성능 스토리지와 테이블 포맷을 엮어 비용 효율적이면서도 강력한 트랜잭션을 보장하는 데이터 인프라를 구축할 수 있음
1. 개념 설명 및 두 도구의 연관성
- 왜 MinIO인가? (오픈 데이터 레이크)
- MinIo는
- 대규모 고성능 프라이빗 클라우드 인프라를 위한 오픈소스 오브젝트 스토리지
- AWS S3 API와 100% 호환됨
- 파일 시스템(HDFS)과 달리 비정형·반정형 데이터를 페타바이트(PB) 규모로 저렴하고 안전하게 저장할 수 있음
- 데이터 레이크의 물리적 저장소 역할 수행
- MinIo는
- 왜 Apache Iceberg인가? (트랜잭션 계층)
- 오브젝트 스토리지는 본질적으로 ‘단순히 파일을 밀어 넣는 공간’일 뿐
- 데이터 수정/삭제가 어렵고, 여러 컴포넌트가 동시에 접근하면 데이터가 꼬임
- Iceberg는
- MinIO 위에서 작동
- “RDBMS처럼 테이블 단위 관리, ACID 트랜잭션 보장, 고속 인덱싱(Data Skipping)”을 가능하게 만드는 테이블 규격(Table Format)
- 두 도구의 연관성 및 시너지
- 디스크와 OS의 관계:
- MinIO가 하드디스크(물리적 저장 공간)라면,
- Iceberg는 파일을 논리적으로 관리하고 주소를 지정해 주는 파일 시스템(예: NTFS, ext4)
- 스토리지와 컴퓨팅의 분리:
- MinIO + Iceberg 구조를 가져가면
- 데이터는 한곳(MinIO)에 안전하게 묶여 있고,
- 데이터를 처리하는 엔진(Spark, DuckDB, Flink 등)은 필요에 따라 자유롭게 붙였다 뗄 수 있는
- 완벽한 엔진 독립성을 확보하게 됨
- MinIO + Iceberg 구조를 가져가면
- 디스크와 OS의 관계:
2. 아키텍처 및 핵심 기술
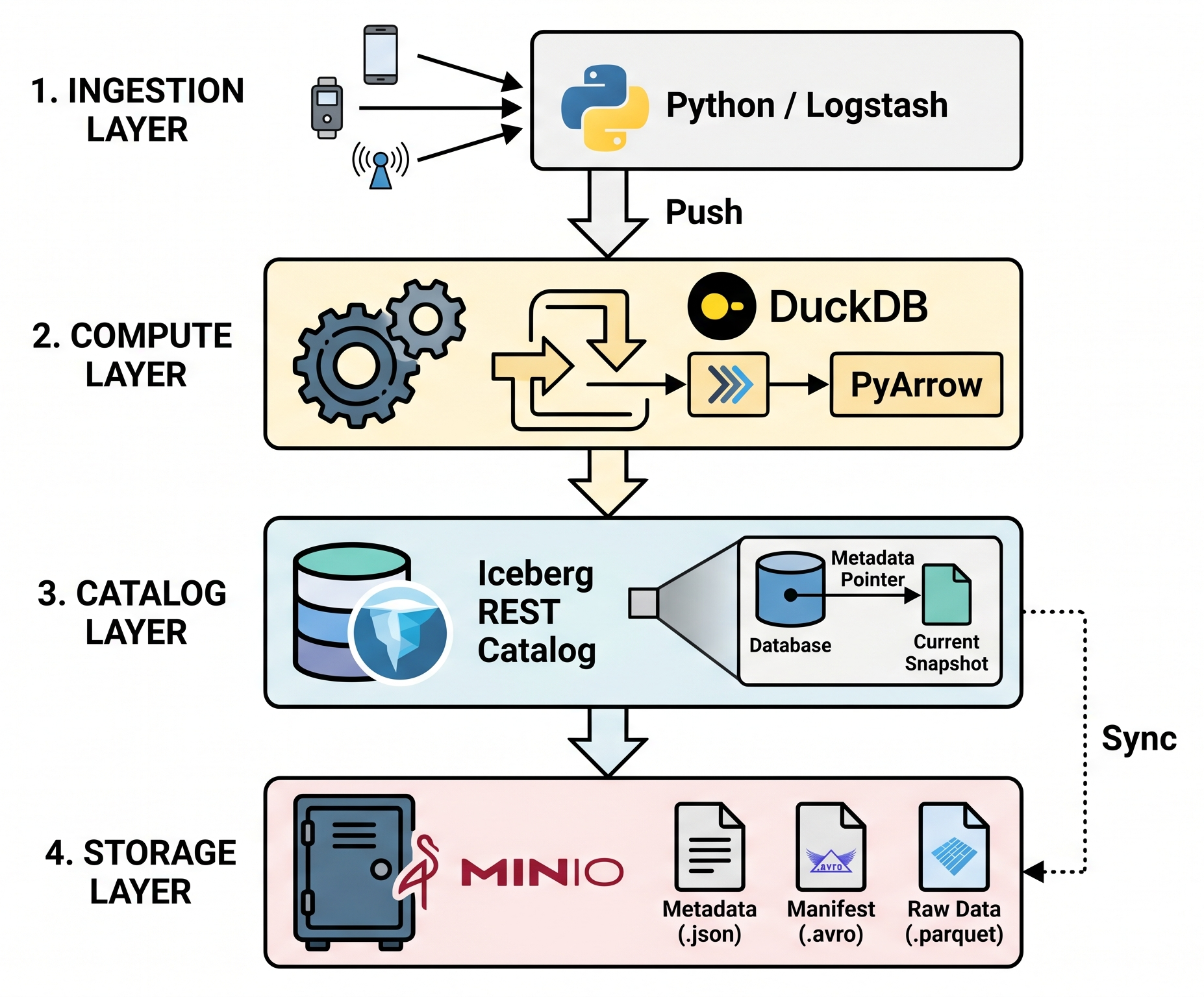
- 데이터 소스 (Ingestion Layer):
- 소스 데이터를 파이프라인으로 밀어 넣어주는 주체 (Python, Logstash 등)
- 컴퓨팅/쿼리 엔진 (Compute Layer):
- 데이터 분석 및 변환을 수행하는 가벼운 OLAP 엔진 (DuckDB, PyArrow)
- 메타데이터 카탈로그 (Catalog Layer):
- 외부 자바 서버의 결함과 간섭을 차단하기 위해
- 파이썬 프로세스 내장형 가상 데이터베이스 원장(Embedded SQL Catalog)을 채택
- 현재 최신 스냅샷 위치를 물리 파일(.db)에 포인터로 쥐고 통제함
- 오브젝트 스토리지 (Storage Layer):
- 최하단에서 실제 메타데이터 파일(
.json,.avro)과 원시 데이터 파일(.parquet)을 영구 보관하는 MinIO
- 최하단에서 실제 메타데이터 파일(
3. 데이터 파이프라인 연동 환경 설정
- 엔지니어링 환경을 독립적이고 무결하게 검증하기 위해
- 불투명한 자바 카탈로그 컨테이너를 도려내고,
오직 순수 S3 호환 스토리지 본연의 인프라 뼈대만 도커로 연동
docker-compose.yml파일 작성version: '3.8' services: # 1. 뼈대 저장소: MinIO minio: image: minio/minio:latest container_name: pipeline-minio ports: - "9000:9000" - "9001:9001" environment: - MINIO_ROOT_USER=pipeline_admin - MINIO_ROOT_PASSWORD=pipeline_password command: server /data --console-address ":9001" # MinIO 초기 버킷 생성 유틸 mc: image: minio/mc:latest container_name: pipeline-minio-mc depends_on: - minio entrypoint: > /bin/sh -c " until (/usr/bin/mc alias set myminio http://minio:9000 pipeline_admin pipeline_password); do echo 'Waiting for MinIO...'; sleep 1; done; /usr/bin/mc mb myminio/telemetry-lake; exit 0;"- 터미널 실행 명령어:
docker-compose up -d - 필수 파이썬 라이브러리:
pip install "pyiceberg[s3fs,pyarrow]" duckdb- 자바 카탈로그 서버 없이
- 파이썬 내장에서 자체적으로 SQL 데이터베이스 원장을 트랜잭션 제어할 수 있도록
- SQLAlchemy 코어를 주입하는
[sql-sqlite]확장 팩 필수 적용
4. 데이터 파이프라인 시나리오 및 통합 예제 코드
- [시나리오]
- 스마트시티의 교량/도로에 설치된 붕괴 위험 감지 IoT 센서 데이터 파이프라인 구축
- 1차 적재 (Batch 1): 정상 작동 중인 센서 로그 데이터가 파이프라인을 통해 들어옴
- 2차 적재 (Batch 2): 특정 시점에 위험 징후를 나타내는 급격한 변동 데이터가 유입됨
- 가상 DW 분석: 고속 OLAP 엔진(DuckDB)을 연동해 이상 징후 센서를 즉시 격리 추출하는 SQL 파이프라인을 구동
- 타임 트래블 분석: 분석가는 사고 발생 이전 상태(스냅샷 V1)의 데이터와 현재 상태를 교차 검증
import datetime
import pyarrow as pa
from pyiceberg.catalog import load_catalog
from pyiceberg.exceptions import NamespaceAlreadyExistsError, TableAlreadyExistsError # 멱등성 방어 클래스 수혈
import duckdb
# =========================================================================
# [단계 1] 연동 설정 - PyIceberg를 통한 MinIO 및 내장 SQL 카탈로그 결합 [전면 수정]
# =========================================================================
print("1. MinIO 스토리지 및 내장 SQL 가상 카탈로그 직접 연결 파이프라인 초기화...")
# 외부 자바 서버의 네트워크 이탈 현상을 방지하기 위해 로컬 상대경로 파일로 메타데이터 원장 관리
catalog = load_catalog(
"city_telemetry_catalog",
**{
"type": "sql",
"uri": "sqlite:///iceberg_catalog.db", # 실행 위치에 무결한 원장 데이터베이스 파일 빌드
"warehouse": "s3://telemetry-lake", # 물리 데이터가 적재될 MinIO 버킷 경로 지정
"s3.endpoint": "http://localhost:9000", # 호스트에서 도커 스토리지로 직격하는 인터페이스 통로
"s3.path-style-access": "true",
"s3.access-key-id": "pipeline_admin",
"s3.secret-access-key": "pipeline_password",
"py-io-impl": "pyiceberg.io.pyarrow.PyArrowFileIO"
}
)
# 네임스페이스(DB 구조) 중복 생성 예외 방어
try:
catalog.create_namespace("infrastructure")
print(" └ 네임스페이스(infrastructure) 신규 생성 완료!")
except NamespaceAlreadyExistsError:
print(" └ 네임스페이스가 이미 존재하므로 다음 단계로 진행합니다.")
bridge_schema = pa.schema([
("bridge_id", pa.string()),
("vibration_level", pa.float64()),
("stress_index", pa.float64()),
("status", pa.string()),
("checked_at", pa.timestamp('us', tz='UTC'))
])
# Iceberg 파이프라인 테이블 중복 생성 예외 방어 및 원장 로드 멱등성 확보
try:
table = catalog.create_table(
identifier="infrastructure.bridge_telemetry",
schema=bridge_schema
)
print(" └ Iceberg 테이블 신규 생성 완료. (MinIO 버킷 내 메타데이터 트리 루트 확보)")
except TableAlreadyExistsError:
table = catalog.load_table("infrastructure.bridge_telemetry")
print(" └ 기존에 생성된 Iceberg 테이블 파이프라인 원장을 안전하게 로드했습니다.")
# =========================================================================
# [단계 2] 데이터 유입 (Batch 1 - 정상 주기 데이터 파이프라인)
# =========================================================================
print("\n2. [Batch 1] 사물인터넷(IoT) 센서 주기 데이터 파이프라인 구동...")
batch_1_raw = {
"bridge_id": ["BRG-01", "BRG-02", "BRG-01", "BRG-03"],
"vibration_level": [1.2, 0.8, 1.5, 2.1],
"stress_index": [10.5, 8.2, 11.1, 14.0],
"status": ["STABLE", "STABLE", "STABLE", "STABLE"],
"checked_at": [datetime.datetime.now(datetime.timezone.utc) for _ in range(4)]
}
# 고속 파일 처리를 위해 PyArrow 레코드셋 변환
batch_1_arrow = pa.Table.from_pydict(batch_1_raw)
# MinIO에 파일 쓰기 및 커밋 동시 수행
table.append(batch_1_arrow)
print("Batch 1 데이터가 실시간 적재되었습니다. (스냅샷 ID 갱신 완료 - Snapshot V1)")
# =========================================================================
# [단계 3] 데이터 유입 (Batch 2 - 이상 데이터 감지 및 누적 적재)
# =========================================================================
print("\n3. [Batch 2] 교량 센서 이상 진동 데이터 실시간 유입 트래킹...")
batch_2_raw = {
"bridge_id": ["BRG-01", "BR4"],
"vibration_level": [8.9, 1.1], # BRG-01 센서의 위험 수치 급증
"stress_index": [78.4, 9.0],
"status": ["DANGER", "STABLE"],
"checked_at": [datetime.datetime.now(datetime.timezone.utc) for _ in range(2)]
}
batch_2_arrow = pa.Table.from_pydict(batch_2_raw)
# 추가 커밋 발생 (기존 데이터와 완전 격리된 새 스냅샷 파일 생성)
table.append(batch_2_arrow)
print("Batch 2 데이터 적재 완료. (안전하게 트랜잭션 격리됨 - Snapshot V2)")
# =========================================================================
# [단계 4] 데이터 레이크하우스 쿼리 분석 파이프라인 (DuckDB 연동)
# =========================================================================
print("\n4. 고속 DW 엔진(DuckDB) 가속화를 통한 분석 파이프라인 작동...")
# Iceberg가 메타데이터를 기반으로 최신 유효 파켓 파일 구조만 스캔
latest_lakehouse_view = table.scan().to_arrow()
# DuckDB를 사용하여 제로카피 고속 분석 쿼리 수행
db_client = duckdb.connect(database=':memory:')
print("\n[분석 리포트 1] 실시간 교량 상태별 평균 스트레스 지수 점검:")
m_query1 = """
SELECT status, COUNT(*) as log_count, ROUND(AVG(stress_index), 2) as avg_stress
FROM latest_lakehouse_view
GROUP BY status;
"""
# [문법 교정] execute().show() 문법 결함을 표준 Pandas 데이터프레임 구조인 execute().df() 포맷으로 치환 출력
print(db_client.execute(m_query1).df())
# =========================================================================
# [단계 5] 오염 역추적을 위한 파이프라인 타임 트래블
# =========================================================================
print("\n5. 파이프라인 역추적 검증: 이상 징후가 보고되기 전(Batch 1) 시점으로 롤백 쿼리...")
# 변경 이력 트랙커 가동
pipeline_history = table.history()
initial_version_id = pipeline_history[0].snapshot_id
# 과거 스냅샷 기준 파일 필터링 로드
past_lakehouse_view = table.scan(snapshot_id=initial_version_id).to_arrow()
print(f"\n[분석 리포트 2] 초기 버전(Snapshot: {initial_version_id}) 내부 DANGER 로그 건수:")
m_query2 = "SELECT COUNT(*) as danger_count FROM past_lakehouse_view WHERE status = 'DANGER';"
# [문법 교정] execute().show() 문법 결함을 표준 execute().df() 포맷으로 치환 출력
print(db_client.execute(m_query2).df())
- 파이프라인 핵심 메커니즘
- 위의 연동 코드와 아키텍처가 실제 백엔드(MinIO 내부)에서 동작할 때 일어나는 데이터 엔지니어링의 핵심 사항
- 위의 연동 코드와 아키텍처가 실제 백엔드(MinIO 내부)에서 동작할 때 일어나는 데이터 엔지니어링의 핵심 사항
- 파이프라인의 데이터 파일 저장 흐름 (MinIO 내부의 실체)
table.append()가 호출되면 다음과 같은 연쇄 반응이 오브젝트 스토리지 내부에서 일어남- 데이터가 압축된
.parquet파일로 MinIO의data/경로에 먼저 안착 - 파이프라인은 이 파켓 파일의 컬럼별 통계 정보(예:
vibration_level의 최솟값/최댓값)를 뽑아서.avro포맷의 Manifest 파일로 저장 - 최종적으로 가상 데이터베이스 파일(iceberg_catalog.db) 원장에 “새로운 상태 포인터(.json 파일)”를 원자적(Atomic)으로 갱신 요청
- 데이터가 압축된
- Data Skipping (데이터 스키핑)을 통한 고속화 기술
- DuckDB 쿼리 엔진이
WHERE status = 'DANGER'를 요청할 때,- 일반 데이터 레이크는 MinIO에 있는 모든 파켓 파일을 다운로드해서 스캔해야 하므로 엄청난 I/O 비용이 듦
- Iceberg 파이프라인은
- Manifest 레이어의 통계 정보(Min/Max)만 먼저 스캔
status컬럼에 ‘DANGER’라는 단어가 포함될 가능성이 전혀 없는 파일들을 무더기로 걸러내고(Skipping),- 오직 해당 레코드가 있는 단 하나의 파켓 파일만 MinIO에서 콕 집어 가져옴
- 이것이 기가바이트(GB) 대역에서 수 밀리초(ms) 만에 SQL 처리가 끝나는 비결
- DuckDB 쿼리 엔진이
- 완벽한 데이터 엔지니어링 파이프라인의 혜택
- 무중단 스키마 진화:
- IoT 센서가 업그레이드되어 데이터 구조에 새로운 컬럼(예:
temperature)이 생기더라도, - 과거 파켓 파일을 단 하나도 건드리지 않고
- 카탈로그의 메타데이터만 갱신하여
- 신구 데이터를 즉시 병합해 냄
- IoT 센서가 업그레이드되어 데이터 구조에 새로운 컬럼(예:
- 배치 및 실시간 파이프라인의 조화:
- 쓰는 녀석(Ingestion)이 계속 뒤에서 파일을 밀어 넣고 있어도,
- 읽는 분석가(DuckDB)는 자기가 쿼리를 시작한 시점의 스냅샷만 바라보기 때문에
- “더러운 읽기(Dirty Read)” 현상이 완벽하게 예방
- 무중단 스키마 진화:
5. 예제의 목적
이 예제(PyIceberg + DuckDB + MinIO)를 통해 “무엇을 보고 확인하려는 것인가?” (Technical Proof)
- 눈으로 확인하는 것: “데이터와 메타데이터의 물리적 실체”
- 코드가 실행될 때 MinIO 버킷을 새로고침해 보면,
- 데이터 파일(
.parquet)이 저장되는 규칙과 - 메타데이터 파일(
.json,.avro)이 트리 구조로 저장되는 것을 확인
- 데이터 파일(
- 전통적인 하둡(Hive)처럼 ‘디렉터리’를 뒤지는 게 아니라,
- ‘임베디드 SQL 카탈로그 원장 안의 파일 포인터 스냅샷’을 통해 테이블이 관리되는 물리적 실체를 확인
- 코드가 실행될 때 MinIO 버킷을 새로고침해 보면,
- 트랜잭션 확인: “동시성과 불변성의 보장”
- Batch 1이 들어오고 Batch 2가 추가로 들어올 때,
- 기존 파일을 수정하거나 덮어쓰지 않고
- 완전한 새 파일이 독립적으로 생성되는 것을 확인
- 분석가가 쿼리를 던지는 도중(Read)에 새로운 데이터가 계속 인입(Write)되어도
- 쿼리가 깨지거나 오염되지 않는 ACID 트랜잭션을 눈으로 증명
- Batch 1이 들어오고 Batch 2가 추가로 들어올 때,
- 기능적 확인: “시간을 되돌리는 타임 트래블(Time Travel)”
- 파일 시스템(S3/MinIO) 환경에서 별도의 백업본을 만들지 않았음에도,
- 과거 스냅샷 ID를 파라미터로 던지는 것만으로 정확히 Batch 1 시점의 데이터(DANGER가 0건인 상태)로 되돌아가 조회되는 복원력 확인
- 파일 시스템(S3/MinIO) 환경에서 별도의 백업본을 만들지 않았음에도,
- 눈으로 확인하는 것: “데이터와 메타데이터의 물리적 실체”
이 예제는 결국 “어디에 쓰려고 하는 것인가?” (Business Use Cases)
대규모 분산 클러스터(Hadoop/Spark)를 띄우기엔 예산과 자원이 아까운 다양한 엔터프라이즈 환경에서 ‘가성비 DW(데이터 웨어하우스)’ 및 ‘AI 데이터 플랫폼’을 구축할 때 활용
- 스마트팩토리 및 IoT 실시간 모니터링 시스템
- 상황:
- 수백 대의 제조 설비, 센서에서 매초 수만 건의 텔레메트리(Vibration, Temperature) 로그가 쏟아짐
- 적용:
- 무겁고 비싼 관계형 DB(Oracle, MSSQL)에 이 로그를 다 넣으면 비용이 폭발하고 뻗어버림
- 이때 MinIO(저렴한 저장소) + Iceberg(고속 적재 및 인덱싱) 조합으로 파이프라인을 틀어쥐고,
- DuckDB로 대화형 현황 조회 및 대시보드를 구현
- 상황:
- 머신러닝(ML) 및 AI 모델의 학습 데이터 재현성(Reproducibility) 확보
- 상황:
- AI 모델을 학습시켰는데, 몇 달 후 성능이 떨어져서 “당시 학습했던 정확한 데이터셋”으로 재학습을 시켜야 하는 상황
- 그 사이 데이터는 계속 추가/변경됨
- 적용:
- Iceberg의 타임 트래블 기능을 사용하면,
- 수수께끼처럼 얽힌 파일들을 역추적할 필요 없이
snapshot_id='2026-03-01'형태로 지정하여 - 과거 특정 시점의 AI 학습 원천 데이터를 100% 완벽하게 재현해 낼 수 있음
- 수수께끼처럼 얽힌 파일들을 역추적할 필요 없이
- Iceberg의 타임 트래블 기능을 사용하면,
- 상황:
- 데이터 규제 준수 (GDPR, CCPA) 및 CDC 데이터 동기화
- 상황:
- “제 개인정보를 삭제해 주세요”라는 사용자의 요청이나,
- RDBMS의 변경 사항을 그대로 레이크에 반영(Upsert/Delete)해야 하는 상황
- 적용:
- 기존 데이터 레이크(단순 Parquet 저장)에서는 특정 행 하나를 지우려면 몇 기가바이트짜리 파일을 통째로 읽어서 지우고 다시 써야 함
- Iceberg의 Merge-on-Read(MoR) 전략을 쓰면
- 원본은 두고 ‘삭제 파일’만 살짝 얹으면 되므로,
- 오브젝트 스토리지 환경에서도 초고속 회원 탈퇴 처리 및 데이터 정정 파이프라인을 만들 수 있음
- 상황:
- 이 예제는
- 비싼 상용 데이터 웨어하우스(Snowflake, BigQuery 등)에 매달 수백~수천만 원의 비용을 지불하지 않고도,
- 내가 가진 로컬 서버나 프라이빗 클라우드(MinIO) 위에서
- 그에 준하는 초고속 RDBMS급 대용량 데이터 분석 인프라를 완전히 무료(오픈소스)로 자급자족하기 위한 주춧돌